










 本文详细介绍了数据库索引的概念、作用、优劣势,以及在不同场景下的使用建议,重点讲解了B树和B+树的数据结构,以及如何进行基本操作。
本文详细介绍了数据库索引的概念、作用、优劣势,以及在不同场景下的使用建议,重点讲解了B树和B+树的数据结构,以及如何进行基本操作。
目录
1.概念
2.作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
3. 索引对于提高数据库的性能有很大的帮助
3.优劣势
优势:提高查询的速度,快速定位,检索数据。
劣势:占据额外的硬盘空间;可能会拖慢插入删除修改的速度。
4.使用场景
结合上述数据库中索引作用以及优劣势,我认为使用场景应当考虑以下几点:
1.数据量较大,且经常对这些列进行条件查询
2.该数据库表的插入操作,及对这些列的修改操作频率较低。
3.硬件中磁盘空间大小足够。
5.基本操作
1.查看索引:
show index from 表名;
2.创建索引:
create index 索引名 on 表名(字段名);
3.删除索引:
drop index 索引名 on 表名;
6.数据结构
索引保存的数据结构主要为B+树,要了解B+树首先我们要了解B树。
B树
B树的核心思路和二叉搜索树差不多,本质上是一个N叉搜索树。一个节点上,可以保存多个key。
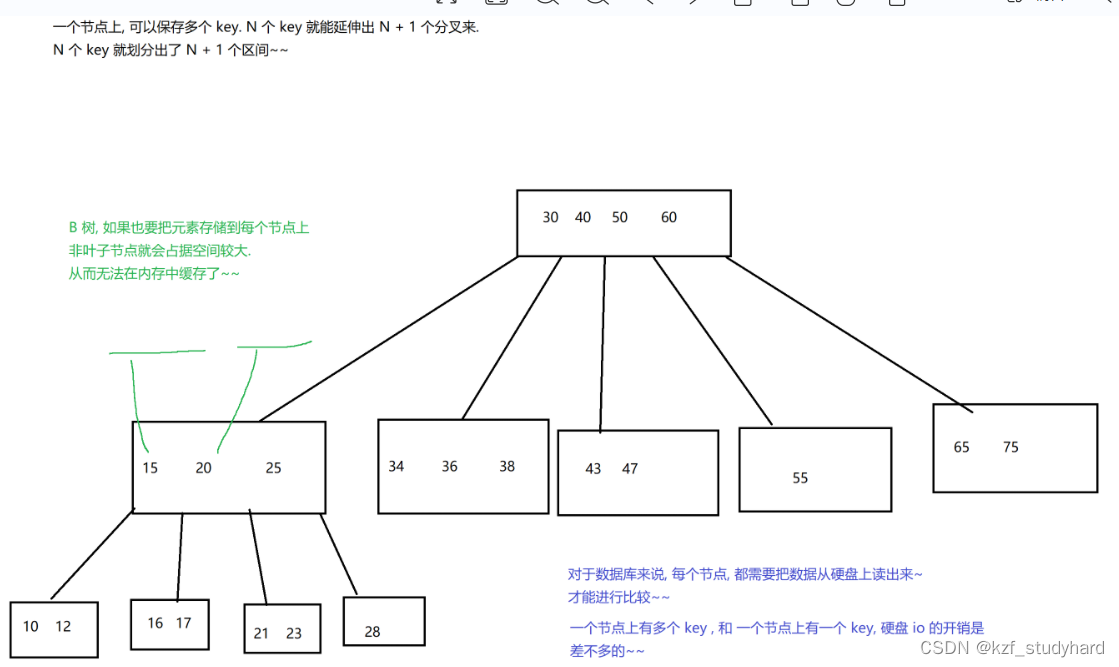
B树查询元素的流程:
拿着要查询的元素,从根节点出发,判定要查找的元素是否在根节点上存在。如果不存在,就看这个元素是落到哪个区间里,就沿着这个区间的路线往下一个节点上找,最终找到叶子节点,如果还不存在,那就说明此元素真的不存在了。
对于数据库来说,每个节点,都需要把数据从硬盘上读出来才能进行比较,一个节点上有多个 key ,和 一个节点上有一个 key, 硬盘 io 的开销是差不多的。
此时每个节点上都可以保存多个元素了,当总的元素个数固定的时候,相比于二叉搜索树,涉及到的节点的总数就大大降低了,树的高度也大大降低了,B 树的高度是远远小于二叉搜索树的。于是,进行査询的时候,硬盘IO的次数也就随之减少了。
B+树
B+树也是 N 叉搜索树,但是 N 个 key 分出了 N 个区间.其中节点上的最后一个 key 就是最大值了(取最小值也行)。

父节点的 key 会在子节点中重复出现(而且是以最大值的身份)看起来是有很多重复元素,浪费了空间,实际上能够达成一个重要的效果: 叶子结点这一层,包含了整个数据的全集!!!把叶子结点, 按照链表这样的方式,首尾相连。此时,就可以通过叶子节点之间的这个连接,快速找到"下一个""上一个"元素进一步的也方便进行“范围查询!
由其的特点所带来的优势有这些:
1.特别擅长范围查询.
2.所有的查询操作,最终都会落在叶子节点上,比较次数,是均衡的,查询时间是稳定的。
3.由于叶子节点上是完整的数据全集,因此表的每一行数据的其他列,都可以保存到叶子节点上,而非叶子节点,只存储构建索引的 key 即可 (只存 id 就行了)。
7.PS:
另外需要说明的是,在数据库中创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY)时,会自动创建对应列的索引。
以上便是我对数据库中索引的理解。感谢各位大佬,萌新的阅览!!!















 302
302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









