






一 介绍
该文指出,目前基于注意力机制的自然场景文字识别方法在OCR领域取得了很大成果,成功的主要原因是在RNN的框架下,基于注意力的方法可以学习到一维或者二维特征的内在表示。
但是这种基于这种局部注意力机制的方法却存在注意力漂移的问题,并且在RNN架构下模型无法高效的并行计算。
作者正是想在文本识别中引入全局注意力机制。为了提高模型性能和缓解注意力混淆问题,本文作者(平安产险视觉团队)等人提出了一个更高效和更鲁棒的场景文本识别方法:MASTER。
二 框架
MASTER包括两个核心模块:
(1)基于Multi-Aspect的全局上下文注意力机制的编码器;
(2)基于Transformer的解码器。
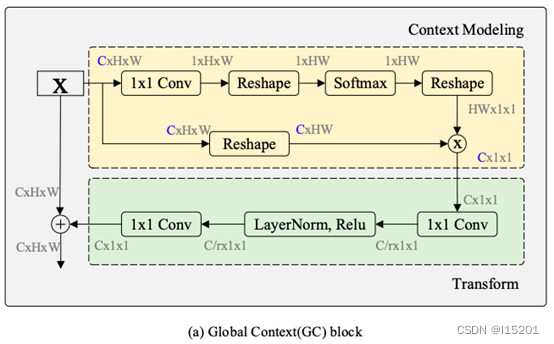
其主要分为Context Modeling 和 Transform 两大部分,并将原始特征图与Transform输出结果融合。 该文将其用于场景文本识别的注意力建模,发现如果使用多个注意力函数,可以取得更好的结果:
其核心模块如下:
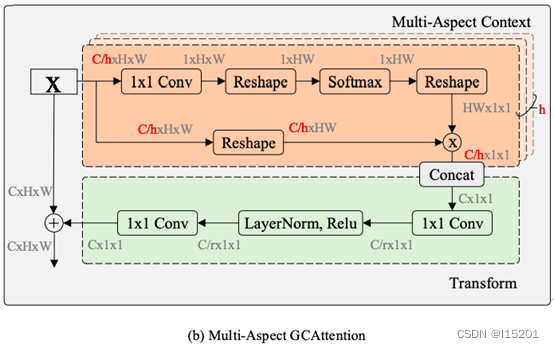
可见,创新之处在于其含有h个Context Modeling。
在解码器部分也有多处改进,主要有:
- Scaled Multi-Head Dot-Product Attention
- Masked Multi-Head Attention
- Position-wise Feed-Forward Networn
- Loss Function
MASTER架构图:(请点击查看大图)
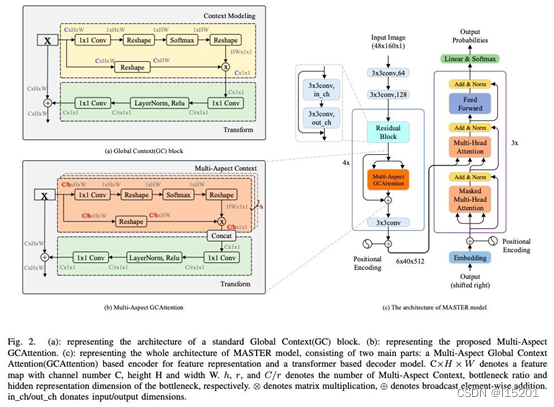
三 实验结果
作者在常见评价数据集上与State-of-the-art方法进行了比较:

可见MASTER在不区分大小写赛道取得了当前第一名的结果,并大幅超越第二名,在区分大小写赛道取得准确率指标第四的好成绩。
作者总结称MASTER方法具有如下优势:
(1)模型能够更好的学习输入和输出之间的对齐关系,并且能够在编码器内部学习特征与特征之间的依赖关系,在解码器内部学习目标与目标之间的依赖关系,缓解了注意力混淆问题;
(2)模型在公开的基准数据集上取得了SOTA水平,尤其在不规则文本数据集上刷新了准确率,表明其对图片的空间形变不敏感;
(3)训练和预测阶段使用了并行计算,更加高效。
四 荣誉

五 总结
这篇文章提出了MASTER,其主要就是用CNN+Transformer的方式实现文字识别,这篇文章的主要创新点是在CNN中参考GCnet提出了Multi-Aspect GCAttention在CNN部分进行的改进。论文结构比较清晰,如果熟悉transformer的同学应该比较清楚。
1、提出了一种新的多方面非局部块,并将其融合到传统的CNN主干中,从而使特征抽取器能够建模全局上下文。所提出的多方面非局部块可以学习空间2D注意力的不同方面,可以将其视为一个多头自注意力模块。不同类型的注意力集中在空间特征依赖的不同方面,这是不同句法依赖类型的。
2、另一种形式在推理阶段,我们引入了基于内存缓存的解码策略来加快解码过程。主要方法是删除不必要的计算并缓存以前解码时间的一些中间结果除了效率高之外
3、我们的方法在规则和不规则场景文本基准上都达到了最先进的性能。特别是,我们的方法在COCO文本数据集上实现了最佳的区分大小写性能。
文章我认为最重要的还是将transformer引入cv领域,虽然效果相比以前提出的模型有所提升,但是模型的大小,显存占用,耗时难免会有所增加。在精度和速度的平衡一直也是我们业界所攻克的方向,对于论文其余部分,还需要大家认真研读,这里也不做过多解释。
论文地址:
https://arxiv.org/pdf/1910.02562.pdf
代码地址















 2172
2172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









