






当你想要快速批量采集某个网站的内容时,首先想到的会是什么?
有的朋友可能会想到爬虫工具,但大部分人基本也只是听过,没用过。如果要用的话,会不会很复杂?要不要学习什么技术?
今天就给大家分享一个实用的网页内容批量采集工具XPath,不需要复杂的准备工作,就能快速上手,尤其适用于轻量化的网页内容抓取。
掌握了XPath的用法之后,只需3个字母,就可以抓取4943条数据。接下来,我以一个真实的网页内容抓取需求为例,详细讲解XPath的用法。
假设你正在开展一项研究,需要收集餐饮连锁品牌的名单,这时候找到一个网站:
https://www.maigoo.com/brand/list_1811.html
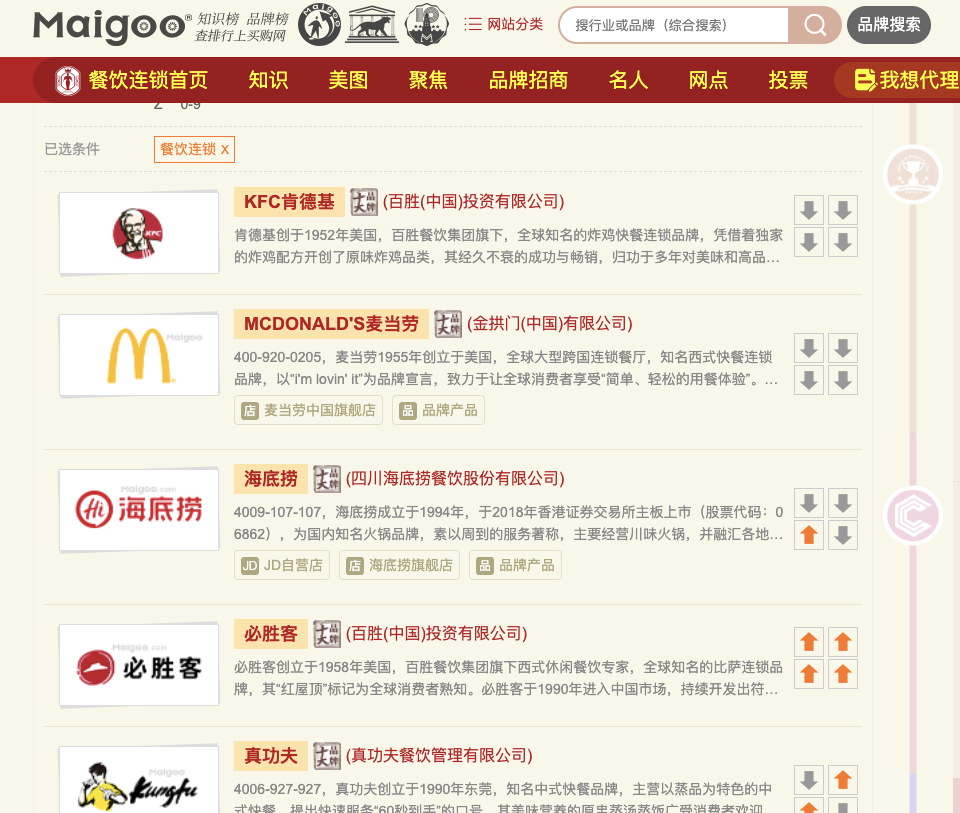
网站上有数十个餐饮连锁的名单,如果是一个个复制粘贴,50个就需要来回操作上百次,倘若还要搜集其他的名单,这一天下来不仅效率极低,手估计也要废了。
如何能够一键抓取这些品牌的名单呢?这时候XPath就帮大忙啦。
一、准备工作
在正式开始之前我们需要先做好准备工作,这里列出了所有的准备清单。
1、安装Chrome(谷歌)浏览器
https://www.google.cn/intl/zh-CN/chrome/
2、安装XPath Helper插件
方法一:(有梯子可以直接前往chrome应用商店下载,避免安装出错)
https://chrome.google.com/webstore/detail/xpath-helper/hgimnogjllphhhkhlmebbmlgjoejdpjl
方法二:没梯子可下载安装包,可能有的浏览器版本不适配,文末有安装包获取方法
3、抓取的目标网站
4、没接触过XPath的朋友, 可前往此处学习详细的使用教程
https://www.runoob.com/xpath/xpath-tutorial.html
所有的案例资料和插件工具,我都打包整理好了,加微信yesaze (备注XPath)即可领取。
二、安装XPath Helper插件
1、打开Chrome浏览器,点击右上角“ ”按钮,选择“更多工具”-> “扩展程序”

2、打开右上角“开发者模式”,点击“加载已压缩的扩展程序”,选择已解压的XPath helper 插件文件夹(XPath helper插件只能在谷歌浏览器中使用)

3、当扩展程序中出现XPath helper时,就代表安装成功了

4、在Macbook上按shift+command+X键,可以快速唤起和隐藏XPath Helper(Windows的快捷键是Ctrl+Shift+X)
三、抓取网页内容
1、什么是XPath?
XPath 是一门在 XML 文档中查找信息的语言。而XML是一种结构化的编程语言,如果不理解也没关系。
你只需要知道,我们所看到的的网页,其实是由有规律、有结构的代码组成,我们所要提取的内容,就在这些结构化的代码里面。
XPath可以帮助我们根据网页的结构路径,灵活编写爬虫脚本,定位到我们需要的内容,从而进行抓取。
打开前面案例中的链接:
https://www.maigoo.com/brand/list_1811.html
我们看到的是排布整齐的图文,当我们点击鼠标右键→检查,可以看到页面的内容都是有固定结构的,一级一级向下展开。
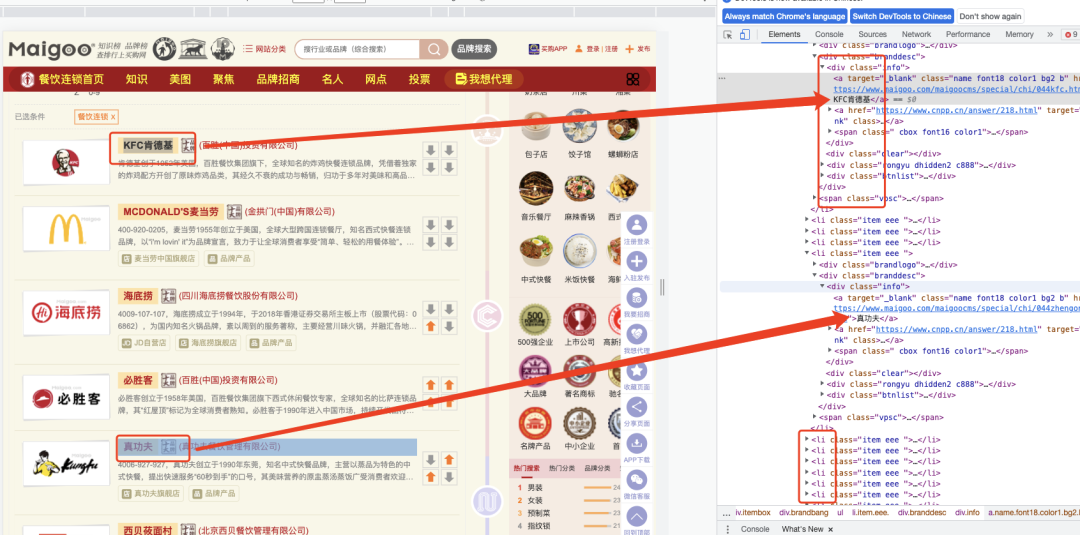
XPath 使用路径表达式在 XML 文档中选取节点。如果我们需要提取餐饮品牌的名称,只需要编写对应的路径即可。
在 XPath 中,有七种类型的节点:元素、属性、文本、命名空间、处理指令、注释以及文档(根)节点。
<li>
<div class="info">
<a target="_blank">KFC肯德基</a>
</div>
</li>
以上代码是从网站中截取的XML代码,为了便于讲解,做了精简处理。其中文档节点、元素节点、属性节点例子如下:
<li> (文档节点)
<a target="_blank">KFC肯德基</a>(元素节点)
target="_blank" (属性节点)
在这个案例中,我们可以看到,li里面包含了div,它们统称为节点,li是父节点,div是子节点。依此类推div里面又包含了a,它们又构成父子节点关系。
其中info、_blank等值,没有父或子节点,称之为基本知识,就是最基础的元素。
2、如何编写爬虫路径?
理解了节点的概念,我们只需要编写一个路径,从大到小,逐级定位到我们需要的内容节点即可。那要如何编写路径呢?
我们用双斜杠//表示从匹配选择的当前节点选择文档中的节点,而不考虑它们相对位置。如//li,表示选取所有li子元素,而不管它们在文档中的位置。

形如 //li//div//a/text() 表示定位到所有li下的所有div,所有div下的所有a,并提取其中的文本内容,(text()表示提取文本内容)

此时我们将语句输入XPath helper,发现有很多空的内容也被抓取了。先别着急,完整的语句应该是:
//li//div[@class=“info”]/a/text()

与前面的语句相比,其中多了一个**[@class=“info”]**,这个的意思是选取所有 div 元素,且这些元素拥有值为 info 的 class 属性。这样定位就更精准了。
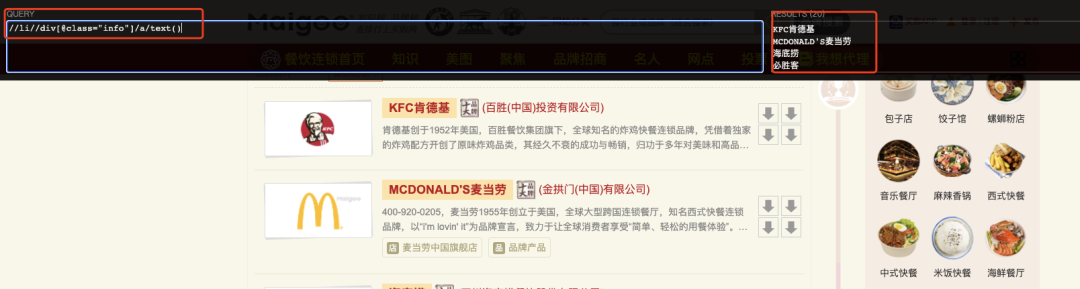
最后我们只需要全选复制结果即可,通过短短几个语句就能快速采集网页内容。
对于没有接触过XPath的朋友,可能有点晦涩难懂,建议还是详细阅读一下学习教程,半个小时就能掌握语句的含义和用法,能为以后采集内容省去不少时间。
四、补充案例
如果说刚才的案例不太好理解,那我们再来看一个简单的案例,如何用3个字母抓取4943条数据?
在网站
https://www.maigoo.com/category/zhishi/
中,详细罗列了不同的行业类别及子类目,只需要通过**//li/a**这简短的语句,就能把所有类目抓取下来。
//li/a表示定位到所有li下的a,这个网页结构比较简单,只要能快速识别结构,就能轻松写出路径。
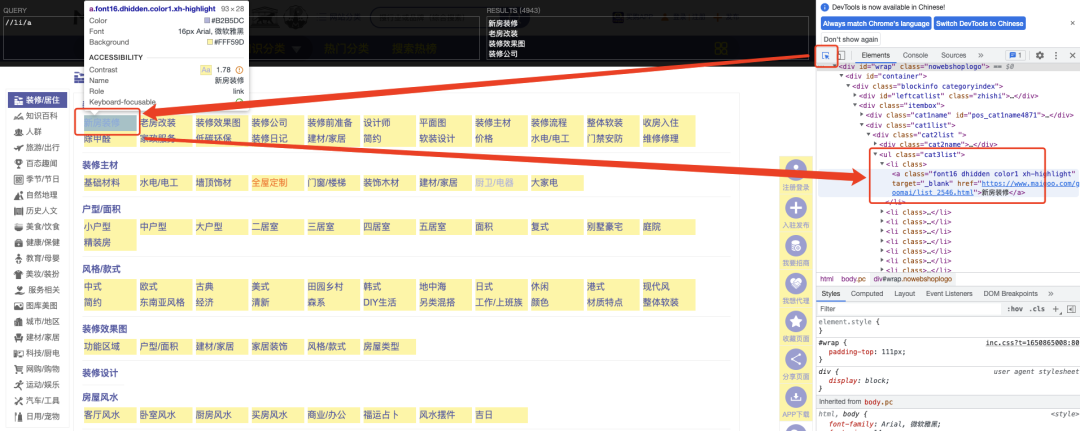
同理如果我们只需要抓取左侧的品牌大类,只需写出相应的路径即可
//div[@id=“leftcatlist”]/a,表示定位到包含id="leftcatlist"属性的div下的所有a,21个品牌大类的数据就轻松完成采集了。
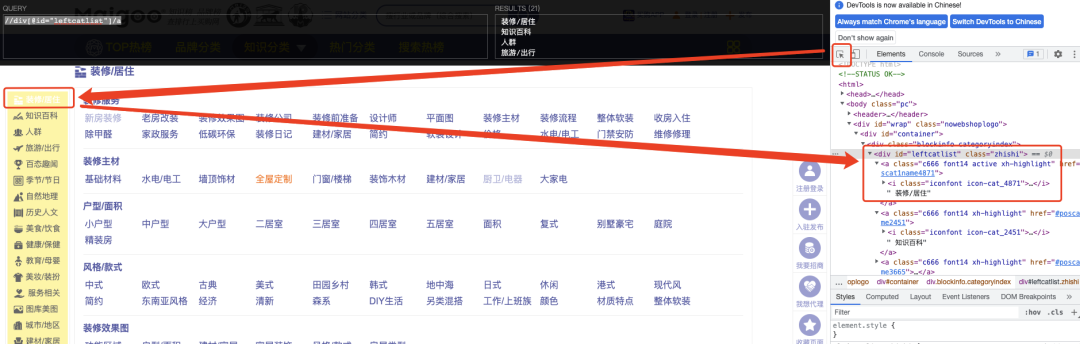
以上就是XPth案例教学的全部内容,其中只用到了一部分XPath的能力,还有更多功能等待你去探索。想要系统学习推荐前往
https://www.runoob.com/xpath/xpath-tutorial.html
了解详情,有完整免费的教程内容。

工具就是熟能生巧,长时间不用就容易遗忘,所以想要熟练掌握一是要勤加练习和使用。书到用时方恨少,事到经过才知难。
如果觉得有帮助建议收藏备用,反复阅读。
此外我这里准备了详细的Python资料,除了为你提供一条清晰的学习路径,我甄选了最实用的学习资源以及庞大的实例库。短时间的学习,你就能够很好地掌握爬虫这个技能,获取你想得到的数据。
01 专为0基础设置,小白也能轻松学会
我们把Python的所有知识点,都穿插在了漫画里面。
在Python小课中,你可以通过漫画的方式学到知识点,难懂的专业知识瞬间变得有趣易懂。


你就像漫画的主人公一样,穿越在剧情中,通关过坎,不知不觉完成知识的学习。
02 无需自己下载安装包,提供详细安装教程

03 规划详细学习路线,提供学习视频
04 提供实战资料,更好巩固知识
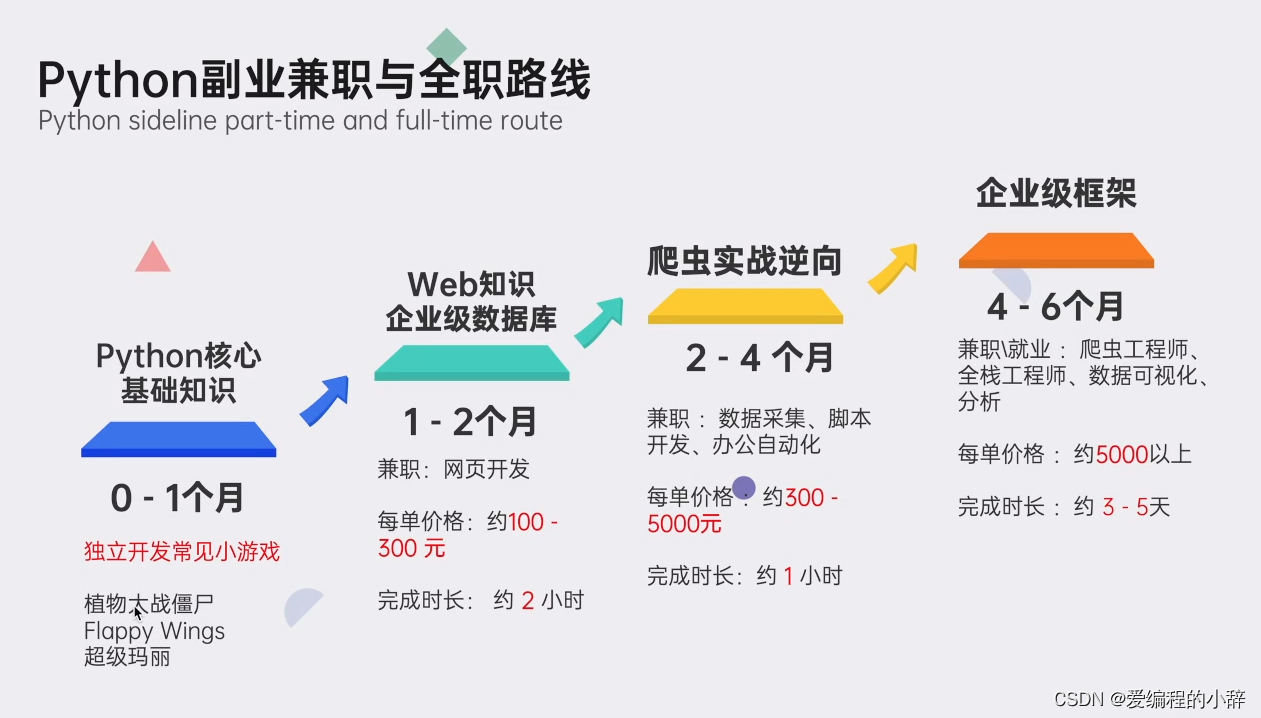
05 提供面试资料以及副业资料,便于更好就业
这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要也可以扫描下方csdn官方二维码或者点击主页和文章下方的微信卡片获取领取方式,【保证100%免费】
















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









