






20220722
select
*
from(
select b.ontime,a.*
from iceberg.ice_ods.ods_hz_erp_gxywmx_spark a
INNER join iceberg.ice_ods.ods_hz_erp_gxywhz_spark b
on a.djbh=b.djbh
)t1
where regexp_like(t1.djbh,'CGC')
and t1.rq in ('2022-07-20','2022-07-21')
trino代码写在python模块中的时候 用like '%CGC%'要报错
sql_ = "select spid from iceberg.onekey.ods_hz_onekey_spzl where dt in {} ".format(all_date)
{} 中括号站位元组值的时候,中括号两边是不加引号的 '{}'这样是不对的
TypeError: %c requires int or char
20220714
https://blog.csdn.net/a10534126/article/details/124336454
查看建表语句
20220326
https://blog.csdn.net/asing1elife/article/details/82788108
date_add
mysql8中文参考手册
G:\书籍\mysql8_refman_jb51\mysql8中文参考手册-latest200708
20220323
https://zhidao.baidu.com/question/107239190.html
order by 整数, 整数相当于列序号
20220320
 分析执行计划
分析执行计划

加速索引
20220303
update
pre_clean.jkzj_cd_infosp_jmd
set
pizwh_new = Null,
shangpgg_new =Null,
is_update = Null
更新某字段为空
20220302

save = ''
for i in rest_tongbutime:
save += "'"+i+"'"+","
save = save[:-1]
sql_count = """
SELECT
count(*)
FROM
JKZJ_SN_DUIJIE.dbo.infosp_jmd
where
tongbutime in ({})
""".format(save)
python构造sql的in形式
20220301
https://www.cnblogs.com/fengxiaojiu/p/7994124.html
sqlserver分页
select * from (
select *, ROW_NUMBER() OVER(Order by shangpid ) AS RowId from JKZJ_SN_DUIJIE.dbo.infosp_jmd
) as b
where RowId between 2 and 4
分页读取数据
写入数据库另一种方式
init_database = do()
engine = init_database.connect2database("sqlalchemy")
# 插入数据库
result_merge.to_sql(
name="tb_userdata_log_backup", con=engine, index=False, if_exists="append"
)
try_times = 4
for time in range(1, try_times):
logger.debug('第 {} 次向tb_userdata_log插入数据'.format(time))
con = engine.connect()
try:
con.execute(
"""UPDATE onekey.tb_userdata_log t1, onekey.tb_userdata_log_backup t2 SET t1.VendorNameStandard = t2.VendorNameStandard ,t1.VendorCode = t2.VendorCode, t1.VendorNameStandardUpdate = 1 WHERE t1.id = t2.id and t1.VendorNameStandardUpdate is null"""
)
con.execute("DROP TABLE if exists tb_userdata_log_backup")
except Exception as ee:
traceback.print_exc()
time.sleep(5)
else:
logger.debug('数据插入成功')
break
finally:
con.close()
20220215
https://zhidao.baidu.com/question/47721664.html
https://zhidao.baidu.com/question/98325731.html
各种更改的区别
20220106
with standard_name_engine.connect() as con:
con.execute('delete from tb_company_name where dt = %s' % dt)
代码中删除表中指定的内容
20211210
UPDATE
tb_userdata_log
SET VendorNameStandardUpdate = NULL
WHERE
DATE_FORMAT(create_time,'%Y-%m-%d' ) = '2021-12-09';
时间转字符
日期转字符
更新set只能一个字段一个字段的处理?
20211209
sql的-1值默认代表其他全部?
20211206
ALTER TABLE tb_userdata_log DROP COLUMN VendorNameStandardUpdate;
mysql删除列操作
ALTER TABLE tb_userdata_log
ADD COLUMN VendorNameStandard VARCHAR(150);
mysql更改列类型操作
CREATE TABLE tb_userdata_log_test (SELECT * FROM tb_userdata_log);
CREATE TABLE tb_userdata_log_test LIKE tb_userdata_log;
INSERT INTO tb_userdata_log_test SELECT *FROM tb_userdata_log;
mysql读取一张表的内容形成新的表
https://www.cnblogs.com/jhy-ocean/p/5560857.html
https://blog.kieng.cn/1396.html
字符转timestamp
mysql string转timestamp
20211022
date_format(rq,'%Y-%m-%d')='2021-10-22'
日期转字符
https://blog.csdn.net/u010711495/article/details/112290966
字符转日期trino

sql规范 前半括号紧跟关键字,case when 也有 else

后半括号和as表别名放一行,最后的多个括号放一行
20211021
if 写一句的话相比case when不灵活,因为条件里面还可以嵌套子句
规范
不管层数 表的别名从上往下开始命令
t1,t2…
原价 成本 数量
1 2 3
1 NULL 2
2 3 4
有空值的情况下,每一行先算原价乘以数量和成本乘以数量
然后求列的总原价再减去列的总成本得到的总利润
和 sum(原价-成本价)*数量的结果是一样的?
select (1-null)*2=null
20211014
https://blog.csdn.net/caoxiaohong1005/article/details/69228592
if语句
https://blog.csdn.net/dwt1415403329/article/details/87835383
https://www.cnblogs.com/huangchuxian/p/7808051.html
groupby和partitionby区别

partitionby保留所有的列且新建一列每一行的值都一样而不像groupby
20211007
https://blog.csdn.net/weixin_37610397/article/details/79955256
sqlserver练习语句
20210830
https://blog.csdn.net/qq_35531549/article/details/90379760
分组concat 的presto
20210827
select
id,
"type"
from
ztdata_hive.ods_hz_tb_user_info
where
unique_id is not null
and id is not null
and unique_id !=''
and contact_person not like '%test%'
and name not like '%测试%'
and "type" is not null
and length ("type") <2
and "type" !='0'
and "type"!=''
and id not in ('61','3442','5204669','10247','59297','5209803','5208541') order by id desc;
mysql字段两种为空的情况
关联之前要做到事情
1.其中一个表的关联字段要无重复
2.排查掉test,null 等情况
20210823
https://www.icode9.com/content-2-180154.html
hivesql 创建表
https://blog.csdn.net/qq_44509920/article/details/103192349
hivesql数据类型
alter table address modify column city varchar(50);
修改字段类型
sql 游标入库的时候就是算是字符
而表定义的为其他类型的时候 其会自动推断
而入库为数据库表定义的格式
https://blog.csdn.net/u010159842/article/details/73245007
hivesql 更改表名
ALTER table tb_yaopjb2 rename to tb_yaopjb
有id的情况下,相对要去重的字段分组取最小的id,
然后只取这些id就行了
select * from 表名 group by 根据哪一个字段(简称字段) having count(字段) > 1
分组处理 前面select 不可能是星号 而是具体某些字段
https://blog.csdn.net/wx1528159409/article/details/88027551
hivesql 语句
https://www.cnblogs.com/wxy0126/p/11137529.html
mysql对表中数据根据某一字段去重
https://blog.csdn.net/u010002184/article/details/89605768
hive查询结果写入新表
使用MySQL中,在一张表etl_table_field_info上新增了一个字段tgt_table_en_name,该字段的值想从表etl_table_property_info的tgt_table_en_name获取。更新时的关联关系是字段src_table_en_name值相等。
SQL如下:
UPDATE etl_table_field_info f, etl_table_property_info p
set f.tgt_table_en_name=p.tgt_table_en_name
where f.src_table_en_name=p.src_table_en_name
MySQL使用一张表的一列更新另一张表的一列
sql语法: UPDATE 表名 SET 字段名=replace(字段名, ‘被替换字符串’, '用来替换的字符串') ;
-- 替换字段中部分字符
-- UPDATE `member` SET `phone`=replace(`phone`, '\'', '') ;
这是列中每个单元格的值都整体替换
https://blog.csdn.net/cyn_653620/article/details/76750689
索引位置替换

SELECT
REPLACE(img,SUBSTRING(img,LOCATE('h_',img),4),'h_280') re
FROM tmp
重点 变相实现部分每行的部分字符串都替换
create table tmp (select * from tb_product_spyder_info where rq='2021-08-22' and company_id=2 limit 20)
复制另一张表的部分内容
20210407
1、内关联([inner] join):只返回关联上的结果
https://ask.csdn.net/questions/384439
Sql 两表横向拼接
更改列名
alter table t_contract_billterm_record
change bill_start_date bill_start_date2 date NOT NULL DEFAULT '0000-00-00' COMMENT '账单开始时间';
20210312
sql_query = '''
SELECT A.ipo, A.normal, A.relation, C.feature ipo_feature, B.feature normal_feature
FROM matchmatrix_1 A, general_company B, ipo_company C
WHERE A.normal= B.name and A.ipo = C.name and A.remark=%s order by A.normal, A.relation desc '''
多表连接是在连接之后的结果 做筛选 这里的 A.remark=%s
20210305
select qymc,‘华为’ from table
形成一列相同值的数据
函数貌似只能使用与select 语句和 where 语句中
alter table rank_test_match_item
modify id int(11) auto_increment primary key
-- add 增加新的,modify 在已经存在的上面更改
alter table rank_test_match_item
add primary key (id)
更改字段信息
alter table 表名 modify 字段名 字段类型 after 字段
举例
alter table user_info modify user_name varchar(10) after user_id;
将user_name字段移到user_id后面
如果想移到最前面:
alter table user_info modify user_id char(8) first;//将user_id移到最前面!!
修改列顺序
update rank_item_with_neg A set dataset ='train' where exists (select 1 from vw_batch B where A.batch_no=B.batch_no and A.item = B.item and B.s1 >0 and B.s2 > 0) and A.remark <60
select 1 选择为真的
exists 后面还可以再加 and 判断
https://www.cnblogs.com/aigeileshei/p/6729204.html
https://www.cnblogs.com/ruhaoren/p/12810130.html
mysql编程 第二个重点
conv(left(md5(normal),4), 16,10) % 100
哈希把一个非重集合分成100份 很平均的100份
https://blog.csdn.net/geming2017/article/details/84256843
conv
数字基数 就是2 进制,16进制这些吧 上面的意思16进制转换为10进制数
SELECT A.ipo, A.normal, A.relation, C.feature ipo_feature, B.feature normal_feature
FROM rank_item_with_neg_ A , general_company B, ipo_company C
WHERE A.normal= B.name and A.ipo = C.name and A.remark=%s order by A.normal, A.relation desc
这种直接查询和关联的区别是 上面是一对一查询 关联大部分时候存在 一对多的情况
而且可以直接查询关联几个表
#居然可以在selete 部分用条件判断语句
select item,batch_no,sum(case when relation=1 then 1 else 0 end) as s1, sum(case when relation=0 then 1 else 0 end) as s2 from rank_item_with_neg where remark < 60 group by item,batch_no;
update rank_item_with_neg set dataset =null where dataset ='test'
另外通过建立视图和临时表都可以保存中间过程
但是肯定临时表最好用
#case when 换成 if 语句
select item,batch_no,sum(if(relation=1,1,0)) as s1 from tmp group by item,batch_no
只能是这种二值的形式
20210303
https://blog.csdn.net/qq_26754531/article/details/78963514
sql跨服务器复制
20210225
https://blog.csdn.net/running_nz/article/details/53501832
modify 和 change
modify比change简便
https://www.runoob.com/sql/sql-quickref.html
sql快速参考语句
https://www.cnblogs.com/vincentvoid/p/6433085.html
查询结果赋值给变量
https://www.cnblogs.com/geaozhang/p/9891338.html
sql prepare 预处理 预编译
https://www.cnblogs.com/myseries/p/10821372.html
sql注入
https://www.runoob.com/sql/func-date-add.html
菜鸟教程
https://www.w3school.com.cn/sql/sql_distinct.asp
w3scool
https://blog.csdn.net/pan_junbiao/article/details/86489237
事件:相当于触发器

drop procedure sp_var_into;
没有后面的括号调用
删除存储过程
delimiter ##
create procedure sp_var_into()
begin
declare ename varchar(32) default 'unknow';
declare eid int default 0;
select e.id,e.name into eid,ename from examplee_copy1 e;
select eid,ename;
end ##
call sp_var_into();
创建存储过程只运行上面
调用存储过程 下面没有 procedure 关键字
replace into 和 insert on update的区别
https://blog.csdn.net/newchitu/article/details/87861880
having也是筛选的作用

join 两个表的所有字段都要保留 重复的字段只是起了个别名
SELECT a.*,b.* FROM examplee a LEFT JOIN examplee b ON a.sex=b.sex AND a.age<b.age
这个分组取也不太对
left join 左边的表的条目数是要变的 如果右边有多条记录满足要求的话
right join 类似 而不是 被join的表条目保持不变
想象部分结果呈现而不是 全部
#前的字段可以传入后面的子句中
SELECT * FROM examplee a WHERE 2> (SELECT COUNT(*) FROM examplee WHERE sex=a.sex and age>a.age) ORDER BY a.sex,a.age DESC;
前面的成分可以传到后面的语句中
这个分组取不太对
https://www.cnblogs.com/qlqwjy/p/8036076.html
mysql 按中文排序
SELECT d.Name AS Department, e1.Name AS Employee, e1.Salary
FROM Employee e1 JOIN Department d ON e1.DepartmentId = d.Id
WHERE
#工资级别数量小于等于3,即最多只有3个工资级别,也就是前三高
3 >= (SELECT COUNT(DISTINCT e2.Salary) FROM Employee e2 WHERE
#e2的工资级别大于等于e1的工资级别
e2.Salary >= e1.Salary AND e1.DepartmentId = e2.DepartmentId)
ORDER BY e1.DepartmentId,e1.Salary desc;
分组取前面N组
数据插入数据库的时候
replace into
update set
insert into
三者的区别?
replace 和 replace 都需要指定where 条件?
insert into 不需要
replce在主键重复的时候可以写入 但只写入一条
insert into 在主键重复的时候不能写入
20210224
https://www.jianshu.com/p/f68da9510066
https://blog.csdn.net/czh500/article/details/100873759
随机抽取语句
现在需要将表B中的user字段值根据表A中的username换成usercode.
实现:
UPDATE B,A SET B.user= A.usercode WHERE B.user= A.username;
1 update tinfo2 set tinfo2.remark = tinfo1.remark
from tinfo1 inner join tinfo2 on tinfo1.name = tinfo2.name
update表bai1 set 表1 修改列=表2 赋值字段du;
from表2 where表1 关联字段=表2 关联字段。zhi
update department_copy1 a, department b set a.d_name=concat(a.name,b.d_name) where a.d_name=b.d_name;
重点 根据每行的值来对应
根据一张表的内容修改另一张表
``
20210224
https://www.cnblogs.com/awake-insist/articles/7156035.html
sql contains
https://www.cnblogs.com/wxlhyg/p/9046343.html
CHARINDEX:查某字符(串)是否包含在其他字符串中,返回字符串中指定表达式的起始位置。
PATINDEX:查某字符(串)是否包含在其他字符串中,返回指定表达式中某模式第一次出现的起始位置;如果在全部有效的文本和字符数据类型中没有找到该模式,则返回零。从1开始下标(两者的区别在于,后者支持模糊匹配,前者是全匹配)
like:查询部分字符是否存在
contains:查询完整字符是否存在
其他两个求索引
update rank_test_match_copy2 set status=‘01’,rank=0;
同时改变多列的值
20210222
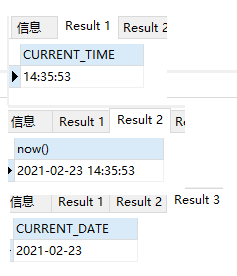
不同的时间
利用md5进行哈希
conv(left(md5('你好吗'),4))%10
有问题
select * from examplee e
where exists (
select name from department d where e.id=d.id );
最终找出examplee表中 id 存在于 department表中id
对应的记录
20210220
https://blog.csdn.net/kyle1314608/article/details/113889853
sql理解
20210208
numpy 写入数据库
aa=np.array([1,2,3])
aa=aa.tostring()
20210121
一、bai功能上的区别
1、Alter:修改表结构
例如:
增加表的字段
Alter table test Add(id,int).
alter table
onekey_bi.tb_onekey_goods_info_manual_match
add remarks_status int default null comment '对码方法,0:算法规则'
2、UPdate:修改表数据
例如:
修改字段id列的值
update test set id=2;
二、本质上的区别
1、Alter是数据定义语言(Data difinition Language),在修改表的结构时,不需要Commit和Rollback。
2、Update是数据数据操作语言(Data manipulation Language),在修改数据值时,需要Commit和Rollback,否则提交的结构无效。
alter和update的区别

where:对表和视图限制查询条件,having:对分组后结果信息进行筛选
where 和having的区别
heidisql


系统本身的关键词为 蓝色 类型为红色 其他自定义新增的为灰色
已有的表是粉色
sql语句的理解 先看关联主干的结果 再看关联的 and 条件
先看一个关联的结果 再看下一个关联的结果
不断的嵌套 先做主干 再加上其他条件
SELECT st.*,sc.sscore AS ‘语文’,sc2.sscore ‘数学’
FROM student st
LEFT JOIN score sc ON sc.sid=st.sid AND sc.cid=‘01’
LEFT JOIN score sc2 ON sc2.sid=st.sid AND sc2.cid=‘02’
WHERE sc.sscore>sc2.sscore
and 在关联的 on 语句后面
where 在整个语句的后面
https://www.runoob.com/mysql/mysql-database-export.html
MySQL 教程
https://www.cnblogs.com/zsty/p/10109125.html
sql高频练习题
can not connect to mysql 10061
在服务里面启动 mysql80 对应版本即可
####################################################################
####################################################################
#pandas写入数据库
from sqlalchemy import create_engine
import pandas as pd
import numpy as np
import time
import os
import pandas.io.sql as psql
class write_to_sql_pandas():
#全量读取
def init(self):
# def init(self, user, pwd, ip, port, db_name):
self.user = 'luckycat'
self.pwd = 'bigdata'
self.ip = '10.0.6.13'
self.port = '3306'
self.db_name = 'luckycat'
def write_to_sql(self,table_name):
time1 = time.time()
os.environ["NLS_LANG"] = "GERMAN_GERMANY.UTF8"
engine_utf8= create_engine("mysql+mysqlconnector://" + self.user + ":" + self.pwd + "@" + self.ip + ":" + self.port + "/" + self.db_name,encoding='utf-8')
engine_gbk= create_engine("mysql+mysqlconnector://" + self.user + ":" + self.pwd + "@" + self.ip + ":" + self.port + "/" + self.db_name,encoding='gbk')
table_name.to_sql('ipoqy_product_jyfw_jg',engine_gbk,if_exists='append',index=False,chunksize=1000)
time2=time.time()
print('写入时间 {0}'.format(round((time2-time1)/60),2))
#pandas写入数据库
####################################################################
pandas 写入数据库要乱码 因为无法定制写入编码 可以先写入 然后删除内容之后
在追加写入
20210119
select qymc, GROUP_CONCAT(product order by product desc SEPARATOR ‘;’) product ,jyfw,textb from ipoqy_product_jyfw group by qymc,jyfw,textb;
https://baijiahao.baidu.com/s?id=1595349117525189591&wfr=spider&for=pc
20210113
https://blog.csdn.net/weixin_45986454/article/details/107005997
CREATE table ipo_product_output_layer_all (SELECT chain_match.ipoqy_product.qymc,chain_match.ipoqy_product.product, luckycat.ipo_jyfw_outputlayer.output_layer_jyfw from chain_match.ipoqy_product left JOIN luckycat.ipo_jyfw_outputlayer on chain_match.ipoqy_product.qymc=luckycat.ipo_jyfw_outputlayer.qymc
不同库表的关联及结果保存
)
mysql 保存查询结果
20210112
mysql支持多个库中不同表的关联查询,你可以随便链接一个数据库
然后,sql语句为
select * from db1.table1 left join db2.table2 on db1.table1.id = db2.table2.id
只要用数据库名加上"."就能调用相应数据库的数据表了.
数据库名.表名
#--------------------所有企业得分数据插入到mysql---------------------
insert_data = []
for i in range(total_data.shape[0]):
insert_data.append(tuple(str(j) for j in np.array(total_data.iloc[i, :]).tolist()))
def insert_defen(data):
try:
conn = trzs.connect()
cursor = conn.cursor()
sql_insert = "replace into t_trzs_enterprises_score(qybm, monthno, gm, czx, kfx, total, insert_time) values(%s,%s,%s,%s,%s,%s,now())"
for i in range(len(data) // 1000 + 1):
cursor.executemany(sql_insert, data[1000 * i:1000 * (i + 1)]) # 这里需要进行批量数据插入,每次插1000条!
conn.commit()
except connector.Error as e:
print(e)
finally:
cursor.close()
conn.close()
20210104
https://www.cnblogs.com/bugstar/p/8512666.html
myslq 存储过程
```cpp
MySQL获取某个表的列名
DESC TableName
SHOW COLUMNS FROM TableName
SELECT COLUMN_NAME FROM information_schema.columns WHERE table_name='tablename' #这个方法会多出两列什么情况
20201229
对有重复数据的表可以先插入自增列作为索引之后再和其他数据进行关联
总体:sql 就是一层一层的嵌套查询 可以分步骤的进行,先调试各个嵌套子查询的意思 再结合起来看
alter table sample_gyl20201221_copy add column id int(14) primary key auto_increment
ALTER TABLE ipoqy_product_jyfw ADD COLUMN textb VARCHAR (512);
后面的分号 是英文状态下
类型后面要加长度 且加括号
新增自增列
delete from sample_gyl20201221_copy
where company_a in (select * from (select company_a from sample_gyl20201221_copy group by company_a having count(company_a) > 1) b)
and id not in (select * from (select min(id) from sample_gyl20201221_copy group by company_a having count(company_a )>1) c)
单个字段 count 里面应该是错的 应该用 星号 *
delete from sample_gyl20201221_copy
where (company_a,company_b,upstream_flag,downstream_flag,s) in (select * from (select company_a,company_b,upstream_flag,downstream_flag,s from sample_gyl20201221_copy group by company_a,company_b,upstream_flag,downstream_flag,s having count(*) > 1) b)
and id not in (select * from (select min(id) from sample_gyl20201221_copy group by company_a,company_b,upstream_flag,downstream_flag,s having count(*)>1) c)

前面有括号 后面count 用星号 对剩余的列进行统计
以多个字段为标准删除重复项
20201217
https://www.cnblogs.com/jiguang321/p/11548884.html
mysql 插入
INSERT INTO company_match_tag_copy (company_a,company_b) SELECT company_a,company_b FROM supplychain
选择一个表的部分字段插入另一张表
tagging_tasks=[(1,1,0.123,0.234,1)]
sql_update = "update company_match_tag set status='10',upstream_flag=%s,downstream_flag=%s,upstream_prob=%s,downstream_prob=%s where id=%s and status='11' "
传入参数的顺序要和语句中的变量顺序相同
update company_match_tag set upstream_flag=0,downstream_flag=0,upstream_prob=0.1,downstream_prob=0.2 where id=1
sql 更新部分字段
set 后面是对所有的字段进行处理 而不是仅仅对第一个 upstream_flag 处理
navicat中常用快捷键总结
– 快捷键
– Ctrl + / 快速注释 Ctrl + shift + / 解除注释
– Ctrl + q 快速建立查询页面
– Ctrl + R 快速执行
– 每个sql依;结束可以多行一起运行
– 每个sql依;结束可以多行一起运行
– 快速打开表结构
– Ctrl+l快速删除一行
cursor.execute(sql_query, [(batch_size)])
cursor.executemany(sql_update, locking_tasks)
下面是一次处理多条
传入的数据格式为 比如 locking_tasks
[(列1,列2,列3…)] 一个列表里面包一个元组,元组里面是每个例的值
SET是SQL Server 中对已经定义的bai变量赋值的du方式,经常zhi与update语句一起使用。
语法:daoUPDATE 表名称 SET 列名zhuan称 = 新值 WHERE 列名称 = 某值
例子shu如下:
update A set name=小张 where name =张三 //将小张的姓名改为张三
update A set name=小王 where name =王五 //将小王的姓名改为王五


sql 传入变量

在navicat中查看表的对应创建语句
20201216
https://blog.csdn.net/kyle1314608/article/details/111300314
复制表
20201215
https://database.51cto.com/art/201009/228254.htm
delete from vitae a
where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1)
and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1)
根据标准统计个数 取出个数大于1个的 取行索引最小的那个
删除重复记录
select upstreamflag,downstreamflag,count(*) from supplychain group by upstreamflag,downstreamflag
按列分组统计 计数
20201211
insert into t_wz_kc(wzid,jldwid,kcsl,yfpkcsl,cshwcbz) select wzid,jldwid,0,0,'Y' from t_wz_wz where yxbz='Y'
--去重复
-- and wzid not in (select wzid from t_wz_kc)
把一张表的内容插入另一张表
sql读出来的数据部分数据转换能成功但是全部转换不成功 说明里面有部分值是空或者其他
异常
sql读出非空值
select name from clase where address != null
这样的话查询语句不会报错,但是永远不会有可用的选项
SQL中要想实现这个功能有另外一个表达的方式
用下面这个
select name from clase where address IS NOT NULL
20200722
navicat中常用快捷键总结
– 快捷键
– Ctrl + / 快速注释 Ctrl + shift + / 解除注释
– Ctrl + q 快速建立查询页面
– Ctrl + R 快速执行
– 每个sql依;结束可以多行一起运行
– 每个sql依;结束可以多行一起运行
– 快速打开表结构
– Ctrl+l快速删除一行
https://www.cnblogs.com/xingyadian/p/9056269.html
sqlserver查询所有表名和字段名
select * from sysobjects where xtype=‘U’ order by name
得到表名
SELECT * FROM INFORMATION_SCHEMA.TABLES order by table_name
得到表名
SELECT * FROM INFORMATION_SCHEMA.COLUMNS order by table_name
得到表名和字段
20200608

sql in 后面跟的是圆括号 而不是 列表


这里填错就会报上面的错误

‘clob’ 单引号是不行的 最后表现语句里面是变量而不是字符
要作为字符放到语句里面 外面还要加双引号“‘clob’ ”
20200603
mysql语句
创建副本
create table bwpz_beihao_copy as(select * from bwpz_beihao);
删除表数据,保留结构
delete from bwpz_beihao_copy;
直接删除表
Drop table bwpz_beihao_copy;
更改表名
alter table data_final_3_beihao rename to data_merged_3_beihao;
多表同时连接
“select
t1.taobao_commodity_id as id,
t2.outer_id as spu,
t1.date,
t2.category_id as cls1,
t1.pv,
t1.uv ,
t1.payment_amount as salesAmt,
t1.payment_number as salesQty,
t2.cost,
t2.tag_price as mktPrice,
r1.store_id
from
t_abby_commodity_day t1,
t_commodity t2,
r_taobao_store_commodity r1
where
t1.taobao_commodity_id = r1.taobao_id
and t1.store_id = r1.store_id
and r1.commodity_id=t2.id”
远程指定ip和port 登陆
mysql -h 10.8.1.10 -P 13306 -u wangshiyang -p
Port 是大写的P

https://www.cnblogs.com/zzqc/p/9192217.html
8.0改变了身份验证插件,改成使用老版本的身份验证插件方式就好了。
cd “C:\Program Files\MySQL\MySQL Server 8.0\bin”
C:\Program Files\MySQL\MySQL Server 8.0\bin> mysql -u root -p
Enter password: *********
mysql> ALTER USER ‘root’@‘localhost’ IDENTIFIED WITH mysql_native_password BY ‘newrootpassword’;
Query OK, 0 rows affected (0.10 sec)
mysql> exit
https://blog.csdn.net/davidchengx/article/details/75912013
Navicat 导入导出
user=“wsy”
pwd=“1234”
ip=“127.0.0.1”
db_name=“adam”
port=“3306”
Ip 的localhost 不能放到引号里面 直接用用localhost不要引号
从navicat 里面导出txt的时候的选项 只要 栏位分割符选择逗号就可以了
20200520
https://blog.csdn.net/iteye_12724/article/details/82549582
oracle 的sql语句查看指定用户下表的数量,查看当前登陆用户表数量

注意这里的选项
数据库表划分
- 比如用户表 用户的信息
2.交易表 同一个东西 出库 入库信息
3.统计表 不是很重要 在基本表上面做的统计?
4.参考表 相当于把用户表里面的部分字段信息 单独存为了一个表 通过 一个共有字段进行关联
20200518


在sql语句中加单引号
oracle 查看字段类型
SELECT table_name, column_name, data_type FROM all_tab_cols WHERE table_name = 'tablename ';
20200403
oracle
select * from all_tables where owner=‘TEST’
TEST为用户名,用户名必须是大写。
查看当前登录的用户的表:
select table_name from user_tables
查某个表的所有内容
select child_sign_rate from SOURCE_DATA.RPT_SIGN_PEOPLE
20200306
不能指定索引区间取值 只能把前面的一切取出来
select height from WDCHIS.CDM_CHD_VISITS_BAK where rownum>1000
rownum 只能<= 不能>
20200305 oracle
选择
select blood_pressure_am_1 from CZ_ZJHIS.YZ_NURSE where blood_pressure_am_1 > 0;
按SHIFT+ESC快捷键可停止
















 368
368

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









