






20230413
df.where(df != ‘其它’)
所有元素都筛选
20221109
https://noxymgr5yr.feishu.cn/docx/Bw0VdIHTMomMWZxXu4fcf1BQnGi
两列转成字典
20221107
temp_df['vector_a'] = str(mga_df_copy['vector'].iloc[index].tolist())
temp_df['vector_a'] = temp_df['vector_a'].apply(lambda x: eval(x))
数组要赋值给pandas某列,先转成列表再转成字符串再转成列表
20221107
map_dict = {True:1,False:0}
ga['is_nhi_name_a'] = ga['is_nhi_name_a'].map(map_dict)
字典多值映射更改
20221102
temp_df['not_key_words_a'] = str(general_df_copy['not_key_words_a'].iloc[index])
temp_df['key_words_a'] = str(general_df_copy['key_words_a'].iloc[index])
temp_df['not_key_words_a'] = temp_df['not_key_words_a'].apply(lambda x:eval(x))
temp_df['key_words_a'] = temp_df['key_words_a'].apply(lambda x:eval(x))
dataframe列值赋值为列表,可以先转成字符串,然后再用eval转成列表
20221012
filter.columns =[[
'image_name', 'x0', 'y0', 'x1', 'y1','y_min', 'y_max', 'width',
'height', 'total_width','total_height', 'total_width_ratio',
'total_height_ratio','total_width_ratio_outlier',
'total_height_ratio_outlier', 'x_min','x_max', 'x_min_ratio',
'x_max_ratio', 'horizontal'
]]
这样是生成多维索引
column = filter.columns
column = column.levels[0].tolist()
多维数组通过level参数取出需要的一层
def density(x,y0_set,y_threshold):
for i1 in range(x.shape[0]):
x.iloc[i1] = len([ i for i in y0_set if abs(x.iloc[i1] - i) < y_threshold])
return x
print(i1)
if i1 == '12.png':
filter['density'] = filter['y0'].apply(lambda x:density(x,y0_set,y_threshold))
filter['y0'].apply 传入的是series,牵扯到集合的时候,需要每个值单独遍历处理
当是多维索引的时候,filter['y0']取出的是dataframe,而非多维索引的时候,取出的是一个值
y0_set = filter.iloc[:,2].tolist()
y0_set = filter['y0'].tolist(),这一种居然不行了,现在提取出来的对象居然是dataframe了
20221010
def test(x):
x['sort'] = range(x.shape[0])
return x
rs = rs.groupby('name_a').apply(lambda x:test(x))
分组的万能公式,x是dataframe,通过dataframe的规则来处理
返回的也是dataframe
https://blog.csdn.net/leokingszx/article/details/103774406
分组排序
rs = rs.groupby('name_a').apply(lambda x:x.sort_values(['similarity', 'name_quantity', 'other_char'],ascending=[False, False, True]))
groupby之后lambda里面仍按正常的dataframe操作进行处理
分组transform的作用只能是聚合操作,针对具体的值,每行给出新值不行
20221007
https://blog.csdn.net/kyle1314608/article/details/111213976
删除含空值百分比的行
https://blog.csdn.net/weixin_45852947/article/details/119453881
删除全为空的行和列
df = df.dropna(axis=1,thresh=1.)
阈值设定为浮点数1.这表示全部,整数为具体的个数
https://blog.csdn.net/p1306252/article/details/114880994
替换dataframe中具体的某个所有值
20220928
temp_all.loc[temp_all['id'].isnull(),'id'] = ''
temp_all.loc[temp_all['id'] == '','id'] = None
遇到dataframe中出现nan无法写入数据库的时候,先复制为'',再复制为None就可以了
https://blog.csdn.net/qq_29410215/article/details/125764727
dataframe转dict
20220819
df = pd.DataFrame({'a':[1,2,3]})
aa = df.shape[0]
bb = df['a'].iloc[2:3]
bb.iloc[0]
取出series数据
20220817
https://blog.csdn.net/W_H_M_2018/article/details/105295142
timedelta
数据库中的null,从来没有过的值
对应dataframe的 nan?非字符,通过 isnull()可提取
20220708
pd.cut:分段函数
https://zhuanlan.zhihu.com/p/467388987
pandas时间戳转日期
20220606
sorted(name for name in networks.__dict__
if name.islower() and not name.startswith("__")
and callable(networks.__dict__[name]))
列表生成式多条件
20220531
from pandas.io.json import json_normalize
import pandas as pd
import json
方法一:利用read_json进行转化
data_str = open('movies.json').read()
df = pd.read_json(data_str,orient = 'records')
df.head()
方法二: 利用json.loads和json_normalize进行转化
data_str = open('movies.json').read()
data_list = json.loads(data_str)
df_1 = json_normalize(data_list)
df_1.head()
方法三:利用json.loads和pd.DataFrame进行转化
data_str = open('movies.json').read()
data_list = json.loads(data_str)
## d['title']中的'title'是自己json格式文件里面的names
data = [[d['title'],d['score'],d['quote'],d['comment_num']] for d in data_list]
df_2 = pd.DataFrame(data,columns = ['title','score','quote','comment_num'])
df_2.head()
json转dataframe
import pandas as pd
#方法一:直接在创建DataFrame时设置index即可
dict = {'a':1,'b':2,'c':3}
data = pd.DataFrame(dict,index=[0])
print(data)
#方法二:通过from_dict函数将value为标称变量的字典转换为DataFrame对象
dict = {'a':1,'b':2,'c':3}
data = pd.DataFrame.from_dict(dict,orient='index').T#
print(data)
#方法三:输入字典时不要让Value为标称属性,把Value转换为list对象再传入即可
dict = {'a':[1],'b':[2],'c':[3]}
data = pd.DataFrame(dict)
print(data)
json转dataframe
20220530
https://qa.1r1g.com/sf/ask/2183626861/?lastactivity
pandas读取多字符串分隔符
20220516
rank["rank"] = rank.groupby("key", as_index=False)["date_time_ms"].rank(ascending=False)
ascending为什么会相反,True的时候是降序排列
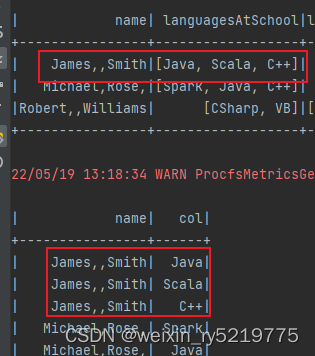
explode宽行变长列
空值 ‘’ 显示为一片空白
空值 None 显示也是 None
20220507
range(begin,end,step)
‘null’
字符串 ‘null’ ,pandas自动识别为None
20220429
ari['date_time_ms'] = pd.to_datetime(ari['date_time_ms'])
转换成时间格式之后,如果毫秒部分为零的话,则会消失
但是从csv重新读取之后,000又会出现
gp = al.groupby(['key','date_time'])
temp_al = pd.DataFrame({},columns=al.columns)
for key,value in gp:
same_num = value['group_num'].iloc[0]
if same_num != 1:
millisecond_list = np.random.randint(100,10001,same_num)
millisecond_list.sort()
value['millisecond'] = millisecond_list
temp_al = pd.concat([temp_al,millisecond_list],axis=0)
else:
temp_al = pd.concat([temp_al,value],axis=0)
temp_al
分组源数据进行处理
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
没写清楚索引 直接 series或dataframe和一个数值进行比较操作
比如 df['a'] != 1 正确写法是 df['a'].iloc[index]!=1
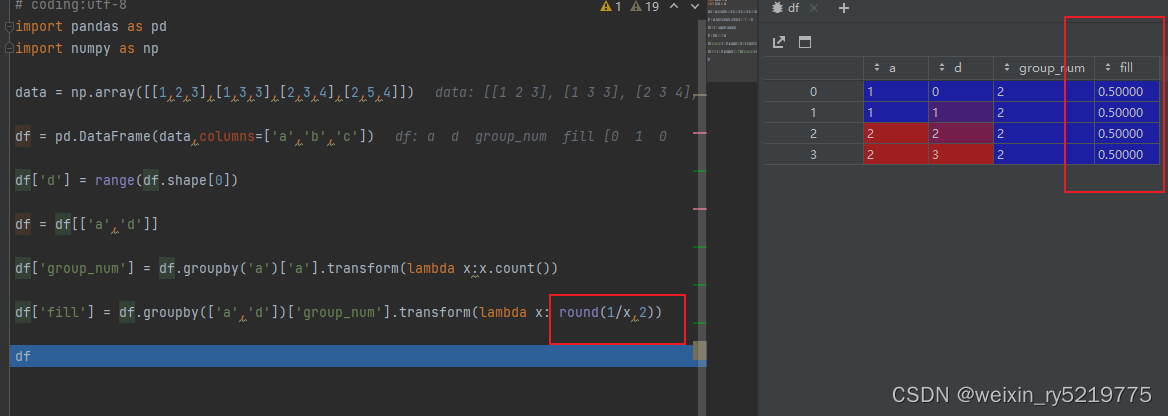
这样可以分组填充均值
groupby transform
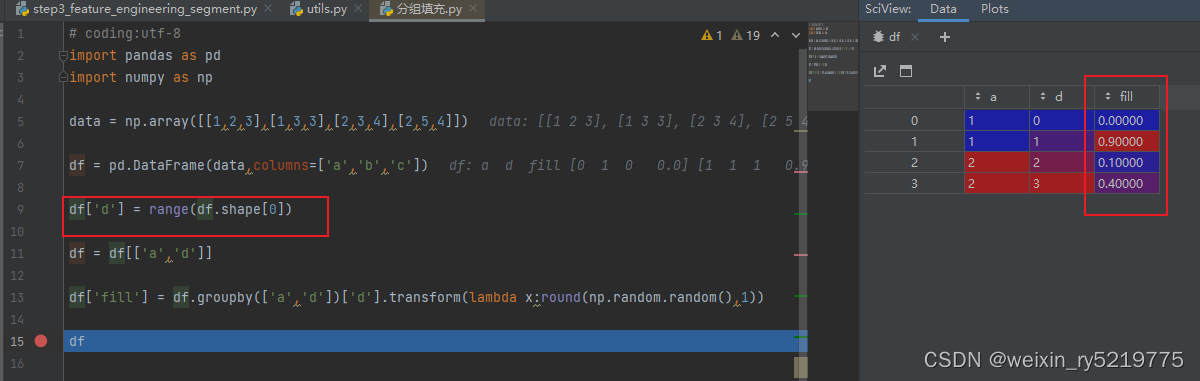
要实现对分组之后每一行对应取不同的值,可以新增一列,其所有行的取值都不同相同
分组时候把其也列入其中,然后针对每行进行赋值
groupby transform
https://blog.csdn.net/feizxiang3/article/details/93380525
nunique() Return number of unique elements in the object.即返回的是唯一值的个数
20220426
np.std(se) / np.mean(se)
计算变异系数
标准差就是方差的平方根
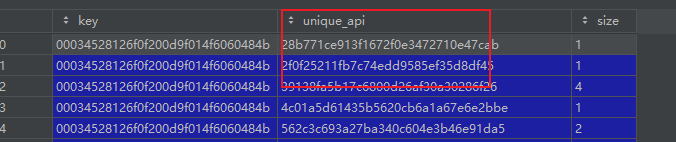
group = vf.groupby(['key','unique_api'],as_index=False)['unique_api'].size()
groupby,size和count,size会保留unique_api列,而count不会
20220421
直接groupby比用transform要快很多,减少了不少的记录
https://blog.csdn.net/qq_36148333/article/details/114481253
groupby size(),count()区别
groupby,as_index=False 分组的列被作为一列,而不是作为行索引
20220420
https://blog.csdn.net/jingyi130705008/article/details/87882977
一列拆分成多列
20220330
print(frame3.isnull().any())
找出存在空值的列
print("========================")
print(frame3.isnull().T.any())
找出存在空值的行

20220323
per_image = il['image_name_only'].iloc[i] + '.' + il['image_type'].iloc[i]
numpy.core._exceptions.UFuncTypeError: ufunc 'add' did not contain a loop with signature matching types (dtype('int64'), dtype('<U1')) -> None
https://blog.csdn.net/ztf312/article/details/79419553
https://blog.csdn.net/Caiqiudan/article/details/107915149
取值映射
20220307
https://blog.csdn.net/kyle1314608/article/details/100589526
dataframe构建新建
20220223
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any()
group['diff'].iloc[i][0] < 0:
要这样写 group['diff'].iloc[i] < 0: 这样是不行的
20220218
data_not1['length_num'] = data_not1.groupby(['license_no','length'])['length'].transform(lambda x:x.count())
统计分组后的个数
是否在数据处理前后都要剔除?
null_type = ['nan',None,'']
for i in null_type:
result_merge.loc[result_merge[col_type] == i, 'right_label_complete'] = '无'
result_merge.loc[result_merge[col_type] == i, 'vendor_code_complete'] = -2
result_merge.loc[result_merge[col_type].isnull(), 'right_label_complete'] = '无'
result_merge.loc[result_merge[col_type].isnull(), 'vendor_code_complete'] = -2
20220126
数字中出现多个点号的处理
dd['price'] = dd['price'].astype(str)
dd['first_dot'] = dd['price'].apply(lambda x:x.index('.'))
dd['price'] = dd.apply(lambda x:x['price'][0:x['first_dot']+5],axis=1)
dd['price'] = dd['price'].astype(float)
dd['price'] = dd['price'].apply(lambda x:round(x,4))
del dd['first_dot']
20220111
ValueError: Cannot index with multidimensional key
存在名字相同的两列
ValueError: Length mismatch: Expected axis has 18 elements, new values have 17 elements
很可能是列名之间没写逗号
https://blog.csdn.net/qq_22238533/article/details/70917102
随机打乱
dataframe对一列全部元素进行处理并赋值给每一行
直接令一新列等于(函数处理后的结果就行了)
20220111
# 创建一个空的 DataFrame
df_empty = pd.DataFrame()
#或者
df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D'])
#添加数据
a为一个新的dataframe
df_empty = df_empty.append(a)
https://www.pythonheidong.com/blog/article/59300/a379e1720f1dd2a2e635/
df1 = pd.DataFrame([[11, 12], [21, 22]], columns=['c1', 'c2'], index=['i1', 'i2'])
pd.DataFrame().reindex_like(df1)
Out:
c1 c2
i1 NaN NaN
i2 NaN NaN
#第三种
df.drop(df.index, inplace=True)
df=df.drop(index=df.index)
# 第四种
total_data = pd.DataFrame([])
20220110
df['lagprice'] = df['price'].shift(1)
求滞后阶
shift(1)
上面的记录往下面移动
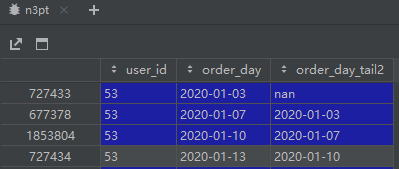
n3pt['order_day_tail2'] = n3pt.groupby('user_id')['order_day'].shift(1).bfill()
bfill() 向后填充 相当于求最后一条时间间隔的值会为0
这样的bfill填充方式是错误的,没有分组
```python
```python
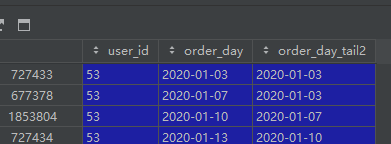
n3pt['order_day_tail2'] = n3pt.groupby('user_id')['order_day'].shift(1).fillna(method='bfill')
这种分组填充方式才是正确的
bfill向后,向上填充 和shift的1正值方向是相反的

20220426 不管那种写法都会把不同的组的值填充到其他组的空值上面
最好是先留空,再操作一步按自己的意愿来填充
分组填充应该只适合对一列中一组值都相同,但是有空缺的情况
al['total_avg_second'] = al.groupby(['key','date_time'])['total_avg_second'].fillna(method='bfill')
同一组的分组填充
20220109
n3pa['order_day_purchase_amount'] = n3pa.groupby(['user_id','order_day'])['real_purchase_amount'].transform(lambda x:sum(x))
transform不能同时groupby两个以上的列?
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.core.groupby.GroupBy.tail.html
df.groupby('A').tail(1)
uo_30_days = uo.loc[((uo['order_day'] >= last_30_date) & (uo['order_day'] < current_date)),:]
uo_30_days = uo.loc[((uo['order_day'] >= last_30_date) and (uo['order_day'] < current_date)),:]
and 和 & 是不一样的 and在这里会报错
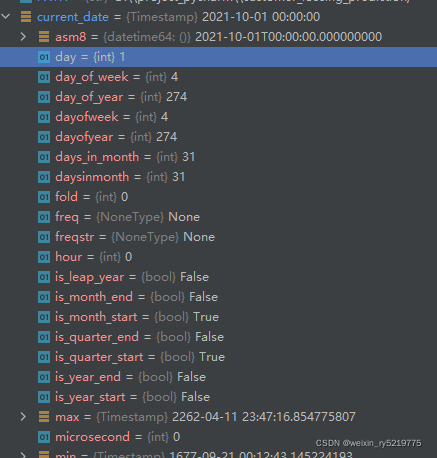
timestamp得到day天
timestamp提取日期部分
timesstamp.date()
20220108
weekDate_dict=retdata.groupby('weekid')['dateWeek'].max().to_dict()
retdata['dateWeek']=retdata['weekid'].map(weekDate_dict)
字典映射
20220107
od['customer_type'] = ''
def decide_customer_type(x):
if (x['r'] < x['r_mean']) and (x['f'] > x['f_mean']) and (x['m'] > x['m_mean']) :
x['customer_type'] = 1
elif (x['r'] < x['r_mean']) and (x['f'] < x['f_mean']) and (x['m'] > x['m_mean']):
x['customer_type'] = 2
elif (x['r'] > x['r_mean']) and (x['f'] > x['f_mean']) and (x['m'] > x['m_mean']):
x['customer_type'] = 3
elif (x['r'] > x['r_mean']) and (x['f'] < x['f_mean']) and (x['m'] > x['m_mean']):
x['customer_type'] = 4
else:
x['customer_type'] = 5
return x
od = od.apply(lambda x:decide_customer_type(x),axis=1)
多条件多列同时处理
axis=1 对每一行进行循环处理
axis=0 对每一列进行循环处理
1行 一行
凌冽的寒风
20211228
python利用pandas读取csv报错:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xc8...解决方法
另存为utf8无签名
https://mp.weixin.qq.com/s/bWyBWrFkp_zunazLWhsIzw
100个pandas函数
20211224
train = np.zeros((train_x.shape[0], 1))
test = np.zeros((test_x.shape[0], 1))
test_pre = np.empty((folds, test_x.shape[0], 1))
构建空的numpy矩阵
x_train = np.float_(get_matrix(np.float_(x_train)))
y_train = np.int_(y_train)
numpy数值类型转换
x_train = all_data_test[~all_data_test['label'].isna()][features_columns].values
通过一列来筛选出多列
where_are_nan = np.isnan(data)
where_are_inf = np.isinf(data)
data[where_are_nan] = 0
data[where_are_inf] = 0
找出空值和无限大的值
df[行索引名称,列索引名称] 通过行列索引名称直接取值
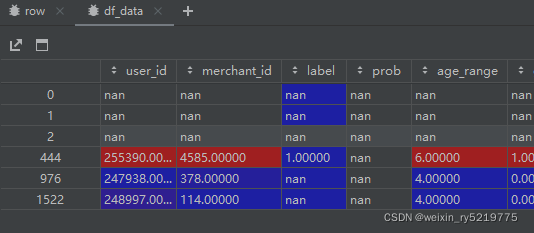
for index, row in df_data.iterrows()
index为行索引,row为整行的值也就是一行作为一个series
而不是列
20211223
print(train_data.merchant_id.value_counts().head(5))
计算多列的值个数
train_data.copy()
pandas深度复制
merchant_repeat_buy = [ rate for rate in train_data.groupby(['merchant_id'])['label'].mean() if rate <= 1 and rate > 0]
列表解析结合if忽略else的写法
user_info[user_info['age_range'].isna() | (user_info['age_range'] == 0)].count()
每一列计数
user_info.groupby(['age_range'])[['user_id']].count()
分组计数
user_log.isna().sum()
所有列空值计数
list_join_func = lambda x: " ".join([str(i) for i in x])
agg_dict = {
'item_id' : list_join_func,
'cat_id' : list_join_func,
'seller_id' : list_join_func,
'brand_id' : list_join_func,
'time_stamp' : list_join_func,
'action_type' : list_join_func
}
rename_dict = {
'item_id' : 'item_path',
'cat_id' : 'cat_path',
'seller_id' : 'seller_path',
'brand_id' : 'brand_path',
'time_stamp' : 'time_stamp_path',
'action_type' : 'action_type_path'
df_data = df_data. \
groupby(join_columns). \
agg(agg_dict). \
reset_index(). \
rename(columns=rename_dict)
分组后对每列的每组值分别处理
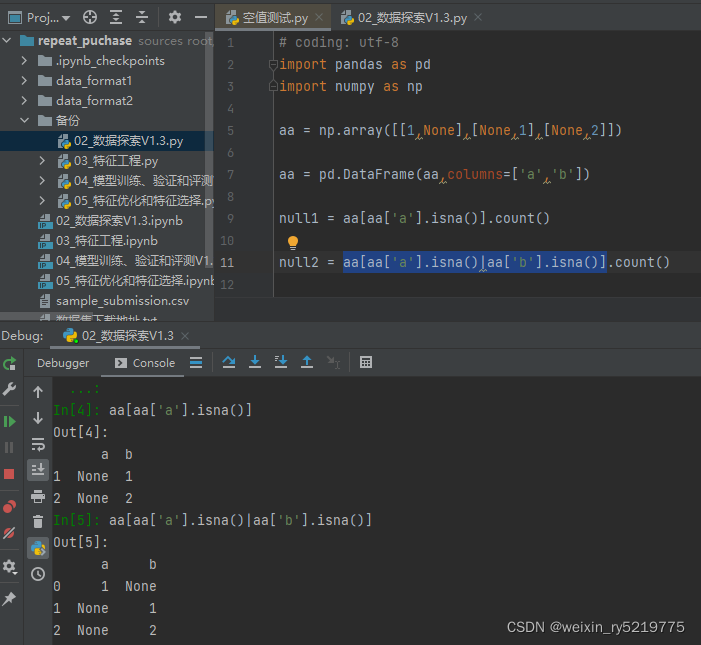
count非空值统计
null1对筛选出a列为空所对应的所有列
null2对筛选出的a或b为空所对应的所有列
20211222
base_data['dateid'] = base_data['dateid'].apply(lambda x: x.to_pydatetime())
timestamp转datetime
时间戳转日期
https://www.cnblogs.com/qingyuanjushi/p/9255003.html
20211220
to_csv(header=False)
而不是None写None会导致追加到最后一行
的同一行而不是最后一行的下一行
光标放在最后才能正确追加?
20211206
索引-1为最后一列的索引位置
20211202
dataframe要交换两列只需要交换两列的列名就可以了
20211201
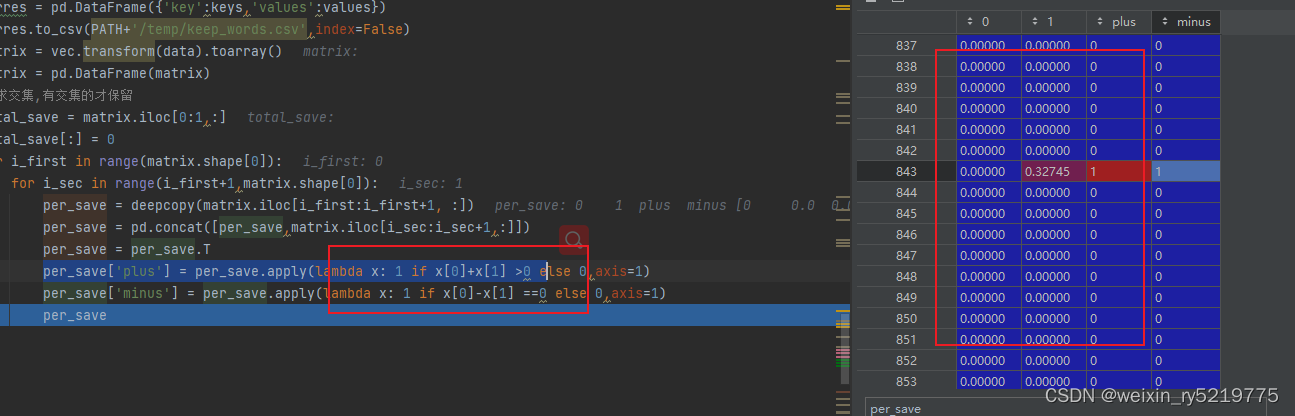
lambda对多列进行操作
重点筛选的时候不能用具体的列名比如 x[‘plus’] 只能用相对索引
x[0] …x[n]??
axis = 1 是每一行中的元素进行处理
axis =0 是每一列中的元素进行处理
多列多条件筛选的时候用lambda写个单独的函数
20211111
https://blog.csdn.net/happy_wealthy/article/details/108576944
dropna详解
https://www.cnblogs.com/traditional/p/13776180.html
rolling和shift的区别
rolling是滚动连续计算,shift是直接值在不同位置上的移动
https://blog.csdn.net/jingyi130705008/article/details/114882758
Python-pandas:分组后每组均值填充均值
aa = ret[['goods_id','mean_quantity_week_last_year']]
aa['mean_quantity_week_last_year'] = aa.groupby('goods_id').transform(lambda x:x.fillna(method='bfill'))
只能一列对一列 两列进行处理?
ValueError: Columns must be same length as key
onekey_matched['min_price'] = onekey_matched.groupby('商品id')['原价'].transform(lambda x:min(x))
transform功能无限扩展
https://blog.csdn.net/liuchengzimozigreat/article/details/91417347
多列同时填充均值

滚动求和之后对缺失值填充
bfill填充表下方向的值
20211105
列名出现圆括号 (xxx,)是因为外面多嵌了一层中括号
standardize_cols = [[xxx,xxx]]应该只有一层括号
X_train = pd.DataFrame(X_train,columns=standardize_cols)
https://blog.csdn.net/weixin_38753213/article/details/113622748
transform详细使用,全面使用
groupby只会在存在的数据中进行交叉
比如某个id 之后 1,2,3号有数据则通过这两个字段进行分组
不会把别的id的4号也交叉进来
def group_avg(x):
return np.average(x)
dd['total_quantity'] = dd.groupby(['goods_id','order_date'])['quantity'].transform('sum')
dd['average_price'] = dd.groupby (['goods_id','order_date'])['price'].transform(group_avg)
重点
dd.drop ( upper[0], inplace=True )
按行索引删除记录
dd["date"] = pd.to_datetime(dd["date"])
字符转日期
20211103
pre_gp = base_data.groupby(['catagory_level2', 'goods_id', 'weekid']) # 分组聚合
pre_pd = pre_gp[['dateid', 'year_num', 'month_num', 'week_num']].last()
pre_pd = pre_gp[['dateid']].min()
分组后可对一个或多个字段进行处理
```python
pre_gp = base_data.groupby(['catagory_level2', 'goods_id', 'weekid']) # 分组聚合
pre_pd = pre_gp[['dateid', 'year_num', 'month_num', 'week_num']].last()
取每一分组的最后一行数据
goods_not_gjm = goods_not_gjm.dropna(subset=['商品名称','批准文号','规格'],how='any',axis=0)
axis=0 对应subset为列索引 删除对应列里面有空的值
但是如果空值是字符串 'nan' 则无效
axis=1 对应sbuset为行索引
cols=[ i for i in cols if not i.endswith('_y')]
cols=[ re.sub('_x','',i) if i.endswith('_x') else i for i in cols ]
if和for紧挨,如果有else 在二者中间
列表解析
20211101
goods_notnull = goods.loc[goods['国家码']!='nan',:]
如果空值是字符而不是数字
goods_onek=goods_onek.loc[goods_onek['条形码'] != '*',:]
排除星号
https://zhuanlan.zhihu.com/p/100064394?utm_source=wechat_session
map:对某列元素进行字典映射
apply:对一列数据单个元素进行复杂的函数处理
另外apply 也可以对行进行操作 axis=0
以及多行进行操作 比如 apply(lambda x: x[0]+x[1],axis=1)
applymap:对dataframe所有元素进行函数处理
https://blog.csdn.net/weixin_39791387/article/details/81487549
字典映射修改某列的值
# turn NaN scores with 0 reviews into 'No Reviews'
idx_vals = data['review_scores_rating'][data['number_of_reviews'] == 0].index.values.tolist()
data.loc[idx_vals, ('review_scores_rating')] = data['review_scores_rating'][data['number_of_reviews'] == 0].replace('NaN', 'No Reviews')
根据一行的情况处理某一行对应的一些值
# determine the number of missing entries in each column
for col in data.columns:
print col + ', Number of Missing Values:', len(data[col][data[col].isnull()])

缺失值统计
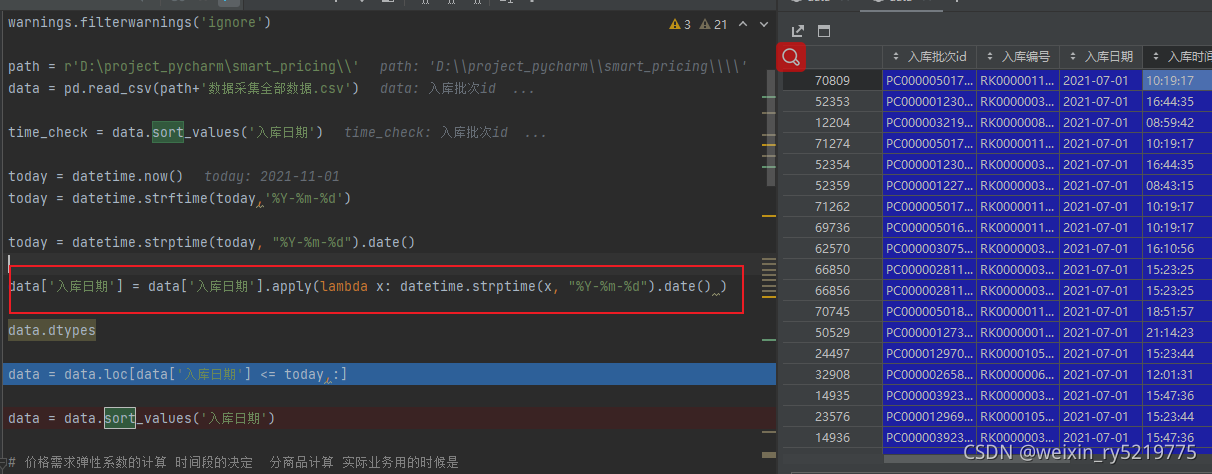
data['入库日期'] = data['入库日期'].apply(lambda x: datetime.strptime(x, "%Y-%m-%d").date() )
字符列转日期
text = '2018-11-21'
a = datetime.strptime(text, "%Y-%m-%d").date()
b = datetime.today().date()
https://www.jianshu.com/p/fa2d84dc2447
字符转日期
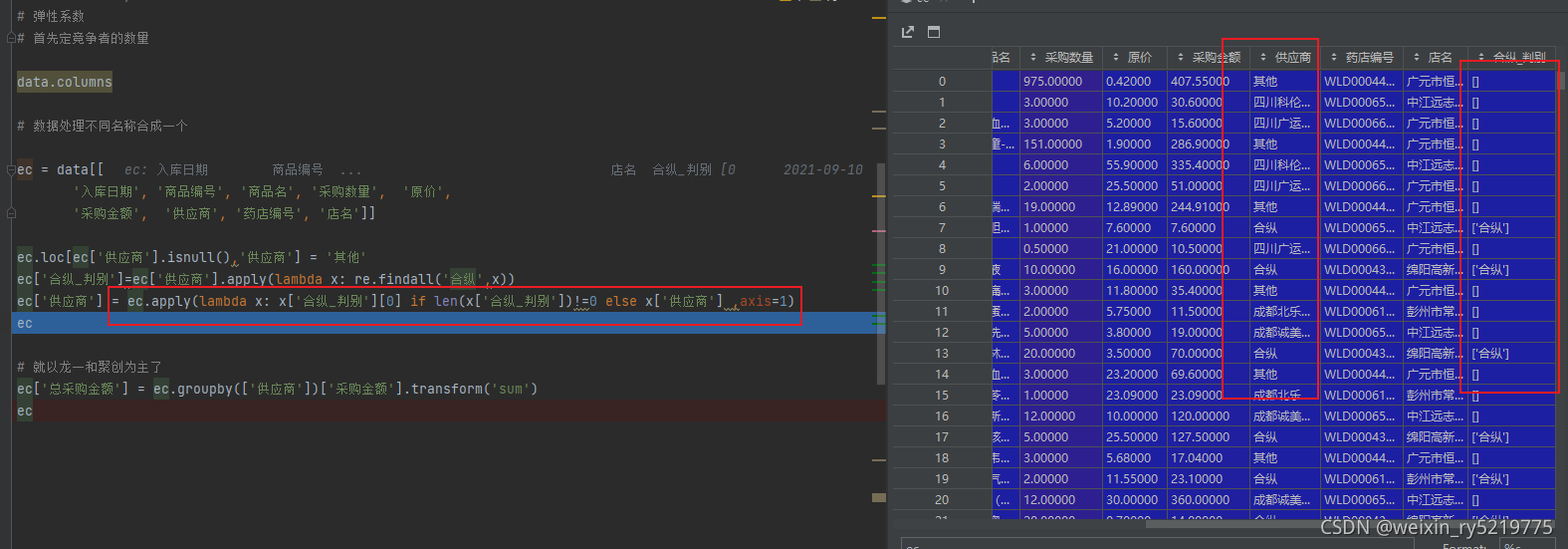
一句代码使用if判别
dataframe.dtypes
查看每列的数据类型
20211013
https://blog.csdn.net/weixin_38632246/article/details/86713078
A = np.column_stack((x_vals_column, ones_column))
操作一下,函数功能很明确,将2个矩阵按列合并
pandas.core.indexing.IndexingError: Too many indexers
series同时写了行和列索引
20211012
df.isnull ( ).sum (axis=0)
按行或按列批量统计缺失值
def missing_percent(df):
nan_percent = 100*(df.isnull().sum()/len(df))
# df.isnull().sum()统计每一列的缺失值数量
# 再除上len()得到每一列的缺失值比例——小数形式
# *100得到百分数
nan_percent = nan_percent[nan_percent > 0].sort_values()
# 得到每列的缺失值的占比,升序排序
# >0是为了筛掉没有缺失值的列,只返回有缺失值的
return nan_percent
print(missing_percent(train))
批量统计缺失值比例
20211010
https://blog.csdn.net/weixin_45008698/article/details/116523146
pivot_table转dataframe
https://www.cnblogs.com/bravesunforever/p/12771214.html
dropna thresh=2 剩下非零值至少大于2

分组对指定字段进行处理
20211009
isin如果不起作用,那应该两种数据类型不一致
https://blog.csdn.net/u010063879/article/details/80161741
pandas笛卡尔积
20211008
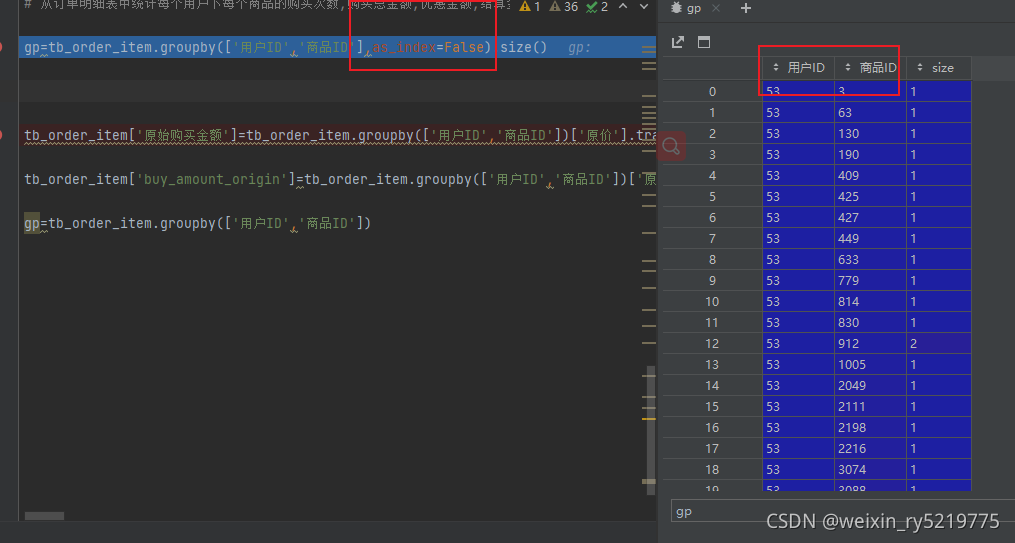
分组 as_index=False 分组的列直接在新表里面
否则作为索引
20210923
group['diff']=np.array(group['close'].values)-np.array(group['close_shift'].values)
Python Pandas: TypeError: only integer scalar arrays can be converted to a scalar index
20210826
http://www.360doc.com/content/18/0420/22/1489589_747395997.shtml
行索引转列

https://blog.csdn.net/AaronPaul/article/details/106682486
长表宽表转换
20210811

value_counts() 统计各种值的个数
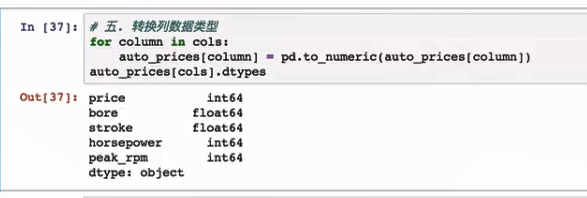
pd.to_numeric(xx) 转换数据类型
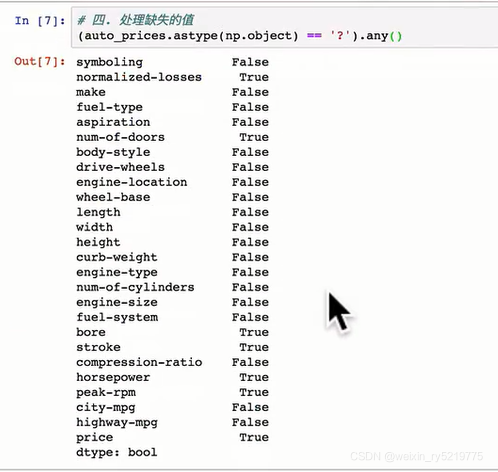
找出有缺失值的列
有缺失值就会变成object类型
df.loc[df['jianzl']=='null','jianzl']=0
指定条件赋值
20210719
https://blog.csdn.net/jingyi130705008/article/details/100692266
将dataframe中的两列数据转换成字典dic
merge() got multiple values for argument ‘how’,
pd.merge 中的pd 写成其中的某个dataframe了
20210713
groupby
size()和count的区别
https://blog.csdn.net/qq_36148333/article/details/114481253
size记录groupby依据的列的数据记录条数
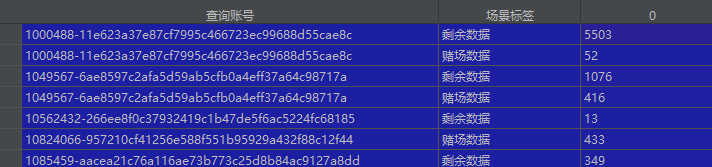
gp=data.groupby([‘查询账号’,‘场景标签’],as_index=True)
tj=gp.size().reset_index()
第一种

count记录 groupby 依据的列之外的其他每一列对于分组是否有取值
取值为零的不计入
第二种















 1497
1497











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









