







 本文介绍了Python编程中的工程化实践,包括如何导入和组织模块,创建库,以及使用requests进行爬虫示例。还探讨了FastAPI在后端开发中的应用,涉及HTTP请求、参数处理、跨域设置等内容。
本文介绍了Python编程中的工程化实践,包括如何导入和组织模块,创建库,以及使用requests进行爬虫示例。还探讨了FastAPI在后端开发中的应用,涉及HTTP请求、参数处理、跨域设置等内容。
我们直接学了python基础了,今天来看看python的工程化与import
我们在写好代码以后,比如封装好了一些功能比如add、del这种方法以后,我们全部写在一个python文件里面是非常臃肿的,这个时候可以把这些函数放到任意一个.py文件里面去,然后使用import 文件名称就可以导入了,这样子就可以把代码和一些常用功能分离出来。
那么如果我们有多个py文件呢?每一次导入也非常的麻烦,这个时候我们可以用到python的一个概念叫做库,也就是lib,在文件夹下面新建一个__init__.py文件,那么这个就可以构成一个库了,__init__.py文件里面可以先导入那些基础的包,然后这个时候导入这个库,就可以导入那些基础的包了。这里给出一段示例代码
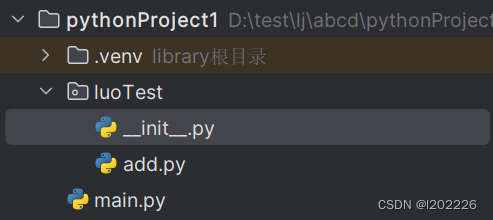
# main.py文件内容
import luoTest
print(luoTest.add(1, 2))
# add.py文件内容
def add(a, b):
return a + b
# __init__.py文件内容
# 这里要有一个点,表示从当前位置开始
from .add import add
可以创建同样的目录来跑一下,那么我们的库就已经了解完毕了。接下来就是一些具体方向的库了,这里只介绍一些方向和基础使用
python爬虫方向
推荐使用requests,requests安装之后可以很轻松的进行发送请求,这里举一个例子,某易招嫖
浏览器f12是打开控制台,在这里有很多功能和小图标,我们这里介绍一个爬虫的完整流程。
我这里一个个解释这些东西都是干什么的,元素是当前的页面所展示dom结构,这个的稍微会有些前端的知识,然后就是这个控制台,这是一个js的控制台,可以执行js代码,在这里面和浏览器共用同一个环境,可以访问到当前页面的所有内容,可以配合断点的时候执行js代码来查看
浏览器f12控制台解释

然后就是这个网络部分,浏览器发送的请求都会在这个网络部分,都可以看到,一般来说我们需要的数据就是通过这个网络,然后一步步定位到发送的包的位置上面去,然后再进行分析。其他的基本上用不到,这里再说一个有一个源代码,这个地方就是js代码执行的地方,我们可以在这里打上断点,然后调试。可以打条件断点,日志断点,还可以修改它执行的js代码并且保存(这里需要其他的操作),还可以直接导入js代码去运行,以hook一些参数比如cookie这些的。以上这些需要一定的前端基础,需要学会html和js,css(选学)才可以更好的进行爬虫。
爬虫的hello world
然后这里来示范一下某易社会招聘,这个比较简单,我们首先打开f12,然后页面刷新(这个时候网络包也会全部刷新,我们打开控制台之后网络这个模块才可以抓包的)
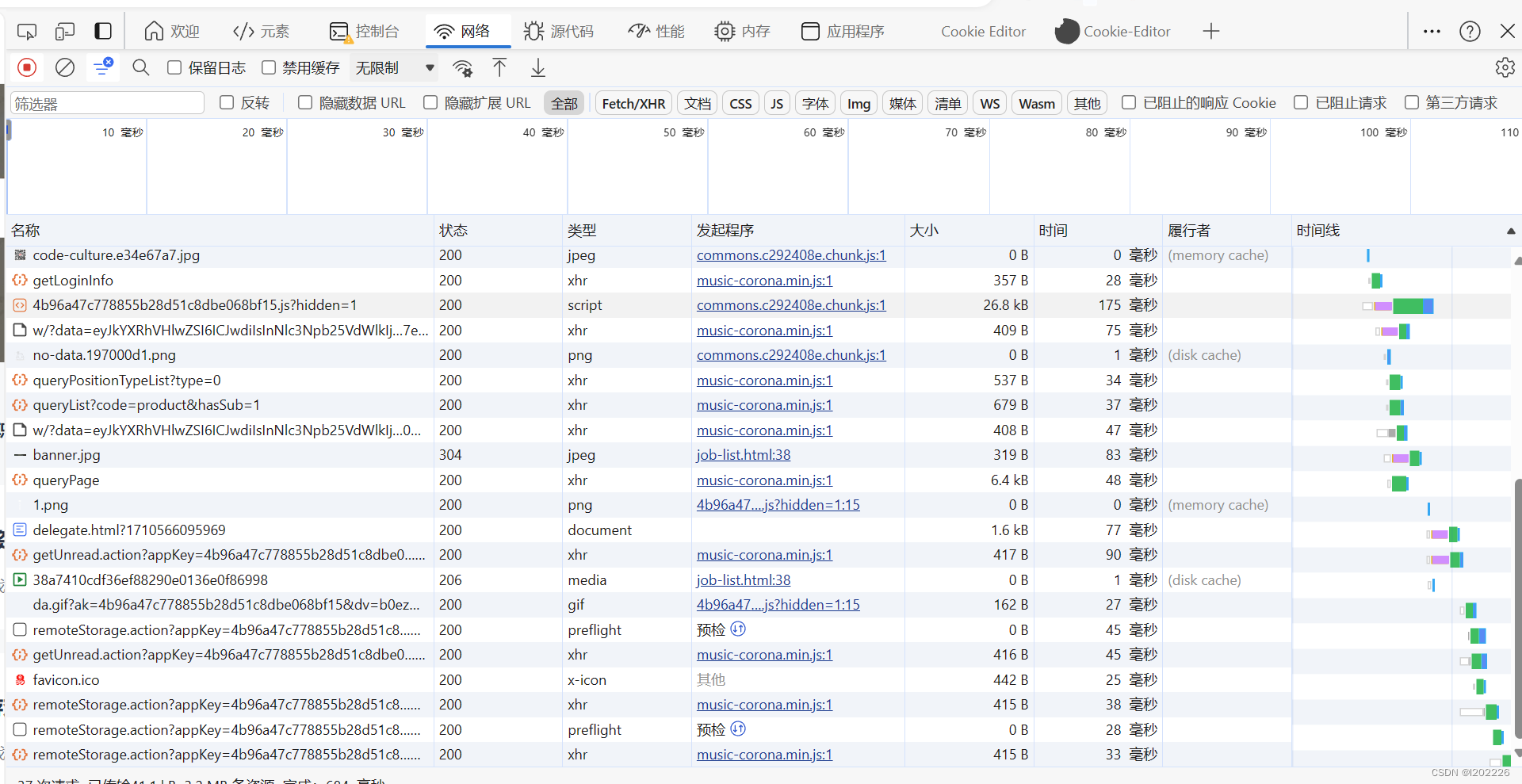
接下来就简单了,点击任何一个包,然后ctrl+f全局搜索,搜索你想要的关键字
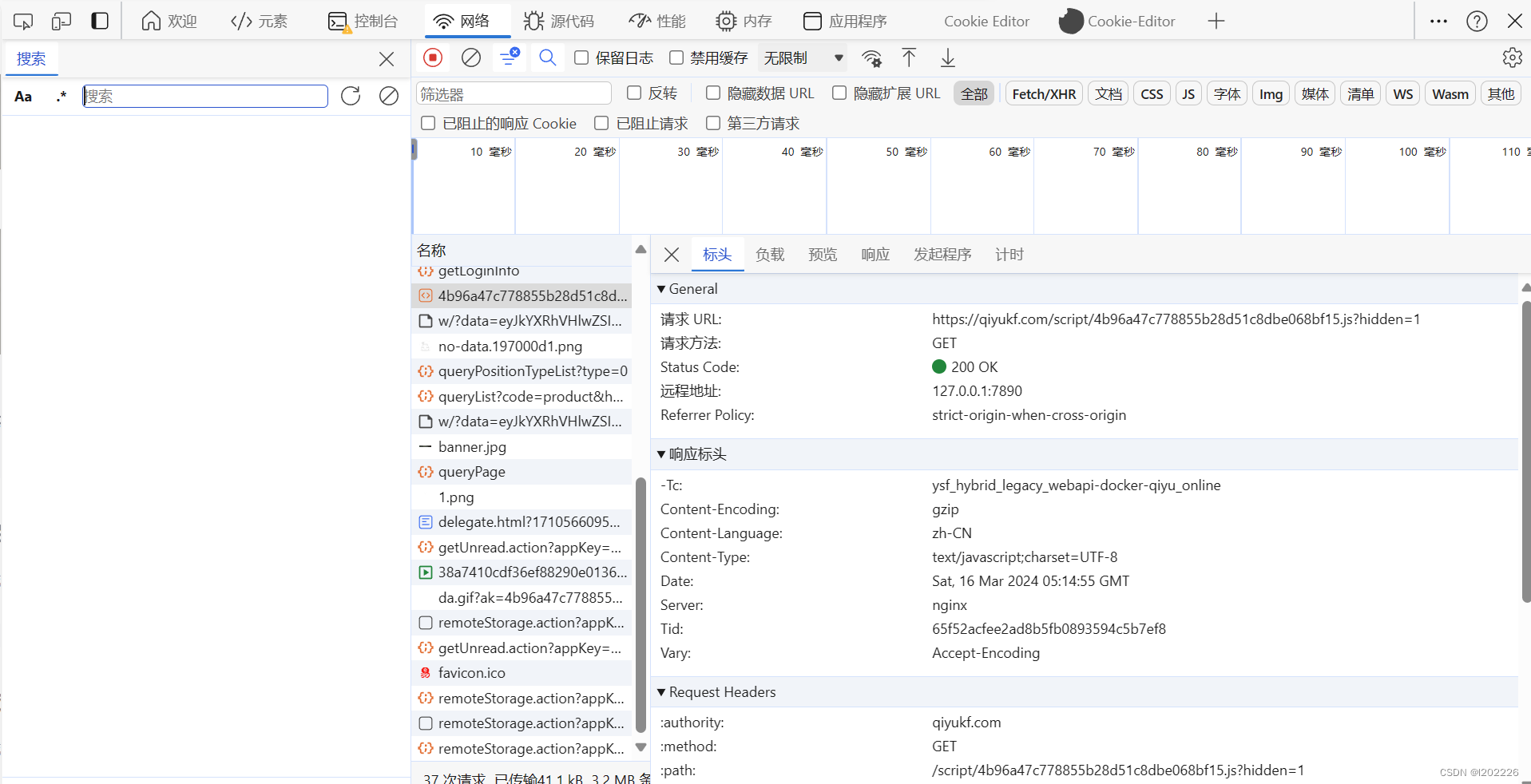
这个时候出来包再去点击它,然后我们就看到了这个包的具体内容,也看到了我们需要的具体数据。

curl解释
接下来就比较高级的操作了,我们windows一般都自带有curl,这个是windows自带的网络工具,可以使用curl https://www.baidu.com来测试一下这个curl,你可以看到html内容输出。
然后在这里之后我们右键点击这个包,然后复制为cURL(bash)
在这个网站在线curl命令转代码 (lddgo.net)把我们的curl复制过去,然后转换成为python我们就得到了python代码,这个时候我们的python代码就得到了。这个时候使用pycharm打开就可以看到了我们的python代码,并且在后面可以增加print(response.json()),来看到打印出来的内容,这个时候就是成功了,这里也给出代码。
代码
import requests
cookies = {
'_ntes_nnid': 'e5fa3effa4193fa01e4938f331b5b4cc,1704708506503',
'_ntes_nuid': 'e5fa3effa4193fa01e4938f331b5b4cc',
'hb_MA-9ADA-91BF1A6C9E06_source': 'www.bing.com',
'hb_MA-8E16-605C3AFFE11F_source': 'www.bing.com',
'hb_MA-AC55-420C68F83864_source': 'www.bing.com',
'userName': '',
'accountType': '',
}
headers = {
'authority': 'hr.163.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'authtype': 'ursAuth',
'content-type': 'application/json;charset=UTF-8',
# Requests sorts cookies= alphabetically
# 'cookie': '_ntes_nnid=e5fa3effa4193fa01e4938f331b5b4cc,1704708506503; _ntes_nuid=e5fa3effa4193fa01e4938f331b5b4cc; hb_MA-9ADA-91BF1A6C9E06_source=www.bing.com; hb_MA-8E16-605C3AFFE11F_source=www.bing.com; hb_MA-AC55-420C68F83864_source=www.bing.com; userName=; accountType=',
'lang': 'zh',
'origin': 'https://hr.163.com',
'referer': 'https://hr.163.com/job-list.html',
'sec-ch-ua': '"Chromium";v="122", "Not(A:Brand";v="24", "Microsoft Edge";v="122"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36 Edg/122.0.0.0',
}
json_data = {
'currentPage': 1,
'pageSize': 10,
}
response = requests.post('https://hr.163.com/api/hr163/position/queryPage', cookies=cookies, headers=headers, json=json_data)
print(response.json())
我们的第一个爬虫程序就这个样子出来了,还是比较简单的,这个就是爬虫的hello world程序,后续我会继续提供相关爬虫内容,请关注点赞收藏我。
python后端方向
后端是什么呢?简单来说就是负责跟数据库交互,然后获取数据的。那么数据库是什么呢?可以理解为数据是多张excel表格的总结.。
那么python做后端最好的库是什么呢?这里推荐的是fastapi,它是python专门用来做后端的,非常的好用,这里继续给出这个后端的内容。
后端目前来说无非就是获取参数,返回结果。fastapi它会自动处理返回结果,这里就不提供了,只提供一些基础的代码。
基础使用
from fastapi import FastAPI, File, Form, UploadFile, Path, Query
from pydantic import BaseModel
from typing import List, Optional
app = FastAPI()
# GET请求接收查询参数和路径参数
@app.get("/items/{item_id}")
async def read_item(item_id: int = Path(..., title="The ID of the item to get"),
q: Optional[str] = Query(None, alias="item-query")):
return {"item_id": item_id, "q": q}
# POST请求接收JSON格式数据
class Item(BaseModel):
name: str
description: Optional[str] = None
price: float
tax: Optional[float] = None
@app.post("/items/")
async def create_item(item: Item):
return {"name": item.name, "price": item.price}
# POST请求接收表单数据
@app.post("/login/")
async def login(username: str = Form(...), password: str = Form(...)):
return {"username": username}
# POST请求上传单个文件
@app.post("/uploadfile/")
async def upload_file(file: UploadFile = File(...)):
return {"filename": file.filename}
# POST请求上传多个文件
@app.post("/uploadfiles/")
async def upload_files(files: List[UploadFile] = File(...)):
return {"filenames": [file.filename for file in files]}
接收post请求参数为json
这里再给出一个直接的接收参数为json的
from fastapi import FastAPI, Request
app = FastAPI()
@app.post("/items/")
async def create_item(request: Request):
data = await request.json() # 将请求体解析为字典
# 现在你可以像处理普通字典那样处理data了
return {"received_data": data}
上传多个图片
上传多个图片内容的
from typing import List
from fastapi import FastAPI, File, UploadFile
app = FastAPI()
@app.post("/upload-multiple-images/")
async def create_upload_files(files: List[UploadFile] = File(...)):
return {"filenames": [file.filename for file in files]}
返回图片
返回图片的
from fastapi import FastAPI, File, UploadFile, HTTPException
from fastapi.responses import FileResponse
app = FastAPI()
@app.get("/get-image/")
def get_image():
image_path = "path/to/your/image.jpg" # 替换为你的图片路径
try:
return FileResponse(image_path, media_type='image/jpeg')
except FileNotFoundError:
raise HTTPException(status_code=404, detail="Image not found")
动态返回图片的
from fastapi import FastAPI, Response
from some_image_library import generate_image # 假设的库和函数,用于生成图片
app = FastAPI()
@app.get("/dynamic-image/")
def dynamic_image():
image_bytes = generate_image() # 生成图片数据的字节串
return Response(content=image_bytes, media_type="image/png")
cookie和session的
控制cookie和session的
from fastapi import FastAPI, Cookie, Response
app = FastAPI()
@app.get("/set-cookie/")
def set_cookie(response: Response):
response.set_cookie(key="mycookie", value="cookievalue", httponly=True)
return {"message": "Cookie is set"}
@app.get("/get-cookie/")
def get_cookie(mycookie: str = Cookie(None)):
return {"mycookie": mycookie}
# 这将在内存中存储会话数据
SESSIONS = {}
@app.post("/login/")
def login(response: Response):
session_id = str(uuid4())
SESSIONS[session_id] = {"user": "username", "role": "user"} # 示例会话数据
response.set_cookie(key="session_id", value=session_id, httponly=True)
return {"message": "User logged in"}
@app.get("/user/")
def get_user(session_id: str = Cookie(None)):
if session_id not in SESSIONS:
raise HTTPException(status_code=401, detail="Unauthorized")
user_session = SESSIONS[session_id]
return user_session
中间键
再给一个中间键的
from fastapi import FastAPI
from starlette.middleware.base import BaseHTTPMiddleware
from starlette.requests import Request
from starlette.responses import Response
import time
app = FastAPI()
class CustomMiddleware(BaseHTTPMiddleware):
async def dispatch(self, request: Request, call_next):
start_time = time.time()
# 这里可以在请求处理前执行一些操作
print(f"Request path: {request.url.path}")
response = await call_next(request)
# 请求处理后,可以在响应上执行一些操作
process_time = time.time() - start_time
response.headers['X-Process-Time'] = str(process_time)
return response
# 将中间件添加到FastAPI应用中
app.add_middleware(CustomMiddleware)
@app.get("/")
async def main():
return {"message": "Hello World"}
跨域处理
再来一个跨域处理的例子
from fastapi import FastAPI
from fastapi.middleware.cors import CORSMiddleware
app = FastAPI()
# 允许的来源列表,使用具体的来源地址或者使用'*'来允许所有来源
origins = [
"http://localhost:3000", # 假设你的前端运行在这个地址
"https://www.example.com",
# 你可以添加更多的来源
]
app.add_middleware(
CORSMiddleware,
allow_origins=origins, # 允许访问的来源列表
allow_credentials=True, # 是否支持cookies跨域
allow_methods=["*"], # 允许的HTTP方法,['GET', 'POST'] 或使用'*'允许所有
allow_headers=["*"], # 允许的HTTP头,['X-Custom-Header'] 或使用'*'允许所有
)
@app.get("/")
async def main():
return {"message": "Hello World"}















 333
333











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









