







原始数据
增加、删除
添加一行
# 先创建一行的series数据
dic = {
'名字':'复仇者联盟3',
'投票人数':4565142,
'类型':'剧情/科幻',
'产地':'美国',
'上映时间':'1994-09-10 10:00:00',
'时长':154,
'年代':1996,
'评分':9.5,
'首映地点':'美国'
}
s = pd.Series(dic)
s.name = 5
append()添加会返回新的DataFrame

删除一行,按索引删除,drop()同样也返回新的数据

添加一列,类似于字典添加键值对,DataFrame[新列索引] = 值
在原DataFrame的基础上添加的列

删除列,与删除行一样,但是要使用axis=1指定删除列,返回新的DatFrame

空值操作
添加一条带空值的数据

查找空值
找出时长为空的数据df2[df2['时长'].isnull()]

空值替换、填充
将平均值填充到空值的位置上
# 找出非空的时长求平均值
sa = df2[~df2['时长'].isnull()]['时长'].astype(int)
avg_time = np.mean(sa)
# 填充空值,inplace设置为True是在原来数据上操作
df2['时长'].fillna(avg_time, inplace=True)


对所有空值进行填充
先设置三个空值

填充 这里没有指定inplace则生成了新的DataFrame

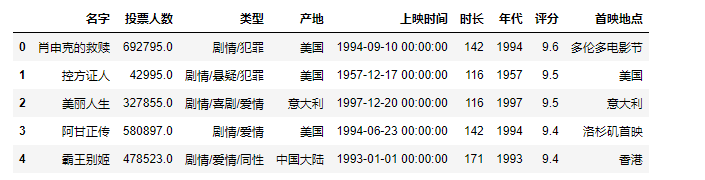
删除缺失值
dropna()
参数:how=‘all’ 删除全为空值的行或列 how='any’删除存在空值的行或列
subset 指定筛查空值的列
inplace 是否在源数据上操作
axis 选中行或列 默认为0,表示行
添加两条带nan值的数据

删除nan值所在的行
异常数据替换处理
使用replace()函数替换异常数据,替换结果生成新的dataFrame,原有数据不变,replace支持多种格式。
先创建一个DataFrame

将3替换成7

将5和6替换成7

将3换成6,5换成8

指定列操作
a列的5换成10

a列的1换成10,3换成9

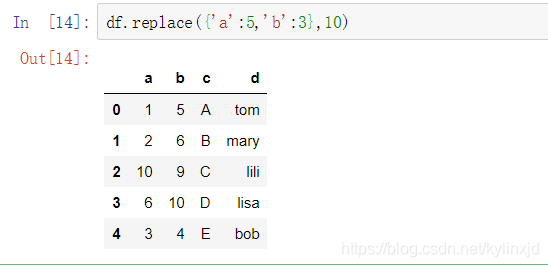
a列的5和b列的3换成10
正则匹配替换
修改一下数据

以Li开头的替换成newLi

将以Be开头的换成newBe,Rose换成newRose

c列以Vi和Ch开头的换成new

推荐下一篇:DataFrame常用描述统计函数















 3626
3626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









