







写在前面:2020年找到工作,转岗JAVA大数据。之前写前后端,约等于从零开始,所以仅记录一下自己的学习路线,免得以后忘了~
Hadoop 3.3.0配置伪分布式
一、
1.1 准备工作
在虚拟机上装好centOS8,注册用户hadoop

在主文件夹中新建文件夹app,将下载好的hadoop3.3.0.tar.gz与jdk一同传入虚拟机中。(使用vmware tools)

解压程序包,命令:tar –zxvf (file_name)
创建软链接,命令:ln -s (file_name)

1.2:配置jdk环境变量
命令:su root ,切换到管理员用户
再输入:vim /etc/profile
输入:
export JAVA_HOME=/home/hadoop/app/jdk/jdk-14.0.2
export JAVA_JRE=JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/lib
export PATH=$PATH:$JAVA_HOME/bin

退出并保存:wq(vim命令)
再输入:source /etc/profile ,使修改生效
查询java版本:java -version

能查询到版本,则代表jdk环境配置成功。
1.3 测试单机模式hadoop
切换到hadoop文件夹

输入:bin/hadoop version
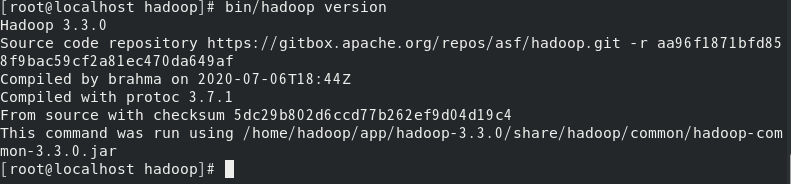
可以看到hadoop版本为3.3.0。
新增一个测试文件test.txt在hadoop根目录,并且输入一些英文单词:

运行hadoop自带的wordcount程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount test.txt output
mapreduce程序将读取text.txt,输出在根目录下。
查看运行结果:
二、配置伪分布式
回到hadoop用户,修改配置文件:
进入etc/hadoop,

修改core-site.xml,添加以下内容:
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
<!-- hdfs主机名与端口号 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoop/data/tmp</value>
<!-- NameNode、DataNode等默认存放临时数据的地址 -->
</property>
修改hdfs-site.xml:
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/data/dfs/name</value>
<!--设置hdfs中NameNode的路径 -->
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/data/dfs/data</value>
<!--设置hdfs中DataNode的路径 -->
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<!--设置数据块副本数-->
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
<!--设置hdfs访问权限检查设置为false -->
</property>
修改mapred-site.xml:
<property>
<name>mapreduce.frameword.name</name>
<value>yarn</value>
</property>
修改yarn-site.xml:
<property>
<name>yarn.nodemanager.aux-servies</name>
<value>mapreduce_shuffle</value>
</property>
修改hadoop-env.sh:
export JAVA_HOME=/home/hadoop/app/jdk/jdk-14.0.2
配置hadoop环境变量:vim ~/.bashrc
添加:
JAVA_HOME=/home/hadoop/app/jdk/jdk-14.0.2
HADOOP_HOME=/home/hadoop/app/hadoop
CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools/jar
PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH HADOOP_HOME
输入命令:source ~/.bashrc,使修改生效
创建配置好的hadoop文件夹:
回到Hadoop目录,输入:
bin/hdfs namenode -format
,格式化NameNode,仅在第一次安装hadoop集群需要格式化。
启动hadoop伪分布式集群
先要做一步准备工作:安装ssh
yum -y install openssh-clients (如果已经安装则不必要)
ssh-keygen
一路回车
将生成的密钥发送到本机

测试免密登录是否成功:
ssh localhost

启动集群:
回到hadoop根目录,输入:
sbin/start-all.sh
启动完成后,输入jps查看进程:
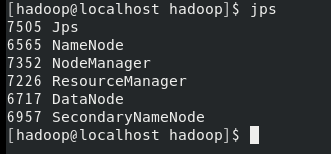
访问http://localhost:9870/

看到该网页表示启动成功~
在hdfs上创建文件夹,并放入测试文件:

也可以在网页端操作:

在伪分布式上运行hadoop自带的wordcount程序:
hadoop jar /home/hadoop/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /data/test.txt /output
如果出现了清理stage缓存时 No such file or dictionary 的错误,则
1:bin/hdfs namenode -format
2:https://www.cnblogs.com/ya-qiang/p/9494986.html
有时候我们start-
dfs.sh启动了hadoop但是发现datanode进程不存在 一、原因 当我们使用hadoop namenode
-format格式化namenode时,会在namenode数据文件夹(这个文件夹为自己配置文件中dfs.name.dir的路径)中保存一个current/VERSION文件,记录clusterID,datanode中保存的current/VERSION文件中的clustreID的值是上一次格式化保存的clusterID,这样,datanode和namenode之间的ID不一致。二、解决方法 第一种:如果dfs文件夹中没有重要的数据,那么删除dfs文件夹,再重新运行下列指令:
(删除节点下的dfs文件夹,为自己配置文件中dfs.name.dir的路径)
第二种:如果dfs文件中有重要的数据,那么在dfs/name目录下找到一个current/VERSION文件,记录clusterID并复制。然后dfs/data目录下找到一个current/VERSION文件,将其中clustreID的值替换成刚刚复制的clusterID的值即可;
三、总结 其实,每次运行结束Hadoop后,都应该关闭Hadoop. stop-dfs.sh
下次想重新运行Hadoop,不用再格式化namenode,直接启动Hadoop即可 start-dfs.sh
3:还不行,那就切换管理员账户,删除/tmp/hadoop文件试试,或者重启linux一次。
查看运行结果:bin/hdfs dfs -cat /output/part-r-00000

全文完。















 161
161











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









