






20201227
这个方法是在不改变数据内容的情况下,改变一个数组的格式,参数及返回值,官网介绍:

a:数组–需要处理的数据
newshape:新的格式–整数或整数数组,如(2,3)表示2行3列,新的形状应该与原来的形状兼容,即行数和列数相乘后等于a中元素的数量
order:
首先做出翻译:order : 可选范围为{‘C’, ‘F’, ‘A’}。使用索引顺序读取a的元素,并按照索引顺序将元素放到变换后的的数组中。如果不进行order参数的设置,默认参数为C。
(1)“C”指的是用类C写的读/索引顺序的元素,最后一个维度变化最快,第一个维度变化最慢。以二维数组为例,简单来讲就是横着读,横着写,优先读/写一行。
(2)“F”是指用FORTRAN类索引顺序读/写元素,最后一个维度变化最慢,第一个维度变化最快。竖着读,竖着写,优先读/写一列。注意,“C”和“F”选项不考虑底层数组的内存布局,只引用索引的顺序。
(3)“A”选项所生成的数组的效果与原数组a的数据存储方式有关,如果数据是按照FORTRAN存储的话,它的生成效果与”F“相同,否则与“C”相同。这里可能听起来有点模糊,下面会给出示例。
二、示例解释
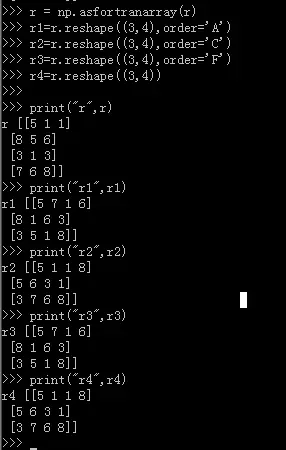
1、首先随机生成一个4行3列的数组
2、使用reshape,这里有两种使用方法,可以使用np.reshape(r,(-1,1),order=‘F’),也可以使用r1=r.reshape((-1,1),order=‘F’),这里我选择使用第二种方法。通过示例可以观察不同的order参数效果。


F 按列的顺序 先排列的元素
通过例子可以看出来,F是优先对列信息进行操作,而C是优先行信息操作。如果未对r的格式进行设置,那么我们rashape的时候以“A”的顺序进行order的话,它的效果和“C”相同。
3、我们将r的存储方式进行修改,修改为类Fortan的方式进行存储。并做与第2步类似的操作。
2.接下来创建一个数组a,可以看到这是一个一维的数组

3.使用reshape()方法来更改数组的形状,可以看到看数组d成为了一个二维数组

4.通过reshape生成的新数组和原始数组公用一个内存,也就是说,假如更改一个数组的元素,另一个数组也将发生改变

5.同理还可以得到一个三维数组

reshape(-1,1)什么意思:
大意是说,数组新的shape属性应该要与原来的配套,如果等于-1的话,那么Numpy会根据剩下的维度计算出数组的另外一个shape属性值。


只有-1的话 默认是展平成一维 与shape数值相同的行 是没有列的
shape表现为(xx,) 如果假设有一列的话应该是(xx,1) 但是又可以
直接当做有一列来操作 不必可以先转成有一列再进行其他操作
也就是说,先前我们不知道z的shape属性是多少,但是想让z变成只有一列,行数不知道多少,通过z.reshape(-1,1),Numpy自动计算出有12行,新的数组shape属性为(16, 1),与原来的(4, 4)配套。
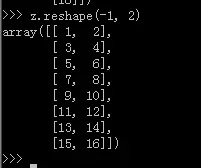
同理,只给定行数,newshape等于-1,Numpy也可以自动计算出新数组的列数。
https://www.jianshu.com/p/fc2fe026f002
20201202
import torch
a = torch.randn(3,5,2)
print(a)
print(a.view(-1))
tensor([[[-0.6887, 0.2203],
[-1.6103, -0.7423],
[ 0.3097, -2.9694],
[ 1.2073, -0.3370],
[-0.5506, 0.4753]],
[[-1.3605, 1.9303],
[-1.5382, -1.0865],
[-0.9208, -0.1754],
[ 0.1476, -0.8866],
[ 0.4519, 0.2771]],
[[ 0.6662, 1.1027],
[-0.0912, -0.6284],
[-1.0253, -0.3542],
[ 0.6909, -1.3905],
[-2.1140, 1.3426]]])
tensor([-0.6887, 0.2203, -1.6103, -0.7423, 0.3097, -2.9694, 1.2073, -0.3370,
-0.5506, 0.4753, -1.3605, 1.9303, -1.5382, -1.0865, -0.9208, -0.1754,
0.1476, -0.8866, 0.4519, 0.2771, 0.6662, 1.1027, -0.0912, -0.6284,
-1.0253, -0.3542, 0.6909, -1.3905, -2.1140, 1.3426])
结论
X.view(-1)中的-1本意是根据(剩下维度)来自动调整,但是这里只有一个维度,因此就会将X里面的所有维度数据转化成一维的,并且按先后顺序排列。
dataTar 形状为 [20,21]
dataTar = dataTar.view(20,-1)
原来的基础上加-1 是什么作用
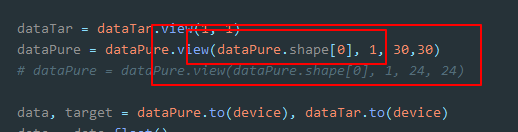
改成这种形状相当于 前面两位是 batch_size,通道数,后面两位相当于整个图片的元素
当元素总数只有比如768的时候,要开方的总数要和768一样,因为768不能完整开方,所以要padding
改成28x28
pytorch使用view(*args)在不改变张量数据的情况下随意改变张量的大小和形状

torch.Tensor.view会返回具有相同数据但大小不同的新张量。 返回的张量必须有与原张量相同的数据和相同数量的元素,但可以有不同的大小。一个张量必须是连续contiguous()的才能被查看。类似于Numpy的np.reshape()
pytorch中view的用法
torch.Tensor.view会将原有数据重新分配为一个新的张量,比如我们使用:
x = torch.randn(2, 4)会输出一个随机张量:
1.5600 -1.6180 -2.0366 2.7115
0.8415 -1.0103 -0.4793 1.5734
[torch.FloatTensor of size 2x4]然后我们看一下使用view重新构造一个Tensor
y = x.view(4,2)
print y
# 输出如下
1.5600 -1.6180
-2.0366 2.7115
0.8415 -1.0103
-0.4793 1.5734
[torch.FloatTensor of size 4x2]
从这里我们可以看出来他的作用,既然这样,我们可以将他变成一个三维数组:
z = x.view(2,2,2)
# 输出
(0 ,.,.) =
1.5600 -1.6180
-2.0366 2.7115
(1 ,.,.) =
0.8415 -1.0103
-0.4793 1.5734
[torch.FloatTensor of size 2x2x2]
注意:我们不能随便定义参数,需要根据自己的数据使用,比如x.view(2,2,1)会返回错误RuntimeError: invalid argument 2: size '[2 x 2 x 1]' is invalid for input of with 8 elements at /Users/soumith/code/builder/wheel/pytorch-src/torch/lib/TH/THStorage.c:41
下面是官方的案例:
x = torch.randn(4, 4)
print x
print x.size()
# 输出(4L, 4L)
y = x.view(16)
print y.size()
# 输出(16L,)
z = x.view(-1, 8) # the size -1 is inferred from other dimensions
print z.size()
# 输出(2L, 8L)
view_as(tensor)的用法
返回被视作与给定的tensor相同大小的原tensor。 等效于:
self.view(tensor.size())具体用法为:
a = torch.Tensor(2, 4)
b = a.view_as(torch.Tensor(4, 2))
print bpytorch中view的选择
.resize(): 将tensor的大小调整为指定的大小。如果元素个数比当前的内存大小大,就将底层存储大小调整为与新元素数目一致的大小。如果元素个数比当前内存小,则底层存储不会被改变。原来tensor中被保存下来的元素将保持不变,但新内存将不会被初始化。.permute(dims):将tensor的维度换位。具体可以自己测试torch.unsqueeze:返回一个新的张量,对输入的制定位置插入维度
相比之下,如果你想返回相同数量的元素,只是改变数组的形状推荐使用torch.view()
维度-1从其他维度推导而出也就是剩余的维度
20201210

原来是一个维度[20 ],view -1 变换之后增加了一个维度[20 1]

















 3013
3013











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









