







第1章 了解SQL
【数据库】保存有组织的数据的容器(通常是一个文件或一组文件)。
【表】某种特定类型数据的结构化清单,存储在表中的数据是同一种类型的数据或清单。
在相同数据库中不能两次使用相同的表名,但在不同的数据库中却可以使用相同的表名。
【模式】关于数据库和表的布局及特性的信息。
【列】表中的一个字段。所有表都是由一个或多个列组成的。表由列组成。列存储表中某部分的信息。
理解列的最好办法是将数据库表想象为一个网格,就像个电子表格那样。网格中每一列存储着某种特定的信息。例如,在顾客表中,一列存储顾客编号,另一列存储顾客姓名,而地址、城市、州以及邮政编码全都存储在各自的列中。
可以根据具体需求来决定把数据分解到何种程度。例如,一般可以把门牌号和街道名一起存储在地址里。这没有问题,除非你哪天想用街道名来排序,这时,最好将门牌号和街道名分开。
【数据类型】所容许的数据的类型。每个表列都有相应的数据类型,它限制该列中存储的数据。
例如,如果列中存储的是数字(或许是订单中的物品数),则相应的数据类型应该为数值类型。如果列中存储的是日期、文本、注释、金额等,则应该规定好恰当的数据类型。
【行】表中的一条记录。你可能听到用户在提到行时称其为数据库记录(record)。这两个术语多半是可以交替使用的,但从技术上说,行才是正确的术语。
表中的数据是按行存储的,所保存的每个记录存储在自己的行内。例如,顾客表可以每行存储一个顾客。表中的行编号为记录的编号。
【主键】唯一标识表中每行的这个列(或这几列)称为主键。主键用来表示一个特定的行。没有主键,更新或删除表中特定行就极为困难,因为你不能保证操作只涉及相关的行。
表中的任何列都可以作为主键,只要它满足以下条件:
任意两行都不具有相同的主键值;
每一行都必须具有一个主键值(主键列不允许NULL值);
主键列中的值不允许修改或更新;
主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)。
【SQL】是Structured Query Language(结构化查询语言)的缩写。SQL是一种专门用来与数据库沟通的语言。提供一种从数据库中读写数据的简单有效的方法。
第2章 检索数据
【SELECT语句】从一个或多个表中检索数据信息
为了使用SELECT检索表数据,必须至少给出两条信息:想选择什么,从什么地方选择。
【检索单个列】
SELECT prod_name FROM Products;
-- 从 Products 表中检索一个名为 prod_name 的列。 所需的列名写在 SELECT 关键字之后,FROM 关键字指出从哪个表中检索数据。
【Hint】 SQL 语句不区分大小写,即“SELECT”和“select”一样;但是表名、列名和值可能有所不同。
【检索多个列】从一个表中检索多个列,在 SELECT 关键字后给出多个列名,列名之间用逗号隔开。
SELECT prod_id, prod_name, prod_price
FROM Products;
-- 从表 Products 中选择 3 列数据【检索所有列()】在实际列名的位置使用星号()通配符
SELECT *
FROM Products给定一个通配符(*),则返回表中所有的列。列的顺序一般是列在表定义中出现的物理顺序。
【检索不同的值(DISTINCT)】
--检索 products 表中所有产品供应商的id,但是返回行有重复的id,怎么去重?
SELECT DISTINCT vend_id
FROM ProductsDISTINCT告诉 DBMS只返回(具有唯一性)的vend_id 行。
【限制返回的行数(TOP)】
SELECT TOP 5 prod_name
FROM Products
--只返回匹配的前5行数据【注释】(– 和 /* */)
第3章 排序检索数据
【排序数据(ORDER BY)】为了明确检索的数据顺序,可用 ORDER BY 子句取一个或多个列的名字,据此对输出进行排序
SELECT prod_name
FROM Products
ORDER BY prod_name;
-- 对 prod_name 列以字母顺序进行数据排列【Hint】在指定一条order by子句时,应保证它是select语句中最后一条子句。该子句的次序不对将会出现错误信息。
【按多个列排序】
下面代码检索3个列,并按其中两个列对结果进行排序
-- 先价格,若价格相同按名称排序
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price, prod_name;【按列位置排序(相对位置)】
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY 2, 3;
-- 输出与上面的查询相同。2 指 SELECT 清单的第2列即prod_price,3 指第3列即 prod_name【指定排序方向(ASC,DESC)】默认升序(ASC)排列,可以指定 DESC 关键字进行降序排序。
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price DESC
-- DESC 关键字只应用到直接位于其前面的列名。
-- 如果打算用多个列排序,该怎么办?
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price DESC, prod_name
-- 多列降序排列,必须对每列指定DESC第4章 过滤数据
【WHERE 子句:过滤】指定搜索条件(即过滤条件)。
WHERE 子句在表名(FROM 子句)后给出,根据 WHERE 子句中指定的条件过滤。
SELECT prod_name, prod_price
FROM Products
WHERE prod_price = 3.49;
-- 从Products 表中检索两个列,只返回 prod_price 值为 3.49 的行【Hint】同时使用 ORDER BY 和 WHERE 子句时,ORDER BY 要位于 WHERE 之后。
【WHERE 子句操作符】

-- 列出所有价格小于 10 美元的商品:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price < 10;
-- 列出所有不是供应商 DLL01 制造的产品:
SELECT vend_id, prod_name
FROM Products
WHERE vend_id <> 'DLL01';
-- 第二种写法
SELECT vend_id, prod_name
FROM Products
WHERE vend_id != 'DLL01';
-- 检索价格在 5 美元和 10 美元之间的所有产品:
SELECT prod_name, prod_price
FROM Products
WHERE prod_price BETWEEN 5 AND 10
-- 检索没有电子邮件的顾客:
SELECT cust_name, cust_email
FROM Customers
WHERE cust_email IS NULL第5章 高级数据过滤【AND、OR 操作符】
-- 检索由供应商 DLL01 制造且价格小于等于 4 美元的所有产品的名称和价格:
SELECT prod_id, prod_price, prod_name
FROM Products
WHERE vend_id = 'DLL01' AND prod_price <= 4;
-- 检索任一个指定供应商制造的所有产品的名称和价格:
SELECT prod_name, prod_price
FROM Products
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01';
-- 检索价格为 10 美元以上,且由 DLL01 或 BRS01 制造的所有产品:
SELECT prod_name, prod_price
FROM Products
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01'
AND prod_price >= 10;【Hint】SQL 在处理 OR 操作符前,优先处理 AND 操作符
【Hint】在 WHERE 子句中使用圆括号:改变优先级;明确操作顺序,增强可读性。
SELECT prod_name, prod_price
FROM Products
WHERE (vend_id = 'DLL01' OR vend_id = 'BRS01')
AND prod_price >= 10;【IN 操作符】用来指定条件范围,范围中的每个条件都可以进行匹配。
-- 检索由供应商 DLL01 和 BRS01 制造的所有产品:
SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN ('DLL01', 'BRS01')
ORDER BY prod_name;
-- 用 IN 完成和 OR 同样的操作
SELECT prod_name, prod_price
FROM Products
WHERE vend_id = 'DLL01' OR vend_id = 'BRS01'
ORDER BY prod_name【NOT 操作符】用来否定其后所跟的任何条件
-- 列出除 DLL01 之外的所有供应商制造的产品:
SELECT prod_name
FROM Products
WHERE NOT vend_id = 'DLL01'
ORDER BY prod_name;
-- another way : <>
SELECT prod_name
FROM Products
WHERE vend_id <> 'DLL01'
ORDER BY prod_name;第6章 用通配符进行过滤(类似正则表达式匹配)
【LIKE操作符】用来匹配值的一部分的特殊字符,通配符搜索只能用于文本字段(字符串),非文本数据类型字段不能使用通配符搜索
【百分号(%)通配符】任何字符出现任意次数
-- 找出所有以词 Fish 起头的产品
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE 'Fish%';
-- 搜索包含文本 bean bag 的值
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '%bean bag%';
-- 找出以 F 起头、以 y 结尾的所有产品
SELECT prod_name
FROM Products
WHERE prod_name LIKE 'F%y';【下划线(_)通配符】只匹配单个任意字符
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '__ inch teddy bear';【方括号([])通配符】用来匹配一个字符集,它必须匹配指定位置(通配符的位置)中的一个字符
-- 找出所有名字以 J 或 M 起头的联系人
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[JM]%';
-- 匹配方括号中任意一个字符,也只能匹配单个字符。
-- 查询匹配非 J 或 M 字符开头的任意联系人名
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[^JM]%';
-- 通过前缀字符 ^(脱字号)来否定
-- another way : NOT
SELECT cust_contact
FROM Customers
WHERE NOT cust_contact LIKE '[JM]%';【Hint】通配符搜索一般比前面讨论的其它搜索要耗费更长时间。
所以:
不要过度使用通配符。如果其它操作符能达到相同目的,应该使用其它操作符
尽量不要讲它们用在搜索模式的开始处。把通配符置于开始处,搜索起来是最慢的。
注意通配符的位置
第7章 创建计算字段
【计算字段】
存储在数据库表中的数据一般不是应用程序所需要的格式。我们需要直接从数据库中检索出转换、计算或格式化过的数据,而不是检索出数据,然后再在客户机应用程序中重新格式化。
计算字段并不实际存在于数据库表中。计算字段是运行时在select语句内创建的。
只有数据库知道select语句中的哪些列是实际的表列,哪些列是计算字段。从客户机的角度来看,计算字段的数据是以其他列的数据相同的方式返回的。
【拼接】将值联结到一起(将一个值附加到另一个值)构成单个值
-- Vendors 表包含供应商名和地址信息。假如要生成一个供应商报表,需要在格式化的名称(位置)中列出供应商的位置。
SELECT vend_name + ' (' + vend_country + ')'
FROM Vendors
ORDER BY vend_name;
-- 去除空格、列别名
SELECT RTRIM(vend_name) + ' (' + RTRIM(vend_country) + ')' AS vend_title
FROM Vendors
ORDER BY vend_name;【算数】:+-*/ (可用圆括号改变优先级)
SELECT prod_id, quantity, item_price,
quantity * item_price AS expanded_price
FROM OrderItems
WHERE order_num = '20008'第8章 使用数据处理函数大多数SQL实现支持以下类型的函数:
1)用于处理文本串(如删除或填充值,转换值为大写或小写)的文本函数。
2)用于在数值数据上进行算术操作(如返回绝对值,进行代数运算)的数值函数。
3)用于处理日期和时间值并从这些值中提取特定成份的日期和时间函数。
4)返回DBMS正使用的特殊信息的系统函数。
【文本处理函数】
-- 使用 UPPER() 函数--将文本转换为大写
SELECT vend_name, UPPER(vend_name) AS vend_name_upcase
FROM Vendors
ORDER BY vend_name;常用的文本处理函数:
LEFT():返回字符串左边的字符
DATALENGTH():返回字符串的长度
LOWER():将字符串转换为小写
LTRIM():去掉字符串左边的空格
RTRIM():去掉字符串右边的空格
UPPER():将字符串转换为大写
其他略
第9章 汇总数据使用聚集函数,SQL查询可用于检索数据,以便分析和报表生成。比如:确定表中行数,获得表中行组的和,找出表列的最大、最小和平均值。
【聚集函数】运行在行组上,计算和返回单个值的函数。

【AVG】只能用来确定特定数值列的平均值,而且列名必须作为函数参数给出。为了获得多个列的平均值,必须使用多个AVG()函数。
SELECT AVG(prod_price) AS avg_price
FROM Products
WHERE vend_id = 'DLL01';【COUNT】确定表中行的数目或符合特定条件的行的数目。
有两种使用方式:
1)使用COUNT(*)对表中行的数目进行计数,不管表列中包含的是空值还是非空值。
2)使用COUNT(column)对特定列中具有值的行进行计数,忽略null值。
SELECT COUNT(*) AS num_cust
FROM Customers;【MAX】返回指定列中的最大值。MAX()要求指定列名。在用于文本数据时,如果数据按相应的列排序,则MAX()返回最后一行。它忽略列值为NULL的行。
SELECT MAX(prod_price) AS max_price
FROM Products;【MIN】返回指定列的最小值。
【SUM】用来返回指定列值的和。它忽略值为null的行。
利用标准的算术操作符,所有聚集函数都可用来执行多个列上的计算。
对以上5个聚集函数都可以如下使用:
对所有的行执行计算,指定ALL参数或不给参数;
只包含不同的值,指定DISTINCT参数。
-- DISTINCT:平均值只考虑各个不同的价格
SELECT AVG(DISTINCT prod_price) AS avg_price
FROM Products
WHERE vend_id = 'DLL01';【组合聚合】
SELECT AVG(prod_price) AS avg_price
COUNT(*) AS num_cust
MAX(prod_price) AS max_price
FROM Products第10章 分组数据
【GROUP BY】指示DBMS分组数据,然后对每个组而不是每个结果进行聚集。
如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组上进行汇总。在建立分组时,指定的所有列都一起计算,所以不能从个别的列取回数据。
GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在select中使用表达式,则必须在group by子句中指定相同的表达式,不能使用别名。
大多数SQL实现不允许GROUP BY列带有长度可变的数据类型。
除聚集计算语句外,select语句中的每个列都必须在GROUP BY子句中给出。
如果分组列中具有NULL值,则NULL將作为一个分组返回。如果列中有多行NULL值,它们將分为一组。
GROUP BY子句必须出现在WHERE子句之后,ORDER BY子句之前。
SELECT vend_id, COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id;

【过滤分组】规定包括哪些分组,排除哪些分组。所有类型的WHERE子句都可以用HAVING来替代。唯一的差别是WHERE过滤行,而HAVING过滤分组。
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2; WHERE在数据分组前进行过滤,HAVING在数据分组后进行过滤。WHERE排除的行不包括在分组中,这可能改变计算值,从而影响HAVING子句中基于这些值过滤掉的分组。
应该仅在与GROUP BY子句结合时才使用HAVING,而WHERE子句用于标准的行级过滤。
【分组和排序】不要忘记ORDER BY
一般在使用GROUP BY 子句时,应该也给出ORDER BY 子句。这是保证数据正确排序的唯一方法。千万不要仅依赖GROUP BY 排序数据。

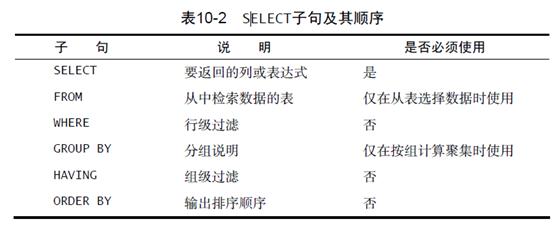
【SELECT子句顺序】
















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











