






一、引言
1、静态网页
首先我们来了解一下什么是静态网页,有一种说法是这样的:
静态网页是标准的HTML文件,它的文件扩展名是.htm、.html,可以包含文本、图像、声音、FLASH动画、客户端脚本和ActiveX控件及JAVA小程序等。静态网页是相对于动态网页而言,是指没有后台数据库、不含程序和不可交互的网页。
2、爬虫
网络爬虫又称网络蜘蛛和网络机器人,也是一种程序或脚本、它可以自动请求万维网网站并提取网络数据,但需要遵守一定的规则。
今天用Python中的爬虫来爬取一个静态网页,其实爬虫并非Python独有,其他语言也可以写爬虫,比如Java,PHP等等,但Python相对来说比较简单一些
3.robots协议
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),它的作用很简单,就是告诉爬虫,在这个网页什么内容你可以爬取,什么东西你不应该去爬取,市面上主流搜索引擎都会遵守Robots协议,因为搜索引擎本质是也可以说是爬虫。
二、requests
1、requests的简介
今天使用一个简便的爬虫库:requests,先来简单认识一下它, requests 库是一个原生的 HTTP 库,比起其他一些库更为容易使用。 它可以发送原生的 HTTP 1.1 请求,让使用者不用手动为 URL 添加查询串, 也不需要对 POST 数据进行表单编码
2、实践
先上代码
以中国气象局天气预报为例子
#导入模块
import requests
#该模块作用是使打印出来的json格式化
import pprint
#请求的URL路径
url = "https://weather.cma.cn/api/now/59287"
#发送一个请求
requests = requests.get(url)
#进行编码,主要作用是防止乱码
requests.encoding='utf-8'
#该变量作用是将数据储存起来
re_data = requests.json()
#让打印出来的json格式化
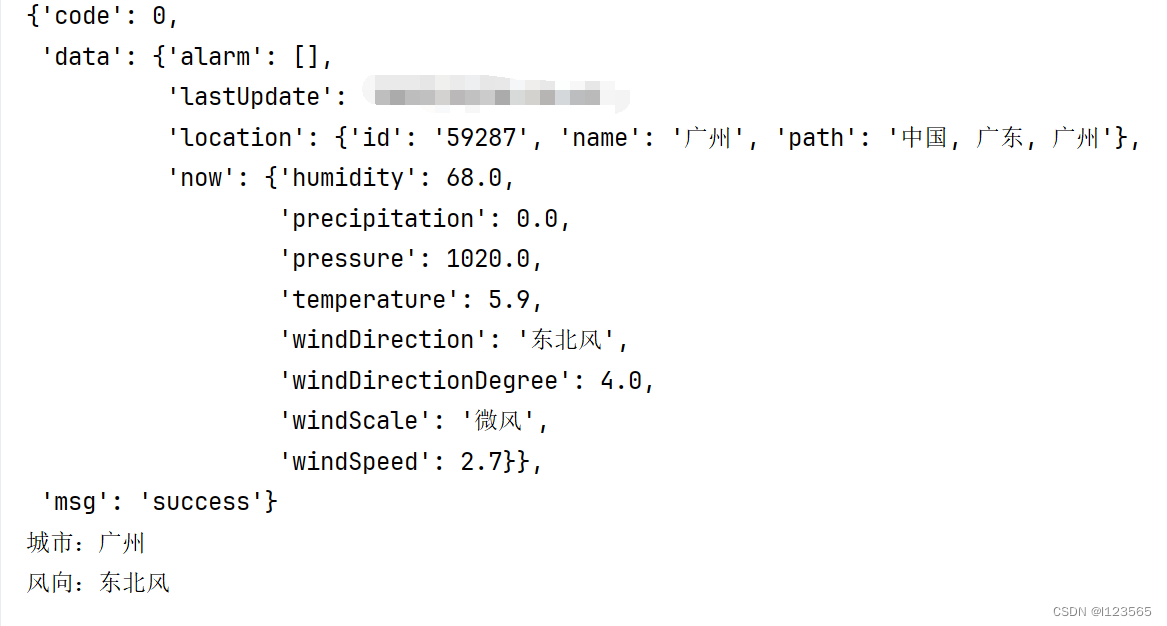
pprint.pprint(re_data)
print("城市:" + re_data['data']['location']['name'])
print("风向:" + re_data['data']['now']['windDirection'])这里用和城市和风向做例子,将有效信息从一堆字符串里提取出来,结果如下:
虽然代码看起来简单,但是我这种做法能爬取到的信息少之又少,不过这只是对requests库的浅尝辄止,毕竟都用到爬虫了,这点信息自然是不够的。但俗话说:“工欲善其事,必先利其器”,先来认识一下新的库。
三.BeautifulSoup
1、简介
还是简单介绍一下BeautifulSoup,BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。这个库能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。它是一个解析器,可以特定的解析出内容,省去了我们编写正则表达式的麻烦。同时,Beautiful Soup支持多种格式和语法,可以通过不同的解析器快速解析和查找网页文档.。
四、正则表达式
先粗略认识一下:
正则表达式是一种用于匹配字符串中特定模式的强大工具。它可以用来检查一个字符串是否符合某种特定的格式,例如电子邮件地址、电话号码、网址等。正则表达式由一系列字符组成,这些字符可以表示特定的字符、元字符和操作符。
元字符是正则表达式中具有特殊含义的字符,例如:
.匹配任意单个字符(除了换行符)*匹配前面的字符零次或多次+匹配前面的字符一次或多次?匹配前面的字符零次或一次[ ]匹配方括号内的任意一个字符{n}匹配前面的字符恰好n次^匹配字符串的开头$匹配字符串的结尾\转义特殊字符
1、(三+四)实践
接下来我们试着将整个静态网页的HTML代码全提取出来,先把代码放上来:
import requests
from bs4 import BeautifulSoup
url = 'https://weather.cma.cn/web/weather/map.html' # 需要爬取的网页URL
response = requests.get(url)
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
print(soup.prettify())
依旧还是中国气象局天气预报这个网站,如下图所示,我们提取了一整个网页的HTML代码:
(篇幅原因,只能展示部分)
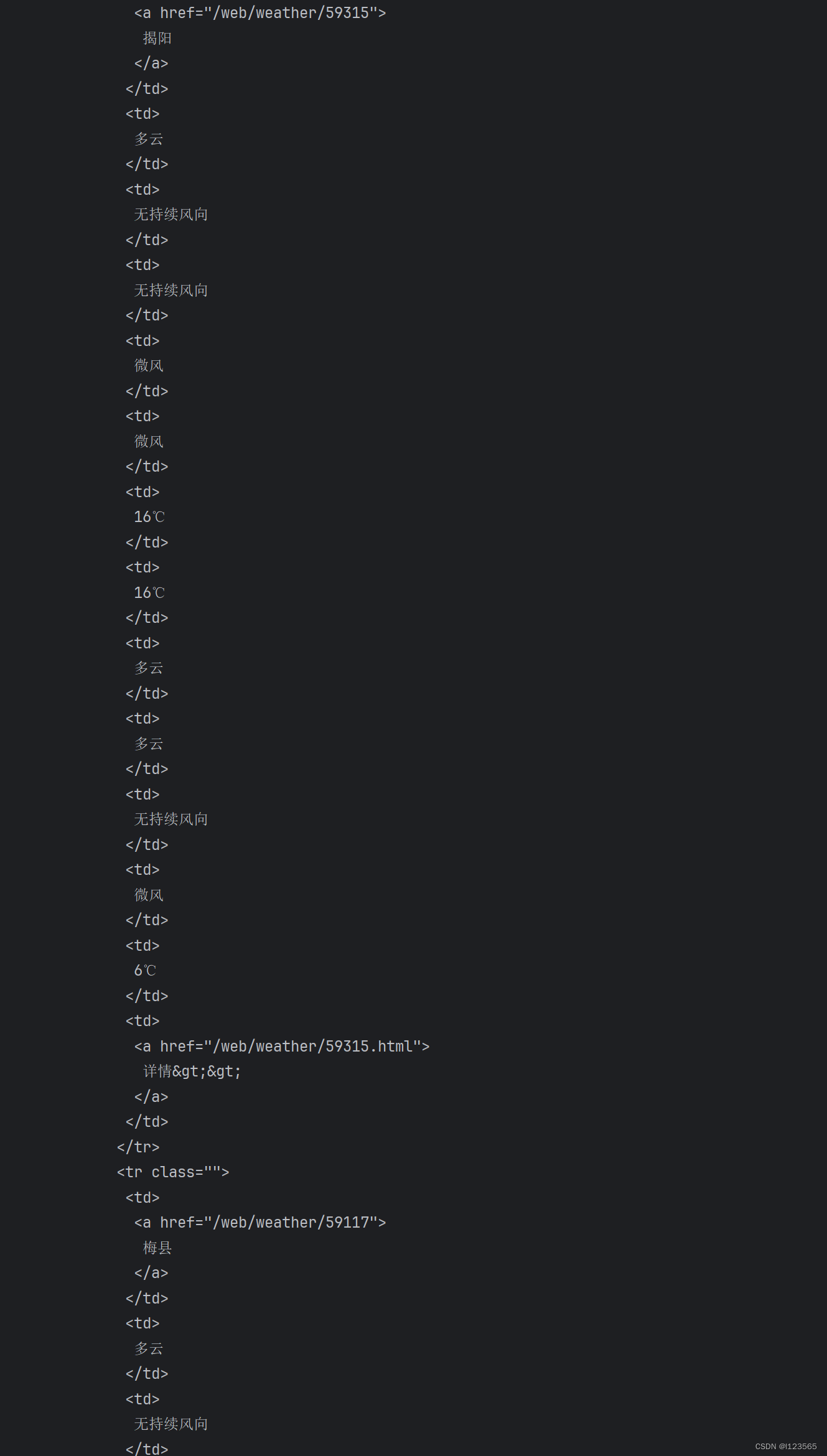
可以看到一整页的代码很多,我们可以按照一定规则提取有有的信息:
import requests
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
findLink = re.compile(r'<td>(.*?)</') #正则表达式
url = 'https://weather.cma.cn/web/text/HN/AGD.html' # 需要爬取的网页URL
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser')#解析数据
#输出原来整个网页的HTML源码,测试是否爬取成功
#print(soup.prettify())
for item in soup.find_all('tr', class_="odd"): # 查找符合要求的字符串
item = str(item)#将获取到的item变成字符串
link = re.findall(findLink, item) # 通过正则表达式查找
print(link)通过一定的规则(正则表达式)将数据进行处理后,得到的数据价值提升了许多,如下图:
(篇幅原因,只能展示部分)

这一张处理过后的数据,看起来不止比整个HTML页面舒服多了,就数据方面的提升也是一眼就可以看出来,但可以看见,第一个数据和最后一个数据有还是有标头,而且还有重复的部分,所以我们接下来要进行数据再处理,最后将数据存表。
五.数据存表
1、真·完整代码:
import requests
from bs4 import BeautifulSoup # 网页解析,获取数据
import re # 正则表达式,进行文字匹配
#将数据存进xlsx表
from openpyxl import Workbook
excel = Workbook()
work = excel.active
#列表第一行
work.append(['城市','白日天气现象','白日风向','白日风力','当天最高温度','夜晚天气现象','夜晚风向','夜晚风力','当天最低温度'])
# 正则表达式
findLink = re.compile(r'<td>(.*?)</td',re.S)
findTitle = re.compile(r'<td>(.*?)</td',re.S)
head={
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36"
}
url = 'https://weather.cma.cn/web/text/HN/AGD.html' # 需要爬取的网页URL
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, 'html.parser') # 解析数据
# 输出原来整个网页的HTML源码,测试是否爬取成功
#print(soup.prettify())
for item in soup.find_all('tr', class_="odd"): # 查找符合要求的字符串
item = str(item) # 将获取到的item变成字符串
titles = re.findall(findTitle, item) # 通过正则表达式查找
link = re.findall(findLink,item)[0]
#对获取的数据进一步处理
pattern = r'<a href=".*?">(.*?)<\/a>'
# 使用re.findall来查找所有匹配的项
matches = re.findall(pattern, link)
#字符串相加
s = matches+titles[1:-1]
#存表
work.append(s)
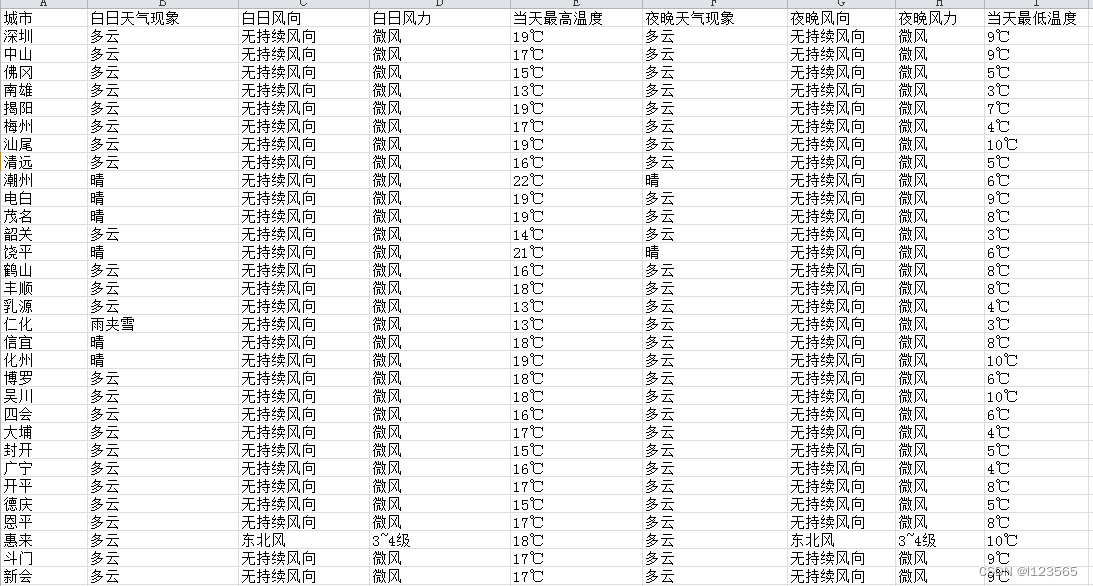
excel.save("天气预报.xlsx")
print(matches,titles[1:-1])结果:

在上面这张图我们可以看见,我将城市的名字从标头<a href=" "里面提取了出来,在进一步处理数据的位置
#对获取的数据进一步处理
pattern = r'<a href=".*?">(.*?)<\/a>'
# 使用re.findall来查找所有匹配的项
matches = re.findall(pattern, link)
#字符串相加
s = matches+titles[1:-1]因为得出来的结果为两个字符串,所以将他们相加在一起,方便下面存表。
2、表数据
代码执行完毕之后,在pycharm的左上角,项目的位置上会出现一个xlsx文件:
文件内容如下:
六、结语
本文使用了与爬虫有关三个库来爬取一篇静态网页,也初步展示了怎么处理拿到手的数据,使其变得更加美观,更具价值,还有怎么将数据存进xlsx表中。想要获取高质量的网页数据,可以在开始爬取数据前,通过选择合适的爬虫框架、建设爬取的流程等,都可以提高爬虫程序的效率和准确性。
此外,爬虫还具有数据清洗和处理的能力,它能去除噪声数据、过滤无用信息,并将数据转换为可用的格式,为后续的分析和应用做好准备。
最后,爬虫可以整合和分析数据,这对于大规模数据的分析和研究至关重要。
好了,到此为止了。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









