






20210621
什么是关系事实,核心参考信息
实体提及:某个实体在不同句子中出现都叫提及
关系事实:就是具有真实关系的 实体对?
- 作者辛苦用人工标注的方式整理了目前最大的基于维基百科的文档级关系抽取数据集,实体和关系众多,跨多个域,并进行了当前有监督模型和无监督模型的测试。
- 数据的主要部分包含,实体,实体之间的关系和佐证这个实体之间关系的证据的句子。见图1示例。
- 作者讲述了数据集是如何制作出来的,通过知识库KB,命名实体识别,关系模型的提取的关系的参考,和人工的三轮标注制作而来。
- DocRED数据集的实体类型,关系类型,推理类型和句间关系都是比较复杂的。对于RE模型来说是相当大的考验。
- 作者分别对有监督和弱监督设置了Baseline,使用的模型包括2类CNN/LSTM/BiLSTM模型和Context-Aware模型,主要考虑的特征有GloVe词嵌入、实体类型嵌入和核心参考嵌入和dij和dji为文档中两个实体首次提及的相对距离特征。实体的表示是通过实体的单词范围和实体出现的次数的平均向量表示。实体之间的关系是是实体和实体间距离之后加个线性层分类后得到的,参见公式1。
- 作者考虑的特征包括整个文档的单词向量,每个单词的字符向量,但是代码中只考虑512个长度,2个实体的类型,2个实体的位置,2个实体的相对位置。
- 实验结果和人工表现对比,现有模型很难达到人工表现,差距很大,模型有很大提高潜力,主要在于现有模型不能很好的考虑多个句子间的全局上下文的信息。
一、简介
DocRED是不仅对实体句内关系进行构建,还对句间关系进行考虑。是基于Wikipedia和Wikidata构建的新数据集。具有以下三个特点。(1)DocRED同时对命名实体和关系进行标注,是最大的从纯文本中提取文档级RE的人工标注数据集;(2)DocRED需要阅读文档中的多个句子,通过综合文档的所有信息来提取实体并推断其关系;(3)除了人工标注的数据,还提供了大规模的远距离监督数据,这使得DocRED可以同时适用于监督和弱监督的场景。
关系抽取(relation extraction,RE)的任务是从纯文本中识别实体之间的关系事实,这在大规模知识图谱构建中起着重要作用。句子级RE关系和文档级关系,即多个句子间的关系相比,是有限制的。从维基百科文档中抽取的人类标注语料库的统计,至少有40.7%的关系事实只能从多个句子中抽取。例如图1,DocRED中的每个文档都被标注了命名实体提及、核心参考信息、句内和句间关系以及支持证据。在本例文档标注的19个关系实例中,有2个被呈现出来,这些实例中涉及的命名实体提及用蓝色标示,其他命名实体提及用下划线表示以示清晰。请注意,同一主题的提及(例如,Kungliga Hovkapellet和Royal Court Orchestra)在第一个关系实例中被识别。

图1:DocRED中的一个样本
DocRED是一个从Wikipedia和Wikidata构建的大规模人工标注的文档级RE数据集,具有以下三个特征。(1)DocRED包含132375个实体和56354个关系事实,标注在5,053个维基百科文档上,使其成为最大的人工标注文档级RE数据集。(2)由于DocRED中至少有40.7%的关系事实只能从多个句子中抽取,因此DocRED需要阅读文档中的多个句子来识别实体,并通过综合文档的所有信息来推理其关系。这使得DocRED区别于那些句子级的RE数据集,(3)还提供了大规模的远距离有监督数据来支持弱监督的RE研究。
二、 数据收集
人工标注数据分四个阶段收集。(1) 为维基百科文档生成远端有监督标注。
(2)对文档中的所有命名实体提及和核心参考信息进行标注。(3)将命名实体提及与Wikidata项目进行链接。(4)标注关系和相应的支持证据。
阶段1。远距离有监督注解生成,选择需要人工标注的文档。使用spaCy2进行命名实体识别。然后,将这些命名实体提及链接到Wikidata项目,将具有相同KB ID的命名实体提及进行合并。最后,通过查询Wikidata,对文档中每个合并的命名实体对之间的关系进行标注。包含少于128个单词的文档将被丢弃。丢弃包含少于4个实体或少于4个关系实例的文档,从而得到107,050个具有远端有监督标签的文档,随机选择5,053个文档和最频繁的96个关系进行人工标注。
阶段2:命名实体和引用标注。从文档中抽取关系需要首先识别命名实体的提及,并识别提及文档中相同实体的引用。为了提供高质量的命名实体提及和核心参考信息,我们要求人工标注者首先对第一阶段生成的命名实体提及提议进行审查、修正和补充,然后合并那些指向相同实体的不同提及,从而提供额外的核心参考信息。生成的中间语料包含各种命名实体类型,包括人、地点、组织、时间、数量和不属于上述类型的杂项实体名称。
阶段3:实体链接。在这一阶段,我们将每个命名的实体提及链接到多个Wikidata项目,为下一阶段提供远端监督的关系推荐。使用RE模型筛选出每篇文档推荐关系实例,要求标注者审查这些关系实例,删除不正确的关系实例,补充遗漏的关系实例。还要求标注者进一步选择所有支持保留关系实例的句子作为支持证据。最后57.2%来自实体链接的关系实例和48.2%来自RE模型的关系实例被保留。
三、 数据分析
在本节中,我们将对DocRED的各个方面进行分析,以便对数据集和文档级RE的任务有更深入的了解。
数据规模大,参见表1
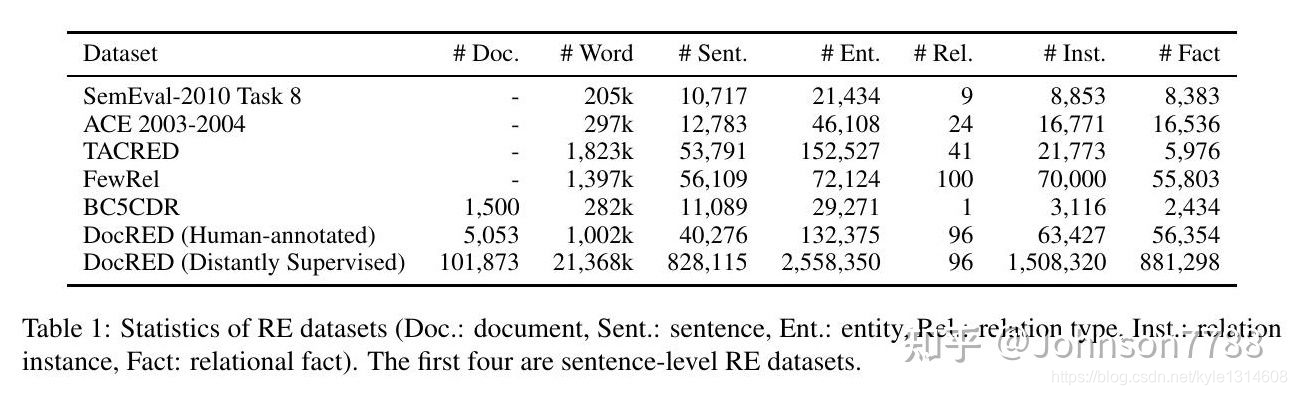
表1:RE数据集的统计(Doc.:文档,Sent.:句子,Ent.:实体,Rel.:关系类型,Inst.:关系实例,Fact:关系事实)。前四个是句子级RE数据集。
命名实体类型。DocRED涵盖各种实体类型,包括人(18.5%)、地点(30.9%)、组织(14.4%)、时间(15.8%)和数字(5.1%)。它还涵盖了不属于上述类型的各种杂项实体名称(15.2%),如事件、艺术工作和法律。每个实体平均被提及1.34次。
关系类型。我们的数据集包括96种来自Wikidata的频繁关系类型。我们数据集的一个显著特点是,关系类型涵盖了广泛的类别,包括与科学(33.3%)、艺术(11.5%)、时间(8.3%)、个人生活(4.2%)等相关的关系,这意味着关系事实不受任何特定领域的限制。此外,这些关系类型的组织结构层次分明、分类明确,可以为文档级RE系统提供丰富的信息。
推理类型。表2显示了我们数据集中主要推理类型的统计。从推理类型的统计中,我们有以下观察:(1)大部分关系实例(61.1%)需要通过推理来识别,只有38.9%的关系实例可以通过简单的模型识别来抽取,这说明推理对于文档级的RE是必不可少的。(2)在具有推理特征的关系实例中,大多数(26.6%)需要进行逻辑推理,即有关的两个实体之间的关系是由桥梁实体间接建立的。逻辑推理要求RE系统能够对多个实体之间的相互作用进行建模。(3)相当数量的关系实例(17.6%)需要进行核心参照推理,在这种情况下,必须先进行核心参照解析,以便在丰富的上下文中确定目标实体。(4)相似比例的关系实例(16.6%)需要基于常识推理进行识别,读者需要结合文档中的关系事实和常识来完成关系识别。综上所述,DocRED需要丰富的推理能力来综合文档的所有信息。

表2:DocRED上文档级RE所需的推理类型。剩余的0.3%需要其他类型的推理,如时间推理。
句间关系实例。我们发现,每个关系实例平均与1.6个支持句相关联,其中46.4%的关系实例与多个支持句相关联。此外,详细分析发现,40.7%的关系事实只能从多个句子中抽取,这说明DocRED是文档级RE的良好基准。我们也可以得出结论,阅读、综合和推理多个句子的能力是文档级RE所必需的。
四、基准设置
我们分别针对有监督和弱监督的场景设计了两个基准设置。两种设置使用的数据统计如表3所示。
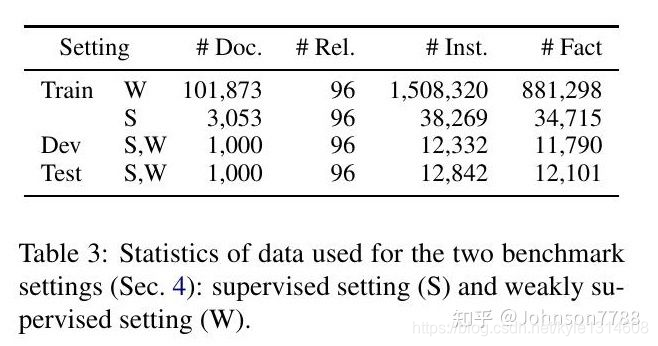
表3:两个基准设置(第4节)使用的数据统计:有监督设置(S)和弱监督设置(W)。
有监督设置。在这种设置中,只使用人工标注的数据,这些数据被随机分成训练集、开发集和测试集。有监督式设置给文档级RE系统带来了以下两个挑战。
第一个挑战来自于执行文档级RE所需要的丰富推理技能。如第3节所示,约61.1%的关系实例依赖于模型识别以外的复杂推理技能来提取,这就要求RE系统超越识别单句中的简单模式,对文档中的全局和复杂信息进行推理。
第二个挑战在于对长文档进行建模的高计算开销和文档中大量的潜在实体对,而文档中的实体数量是平方的(平均一个文档中19.5个实体)。
弱监督环境。这种设置与有监督的设置相同,只是将训练集换成了远距离有监督的数据(2.2节)。除了上述两个挑战之外,伴随着远距离监督数据不可避免的错误标签问题,也是弱监督环境下RE模型的一大挑战。
五、实验
在DocRED数据集上评估RE模型,还评估了人类的表现。并分析了不同支持证据类型的性能。此外,我们还进行了消融研究,以研究不同特征的贡献。
模型。分为2类模型,使用CNN/LSTM/BiLSTM模型和Context-Aware模型。
基于CNN/LSTM/BiLSTM的模型首先以CNN/LSTM/BiLSTM为编码器,将由n个词组成的文档 [公式] 编码成一个隐藏的状态向量序列 [公式] ,然后计算实体的表示,最后预测每个实体对的关系。
对于每个单词来说,输入编码器的特征是其GloVe词嵌入(Pennington等,2014)、实体类型嵌入和核心参考嵌入的拼接。实体类型是如PER、LOC、ORG,实体类型映射成向量,实体id被映也射成向量作为核心参考嵌入。
对于每个命名的实体提及mk,从第s个词到第t个词,我们将其定义为
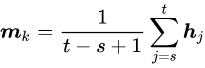
而具有K个提及的实体ei的表示是以这些提及的平均数来计算的:
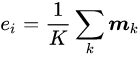
我们将关系预测作为一个多标签分类问题来处理。具体来说,对于每一个实体对(ei,ej),我们首先将实体表示与相对距离嵌入拼接起来,然后使用双线性函数计算每一种关系类型的概率:
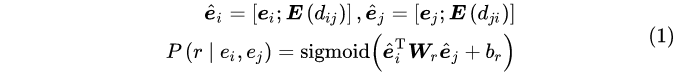
其中[;]表示拼接,dij和dji为文档中两个实体首次提及的相对距离,E为嵌入矩阵,r为关系类型,Wr、br为关系类型依赖的可训练参数。
评价指标。在我们的实验中使用了两个广泛使用的指标F1和AUC。然而,有些关系事实同时存在于训练集和开发/测试集中,因此模型在训练过程中可能会记住它们的关系,并以一种不可取的方式在开发/测试集上获得更好的性能,从而引入评价偏差。然而,训练集和开发集/测试集之间的关系事实的重叠是不可避免的,因为许多共同的关系事实可能在不同的文档中共享。因此,我们还报告了排除训练集和开发集/测试集共享的关系事实的F1和AUC得分,分别表示为IgnF1和IgnAUC。
模型性能。表4显示了监督和弱监督环境下的实验结果,从中我们有以下观察。(1)用人工标注数据训练的模型,其性能普遍优于用远端有监督数据训练的同类模型。这是因为虽然大规模的远端有监督数据可以很容易地通过远端有监督获得,但错误标注问题可能会损害RE系统的性能,这使得弱监督设置成为更困难的场景。(2)一个有趣的例外是,在远端有监督数据上训练的LSTM、BiLSTM和Context-Aware的F1 Score与在人工标注数据上训练的F1 Score相当,但在其他指标上的得分明显较低,这说明训练集和dev/test集之间的重叠实体对确实会造成评价偏差。因此,报告Ign F1和Ign AUC是必要的。(3)利用丰富的上下文信息的模型一般能获得更好的性能。LSTM和BiLSTM的表现优于CNN,表明在文档级RE中对长依赖语义建模的有效性。Context-Aware实现了具有竞争力的性能,然而,它不能显著优于其他神经模型。这说明在文档级RE中考虑多种关系的关联是有益的,而目前的模型不能很好地利用相互关系信息。
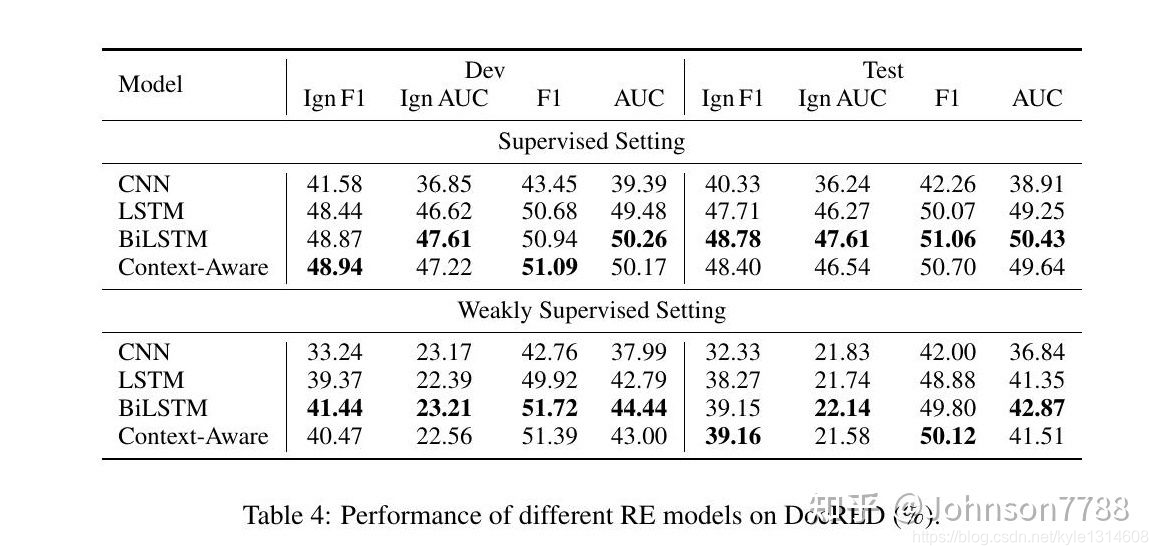
表4:不同RE模型在DocRED上的表现(%)。
人类的表现。表5显示了DocRED数据集上RE模型和人类的的表现在。人类在文档级RE任务(RE)和联合识别关系和支持证据任务(RE+Sup)上都取得了具有竞争力的结果,说明DocRED的上限性能和标注者之间的一致性都比较高。此外,RE模型的整体表现明显低于人类的表现,这说明文档级RE是一项具有挑战性的任务,也说明有充分的改进机会。
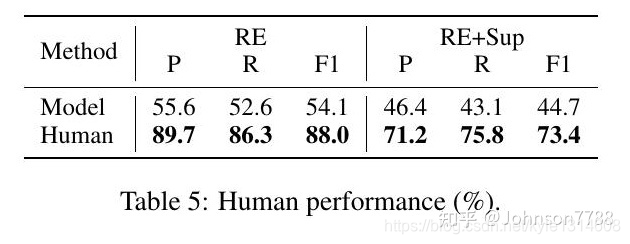
表5:人类表现(%)。
特征消融。我们对BiLSTM模型进行特征消融研究,研究不同特征在文档级RE中的贡献,包括实体类型、核心参考信息和实体之间的相对距离(Eq.1)。表6显示,上述特征都对性能有贡献。具体来说,实体类型由于其对可行关系类型的约束,贡献最大。核心参考信息和实体之间的相对距离对于从多个命名实体提及中综合信息也很重要。(重点)这表明,对于RE系统来说,利用文档层面的丰富信息是很重要的。
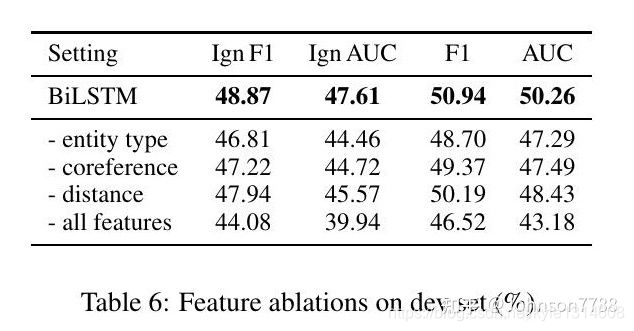
表6: 开发集上的特征消融(%)。
支持性证据预测。我们提出了一个新的任务来预测关系实例的支持证据。一方面,联合预测证据提供了更好的可解释性。另一方面,从文本中识别支持证据和推理关系事实是天然的双重任务,具有潜在的相互增强作用。我们设计了两种支持性证据预测方法。(1)启发式预测器。我们实现了一个简单的基于启发式的模型,将所有包含头部或尾部实体的句子视为支持证据。(2)神经预测器。给定一个实体对和一个预测关系,首先将句子通过词嵌入和位置嵌入的拼接转化为输入表示,然后输入BiLSTM编码器进行上下文表示。受Yang等人(2018)的启发,我们将BiLSTM在首尾位置的输出与可训练的关系嵌入进行并联,得到句子的表示,用于预测该句子是否被采纳为给定关系实例的支持证据。如表7所示,神经预测器在预测支持证据方面明显优于基于启发式的基线,这说明RE模型在联合关系和支持证据预测方面的潜力。

表7:F1 Score, 联合关系和支持证据预测的表现(%)。
讨论。通过以上实验结果和分析,我们可以得出这样的结论:文档级RE比句子级RE更具挑战性
七、结论
为了促进RE系统从句子级到文档级的发展,我们提出了DocRED,这是一个大规模的文档级RE数据集,它的特点是数据量大,对多个句子的阅读和推理的要求,以及提供的远端有监督数据,以促进弱监督文档级RE的发展。实验表明,人类的表现明显高于RE基线模型,这表明未来有充足的改进机会。
八、一条数据样本的格式
Data Format:
{
'title', 文章的标题
'sents': [
[句子0中的所有单词],
[word in sent 1]
]
'vertexSet': [
[
{ 'name': 实体提及的名字,即一个实体,
'sent_id': 实体在某个句子中出现,这个句子的id,
'pos': 实体在这个句子中的起始和结束位置,
'type': 实体的NER类型NER_type
}
{其它提及}
],
[其它实体]
'labels': [
{
'h': 第一个实体在vertexSet中的的索引位置
't': 第二个实体在vertexSet中的的索引位置,
'r': relation, 训练集中使用使用的是P6,代表的是rel_info.json中的"head of government",
'evidence': 支持证据的句子,支持这个关系的句子的id,支持2个实体的关系的佐证的句子
}
]
}
一条train_annotated.json的内容
{
"vertexSet": [
[
{
"pos": [
0,
4
],
"type": "ORG",
"sent_id": 0,
"name": "Zest Airways, Inc."
},
{
"sent_id": 0,
"type": "ORG",
"pos": [
10,
15
],
"name": "Asian Spirit and Zest Air"
},
{
"name": "AirAsia Zest",
"pos": [
6,
8
],
"sent_id": 0,
"type": "ORG"
},
{
"name": "AirAsia Zest",
"pos": [
19,
21
],
"sent_id": 6,
"type": "ORG"
}
],
[
{
"name": "Ninoy Aquino International Airport",
"pos": [
4,
8
],
"sent_id": 3,
"type": "LOC"
},
{
"name": "Ninoy Aquino International Airport",
"pos": [
26,
30
],
"sent_id": 0,
"type": "LOC"
}
],
[
{
"name": "Pasay City",
"pos": [
31,
33
],
"sent_id": 0,
"type": "LOC"
}
],
[
{
"name": "Metro Manila",
"pos": [
34,
36
],
"sent_id": 0,
"type": "LOC"
}
],
[
{
"name": "Philippines",
"pos": [
38,
39
],
"sent_id": 0,
"type": "LOC"
},
{
"name": "Philippines",
"pos": [
13,
14
],
"sent_id": 4,
"type": "LOC"
},
{
"sent_id": 5,
"type": "LOC",
"pos": [
25,
29
],
"name": "Republic of the Philippines"
}
],
[
{
"name": "Manila",
"pos": [
13,
14
],
"sent_id": 1,
"type": "LOC"
},
{
"name": "Manila",
"pos": [
9,
10
],
"sent_id": 3,
"type": "LOC"
}
],
[
{
"name": "Cebu",
"pos": [
15,
16
],
"sent_id": 1,
"type": "LOC"
}
],
[
{
"pos": [
17,
18
],
"type": "NUM",
"sent_id": 1,
"name": "24"
}
],
[
{
"pos": [
1,
2
],
"type": "TIME",
"sent_id": 2,
"name": "2013"
},
{
"pos": [
1,
5
],
"type": "TIME",
"sent_id": 5,
"name": "August 16, 2013"
}
],
[
{
"pos": [
9,
11
],
"type": "ORG",
"name": "Philippines AirAsia",
"sent_id": 2
}
],
[
{
"pos": [
5,
7
],
"type": "ORG",
"sent_id": 4,
"name": "Asian Spirit"
}
],
[
{
"pos": [
7,
13
],
"type": "ORG",
"sent_id": 5,
"name": "Civil Aviation Authority of the Philippines"
},
{
"name": "CAAP",
"pos": [
14,
15
],
"sent_id": 5,
"type": "ORG"
}
],
[
{
"name": "Zest Air",
"pos": [
34,
36
],
"sent_id": 5,
"type": "ORG"
},
{
"pos": [
7,
9
],
"type": "ORG",
"sent_id": 6,
"name": "Zest Air"
}
],
[
{
"sent_id": 6,
"type": "NUM",
"pos": [
2,
4
],
"name": "a year"
}
],
[
{
"name": "AirAsia",
"pos": [
5,
6
],
"sent_id": 6,
"type": "ORG"
}
],
[
{
"pos": [
5,
7
],
"type": "ORG",
"name": "AirAsia Philippines",
"sent_id": 7
}
],
[
{
"pos": [
8,
10
],
"type": "TIME",
"sent_id": 7,
"name": "January 2016"
}
]
],
"labels": [
{
"r": "P159",
"h": 0,
"t": 2,
"evidence": [
0
]
},
{
"r": "P17",
"h": 0,
"t": 4,
"evidence": [
2,
4,
7
]
},
{
"r": "P17",
"h": 12,
"t": 4,
"evidence": [
6,
7
]
},
{
"r": "P17",
"h": 2,
"t": 4,
"evidence": [
0
]
},
{
"r": "P131",
"h": 2,
"t": 3,
"evidence": [
0
]
},
{
"r": "P150",
"h": 4,
"t": 3,
"evidence": [
0
]
},
{
"r": "P17",
"h": 5,
"t": 4,
"evidence": [
0,
3
]
},
{
"r": "P150",
"h": 3,
"t": 2,
"evidence": [
0
]
},
{
"r": "P131",
"h": 3,
"t": 4,
"evidence": [
0,
3
]
},
{
"r": "P17",
"h": 3,
"t": 4,
"evidence": [
0,
3
]
},
{
"r": "P131",
"h": 1,
"t": 2,
"evidence": [
0,
3
]
},
{
"r": "P17",
"h": 1,
"t": 4,
"evidence": [
0,
3
]
},
{
"r": "P17",
"h": 10,
"t": 4,
"evidence": [
4
]
}
],
"title": "AirAsia Zest",
"sents": [
[
"Zest",
"Airways",
",",
"Inc.",
"operated",
"as",
"AirAsia",
"Zest",
"(",
"formerly",
"Asian",
"Spirit",
"and",
"Zest",
"Air",
")",
",",
"was",
"a",
"low",
"-",
"cost",
"airline",
"based",
"at",
"the",
"Ninoy",
"Aquino",
"International",
"Airport",
"in",
"Pasay",
"City",
",",
"Metro",
"Manila",
"in",
"the",
"Philippines",
"."
],
[
"It",
"operated",
"scheduled",
"domestic",
"and",
"international",
"tourist",
"services",
",",
"mainly",
"feeder",
"services",
"linking",
"Manila",
"and",
"Cebu",
"with",
"24",
"domestic",
"destinations",
"in",
"support",
"of",
"the",
"trunk",
"route",
"operations",
"of",
"other",
"airlines",
"."
],
[
"In",
"2013",
",",
"the",
"airline",
"became",
"an",
"affiliate",
"of",
"Philippines",
"AirAsia",
"operating",
"their",
"brand",
"separately",
"."
],
[
"Its",
"main",
"base",
"was",
"Ninoy",
"Aquino",
"International",
"Airport",
",",
"Manila",
"."
],
[
"The",
"airline",
"was",
"founded",
"as",
"Asian",
"Spirit",
",",
"the",
"first",
"airline",
"in",
"the",
"Philippines",
"to",
"be",
"run",
"as",
"a",
"cooperative",
"."
],
[
"On",
"August",
"16",
",",
"2013",
",",
"the",
"Civil",
"Aviation",
"Authority",
"of",
"the",
"Philippines",
"(",
"CAAP",
")",
",",
"the",
"regulating",
"body",
"of",
"the",
"Government",
"of",
"the",
"Republic",
"of",
"the",
"Philippines",
"for",
"civil",
"aviation",
",",
"suspended",
"Zest",
"Air",
"flights",
"until",
"further",
"notice",
"because",
"of",
"safety",
"issues",
"."
],
[
"Less",
"than",
"a",
"year",
"after",
"AirAsia",
"and",
"Zest",
"Air",
"\u0027s",
"strategic",
"alliance",
",",
"the",
"airline",
"has",
"been",
"rebranded",
"as",
"AirAsia",
"Zest",
"."
],
[
"The",
"airline",
"was",
"merged",
"into",
"AirAsia",
"Philippines",
"in",
"January",
"2016",
"."
]
]
}
原文: DocRED: A Large-Scale Document-Level Relation Extraction Dataset
作者: Yuan Yao1∗ , Deming Ye1∗
发布时间: 2019年8月\
代码: thunlp/DocRED


















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









