







1 数据预处理与分析
在数据挖掘过程中,海量的原始数据存在大量的不一致,有缺失的数据、异常的数据、重复的数据,严重影响到数据挖掘的效率和准确率,数据清洗尤为重要,数据清洗之后进行或同时进行数据集成,转换,规约等一系列过程,该过程就是数据预处理。数据预处理一方面提高数据质量,另一方面使数据更好地适应特定的数据挖掘或者工具.
1.1 数据清理
数据清理:数据往往包含缺失值、异常值和错误值。在这一步,数据清理操作包括处理缺失值(删除或填充)、处理异常值和修复错误。
(1)数据读取,发现每列数据都缺少各自的列名于是添加相应的列名,如下图所示。
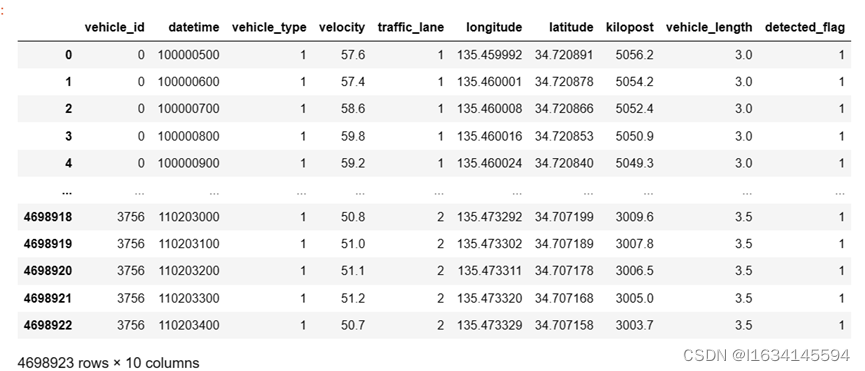
图 1-1 原始数据
从上图中我们可以发现该数据一共有4698923行10列,是一个比较大的数据集。从左到右的数据依次为车辆id、时间戳、车辆类型、速度、车道类别、经度、纬度、行驶距离、车辆长度、识别标签。
(2)发现datetime的数据格式HHMMSSFFF,为了方便后续的计算需要将此数据进行转换,于是把他转换成以0点整为起点以秒为单位且精确到小数点后一位的数据,如下图所示。
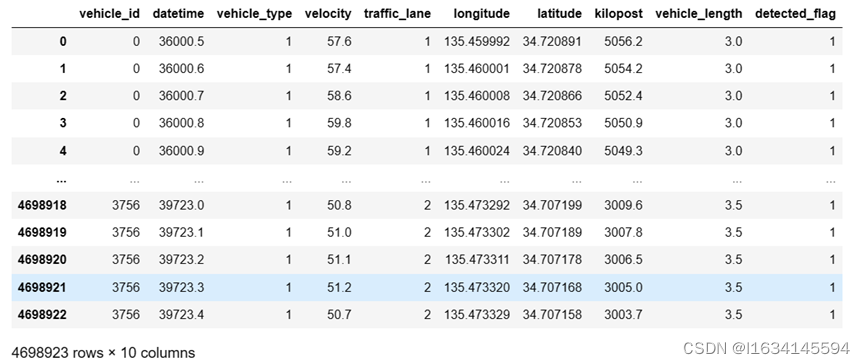
图 1-2 时间戳调整
(3)使用data.isnull().sum()查看缺失值,发现各个维度的数据缺失值数量为0,故该数据不存在缺失值不用做其处理。

图 1-3 缺失值查询
1.2 探索性数据分析
(1)使用describe()函数对原始数据进行统计性描述,如下图所示。
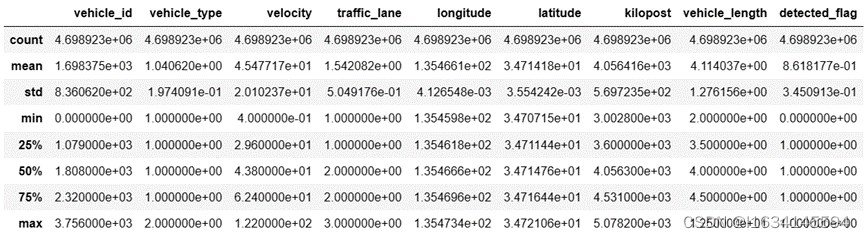
图 1-4 统计性描述
从上图中我们可以发现车辆类型在75%分位数的时候仍是1,说名该数据中绝大部分车辆为正常小型车辆,公交、客车、货车等车辆为少数符合实际道路情况。在速度数据中,速度的均值为45.48km/h,标准差为20.1,最大值最小值分别为122km/h和0.4km/h。根据标准差方法(基于数据的标准差来识别异常值),速度最大值在均值的距离3倍标准差以内,故可以初步认为速度数据不存在异常值不需要做额外处理。
(2)数据可视化分析,分别对数据绘制箱线图、小提琴图、正态分布图
速度可视化图如下所示。
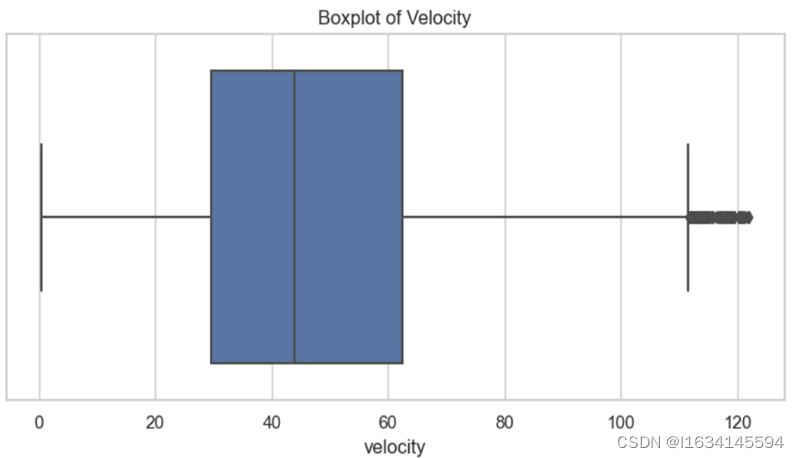
图 1-5 速度箱线图
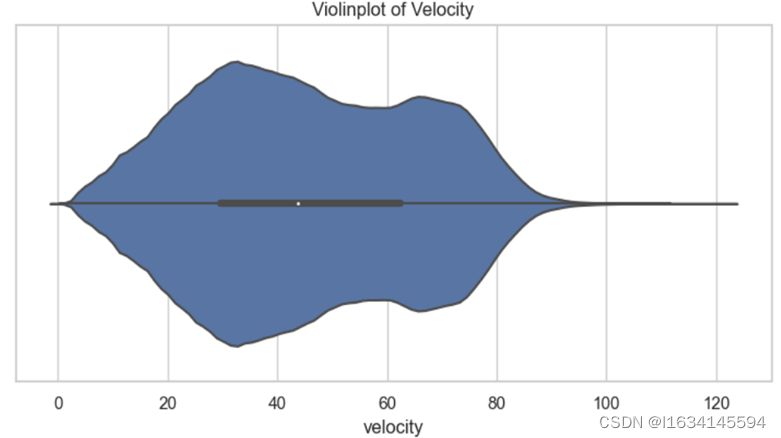
图 1-6 速度小提琴图
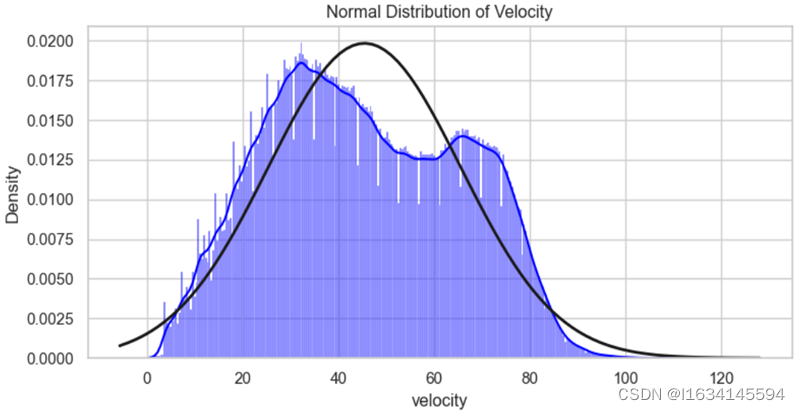
图 1-7 速度正太分布图
从上图不难发现速度主要集中在30km/h到60km/h这个范围,其中箱线图中有一部分数值较大的异常值在120km/h范围左右,个人认为可能是道路上有极少数驾驶员存在超速行为所导致,不是数据统计中所出现的人工差错,又因为数量比较少,所以不对其进行异常值处理。
车道类别可视化图如下所示。
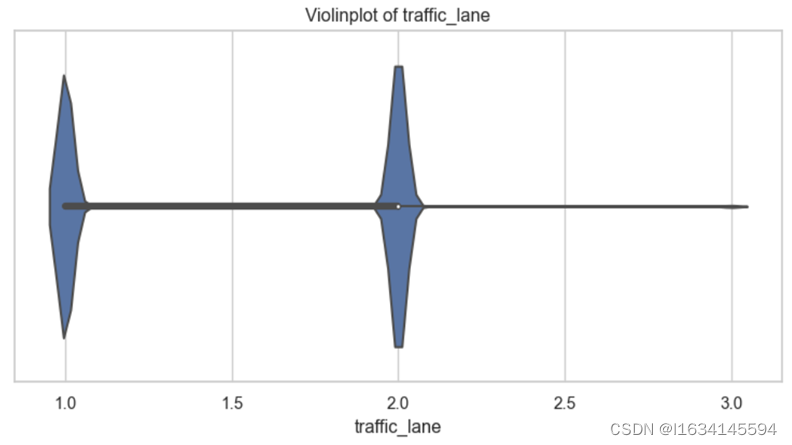
图 1-8 车道类别小提琴图
数据中车辆基本上就行驶在行车道和超车道这两个车道处,入口道的车辆数据量少不影响后续的车辆跟驰分析。
(3)相关性分析
使用Pearson皮尔逊相关系数法分析各个数据指标的相关性,以探究各指标之间是否具有线性关系。 Pearson皮尔逊相关系数可以用来度量两个变量X和Y之间的相关性。在本问题中就可以使用其来对评价指标的关联进行研究。如果两组数据X:{X1,x2,……,Xn}和Y:{Y1,Y2,……,Yn}为总体数据,而总体协方差
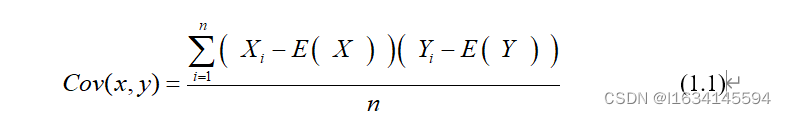
则有总体 皮尔逊相关系数:
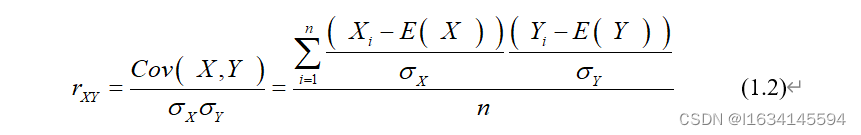
且|r|≤1。而在样本协方差和样本Pearson皮尔逊相关系数中,分母为n-1。可以将Pearson皮尔逊相关系数视为除去两个变量中量纲的影响,将X和Y标准化后的协方差,适合于数据之间的比较。但其使用的条件必须满足数据为线性联系,如果需要确定数据的显著性,则需要数据呈正态分布。使用Pearson皮尔逊相关系数法得到的相关性热力图如图下所示。
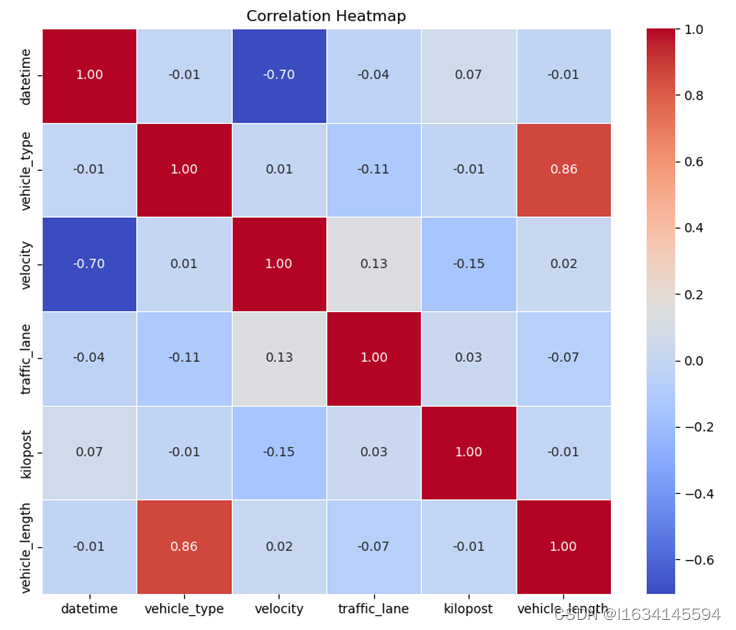
图 1-9相关性热力图
通过上图的分析,我们发现时间与速度之间的相关系数为-0.7,表明它们之间存在着明显的负线性相关性。这意味着随着时间的增加,车辆的速度有较大的可能减小,或者说时间与速度之间存在一定的反比关系。这是一个重要的观察结果,为我们深入了解驾驶行为提供了有力的线索。
此外,我们还观察到车道类别与行驶距离分别于速度之间存在微弱的相关性。这表明不同车道类别的选择和行驶距离可能在一定程度上与车辆的速度有关。这些微弱的相关性提示了可能存在一些影响因素,需要在进一步的分析中深入挖掘。
然而,对于其他数据,我们判定它们之间不存在明显的相关关系。这包括诸如加速度、速度的标准差等变量。这意味着这些变量可能是相对独立的,对于速度和时间之间的关系并没有显著的影响。
因此,结合速度、时间、车道类别和行驶距离的相关性分析,我们可以得出这些变量在一定程度上相互关联,并且它们之间的关系可以为后续的驾驶跟驰分析提供充分的数据支持。这有助于更好地理解驾驶行为的动态变化。
2 驾驶员驾驶行为类型划分方法及结果分析
驾驶员驾驶行为类型的划分涉及到多个方面的因素,包括车辆的速度、加速度、刹车、转弯、驾驶姿势等。这种划分通常是为了评估驾驶行为的安全性、效率以及对燃油经济性的影响。根据所提供的数据内容,本次驾驶行为划分主要以熟读加速度为研究方面
2.1 特征工程
2.1.1 特征选取
在原始数据中,我们注意到可用的特征数据维度较少,这促使我们进行特征工程处理。特征工程旨在增加一些有用的特征,同时去除一些无用的特征,以更好地揭示数据中的驾驶行为特征信息,对于后续的驾驶行为分析提供了更丰富和准确的数据基础,有助于揭示驾驶行为的更深层次信息。特征工程的质量直接关系到后续分析处理的准确性和有效性,因此对于特征的选择至关重要
因此,为了进一步丰富原有的速度数据和时间数据,我们引入了一系列新的特征参数,以更全面地描绘驾驶行为的动态变化。这些新增的特征数据包括:平均速度vav、最大速度vmax、最小速度vmin、速度标准差vsd、瞬时加速度a、平均正加速度apav、平均负加速度anav、加速度标准差asd、最大加速度amax、最小加速度amin、恒速时间比例Pc、加速时间比例Pa、减速时间比例Pd等13个特征参数。它们的定义如下:

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









