









DrissionPage 是一个基于 python 的网页自动化工具。
它既能控制浏览器,也能收发数据包,还能把两者合而为一。
可兼顾浏览器自动化的便利性和 requests 的高效率。
它功能强大,内置无数人性化设计和便捷功能。
它的语法简洁而优雅,代码量少,对新手友好。
上代码
提示:第一次需要将登陆函数打开
import random
import time
from urllib.parse import quote
from DrissionPage import ChromiumPage
from DrissionPage.errors import ElementNotFoundError
from tqdm import tqdm
import pandas as pd
def sign_in():
sign_in_page = ChromiumPage()
sign_in_page.get('https://www.xiaohongshu.com')
print("请扫码登录")
# 第一次运行需要扫码登录
time.sleep(20)
def search(keyword):
global page
page = ChromiumPage()
page.get(f'https://www.xiaohongshu.com/search_result?keyword={keyword}&source=web_search_result_notes')
def page_scroll_down():
print("********下滑页面********")
# 生成一个随机时间
random_time = random.uniform(0.3, 1)
# 暂停
time.sleep(random_time)
# time.sleep(1)
# page.scroll.down(5000)
page.scroll.to_bottom()
def get_item():
# 定位包含笔记信息的sections
container = page.ele('.feeds-page')
sections = container.eles('.note-item')
get_info(sections)
def get_info(sections):
for section in sections:
if len(section.eles('tag:a')) > 0:
# 定位文章链接
note_link = section.ele('tag:a', timeout=0).link
if note_link in existences:
break
try:
# 定位标题、作者、点赞
footer = section.ele('.footer', timeout=0)
# 定位标题
title = footer.ele('.title', timeout=0).text
# 定位作者
author_wrapper = footer.ele('.author-wrapper')
author = author_wrapper.ele('.author').text
# 定位作者主页地址
author_link = author_wrapper.ele('tag:a', timeout=0).link
# 定位作者头像
author_img = author_wrapper.ele('tag:img', timeout=0).link
# 定位点赞
like = footer.ele('.like-wrapper like-active').text
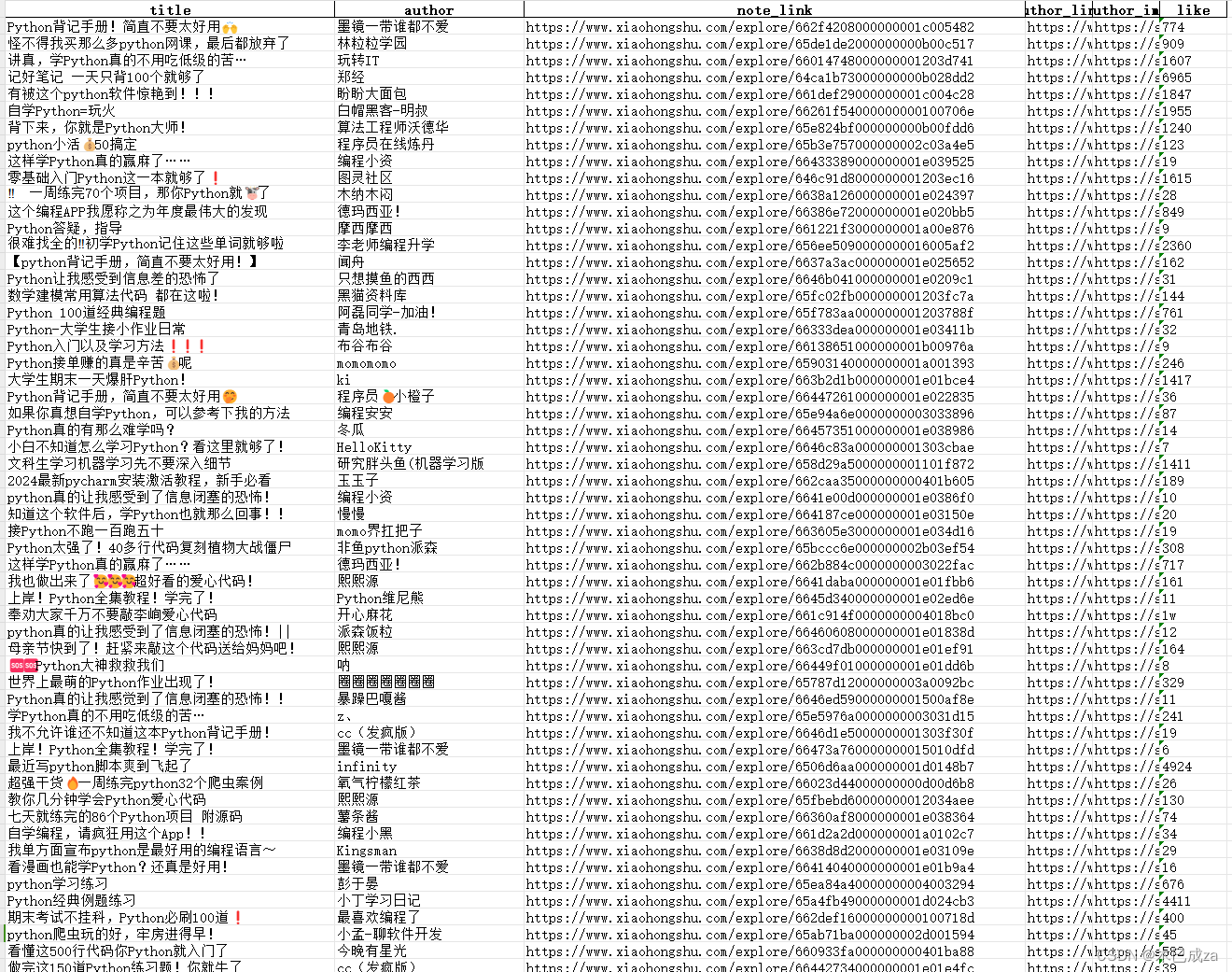
print(note_link, title, author, like)
contents.append([title, author, note_link, author_link, author_img, like])
existences.append(note_link)
except ElementNotFoundError as e:
print(note_link + "失败")
def craw(times):
for i in tqdm(range(1, times + 1)):
get_item()
page_scroll_down()
def save_to_excel(data, excel_path):
# 保存到excel文件
name = ['title', 'author', 'note_link', 'author_link', 'author_img', 'like']
df = pd.DataFrame(columns=name, data=data)
df.to_excel(excel_path, index=False)
if __name__ == '__main__':
# contents列表用来存放所有爬取到的信息
contents = []
# existence列表用来存放所有爬取过的信息
existences = []
# 搜索关键词
keyword = "python"
# 文件保存路径
excel_path = "小红书" + keyword + "搜索结果.xlsx"
# 设置向下翻页爬取次数
times = 20
# 第1次运行需要登录,后面不用登录,可以注释掉
# sign_in()
# 关键词转为 url 编码
keyword_temp_code = quote(keyword.encode('utf-8'))
keyword_encode = quote(keyword_temp_code.encode('gb2312'))
# 根据关键词搜索小红书文章
search(keyword_encode)
try:
# 根据设置的次数,开始爬取数据
craw(times)
# 爬到的数据保存到本地excel文件
finally:
save_to_excel(contents, excel_path)
DrissionPage 太牛了!
















 799
799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









