







关于java 自定义规则的研读记录:
1:关于每一个方法中的tree的联想
看了以前的代码,通过断点调试,方法中的tree参数用处大多是这样;
tree.type().firstToken().text();
tree.type().firstToken().text();
tree.block().body();这些对于部分需求是不满足的,比如存在多个字符串的拼接,链式编程等
所以在代码中不断地,一步一步的断点,向源码中追寻踪迹,发现了一些有用的东西
比如这两个词 startIndex,endIndex,开始的下标,结束的下标,两个值的差值是token、firstToken().text()的长度,那么这个下标用在了哪里,怎么用?
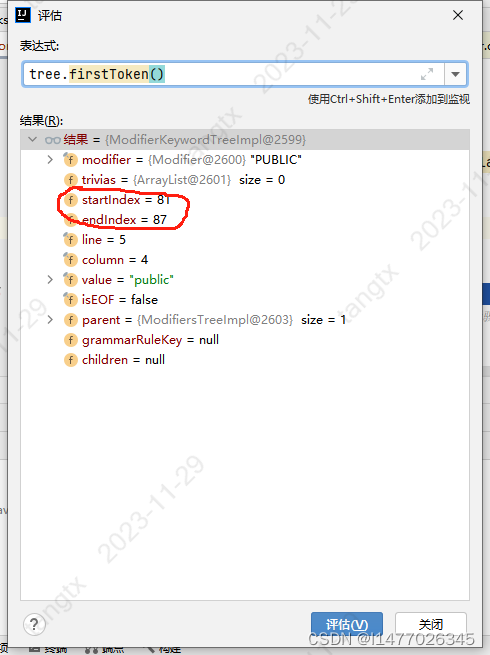
带着问题找到了这两个个地方
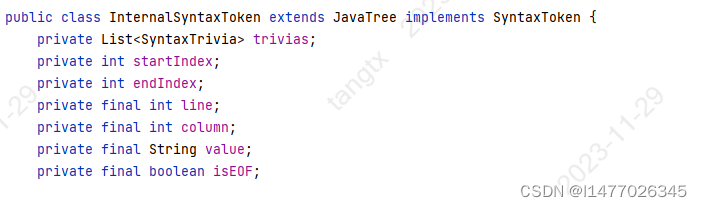
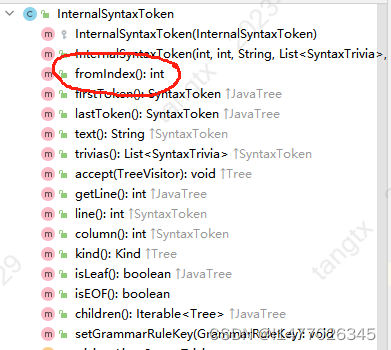

InternalSyntaxToken 这个类中有startIndex,endIndex 两个属性,fromIndex()方法可以获取到开始的下标。
有以上的发现,加上一些其他的网络资料,有一个设想,token是在文件中读出来的字符串是可以根据下标在某个字符串中截取的。
大胆假设小心验证,自己写个流,读取文件,直接把下标写进去截取下,一顿操作猛如虎,一看战绩1-5;除了开头的几个字符串正确,其他的全错了;(不信可以自己试试)
结论:sonarqube读取文件后对字符串进行了处理!plan A,找到sonarqube处理的方法,引用或者抄一份,在源码的海洋里一顿喝水,放弃;执行plan B 看代码!
java自定义规则需要实现JavaFileScanner,有方法一枚scanFile(JavaFileScannerContext var1),这个var1有木有小秘密?上图
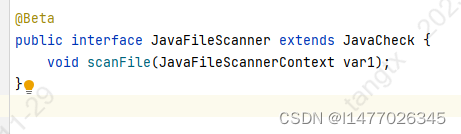
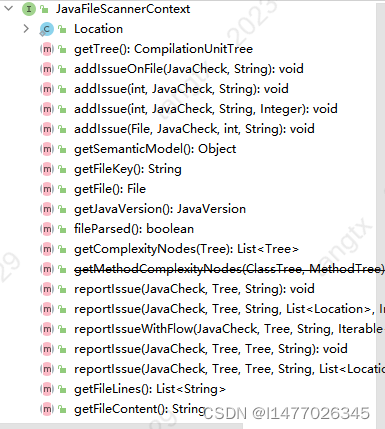
getTree()、getFile()、getFileContent()什么是惊喜,什么是惊喜,这就是惊喜,要啥给啥。
有这个,只要我们找对tree,字符串拿来了,咱们想怎样就怎样!
2.阅读源码小发现
java自定义规则继承的父类,各种visit方法各种tree参数
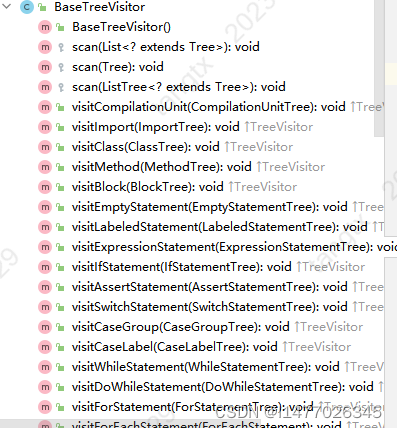
各种visit方法各种tree参数
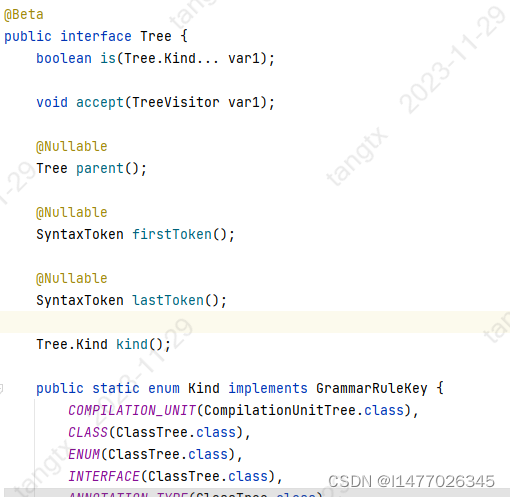
查看了几个实现类总结点小用法;
1.定位特殊情形的tree.kind()、tree.is(Kind...)
if(tree.kind().equals(Kind))或者tree.is(Kind...)判断tree代表的代码段是不是对应的情形
调用具体实现类的方法验证获取各种值进行判断处理;
如果太复杂,就直接提取tree对应的字符串,根据实际的需求,处理判断.
2.tree.accept(TreeVisitor var1)
可以把tree交给对应的visit方法();















 2094
2094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









