










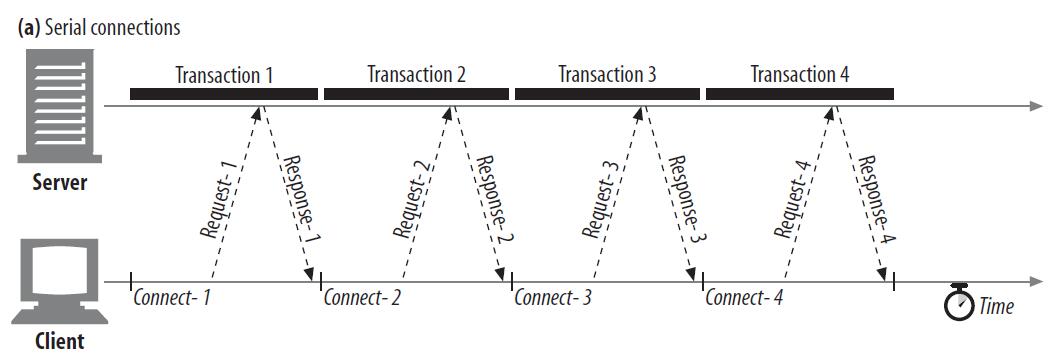
HTTP连接的建立需要时间。如果我们要从一台服务器上获取4个文件,获取每个文件都要重新建立连接来获取数据,这势必会降低文件下载效率,因为有一部分时间花费在建立连接上了,而不是真正在传输有用数据,如图a所示:
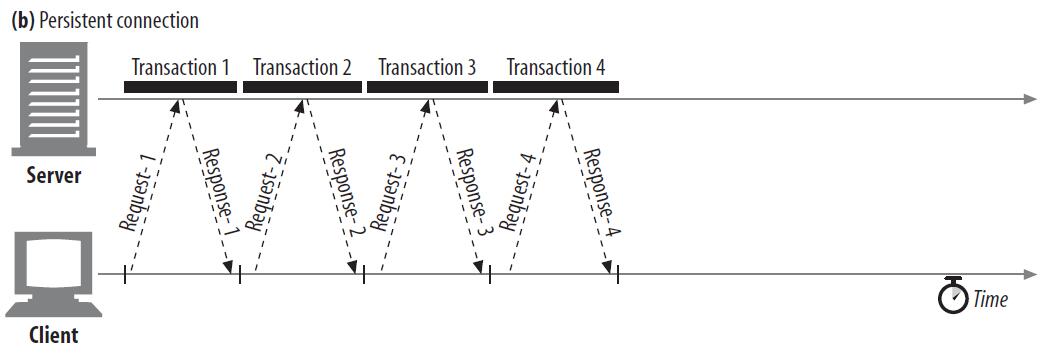
如果我们能建立一个连接,传输完所有四个文件,再关闭连接,必然会增加文件下载效率,因为节省了多次建立连接的开销,持久连接就是这样的连接,它的工作方式如图b所示:
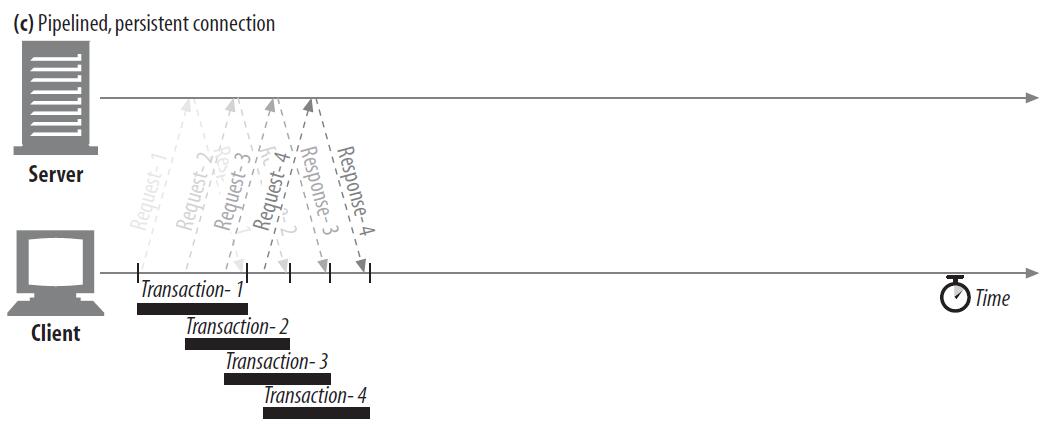
简单的持久连接有个问题,就是每次都要等到我们获得了上一次请求的响应之后,才能发起下一次连接,这导致请求的时候,输入流是完全闲置的,获取响应的时候,输出流是完全闲置的。如果我们能一边发送请求,一边接收响应,这必然能更加充分的利用这个连接,可以被这样使用的持久连接叫做管道化连接,它的工作方式如图c所示:
下面给出的Java代码是通过一个管道化连接从服务器上获取多个文件的示例:
package socket;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.Socket;
import java.net.UnknownHostException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
public class ReuseSocket {
public static void main(String[] args) throws UnknownHostException,
IOException {
String host = "www.cnblogs.com";
int port = 80;
String path = "/chenying99/p/3735282.html";
String path2 = "/everSeeker/p/5462853.html";
String result = getByPipePipelinedConnection(host, port, path, path2);
writeFile(result, "d:/test/pipelined.html", "utf-8");
}
/**
* 通过一个管道化连接获取host指定的主机上paths指定的所有文件
* @param host 主机名
* @param port 端口
* @param paths host指定的主机上的文件路径集合
* @return 服务器返回的结果
* @throws UnknownHostException
* @throws IOException
*/
public static String getByPipePipelinedConnection(String host, int port,
String...paths) throws UnknownHostException, IOException {
StringBuilder lines = new StringBuilder();
try(Socket socket = new Socket(host, port);
// 输出流
PrintWriter printWriter = new PrintWriter((new OutputStreamWriter(
socket.getOutputStream(), "utf-8")));
// 输入流
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(
socket.getInputStream(), "utf-8"));
) {
for (String path : paths) {
String requestHead = generateRequestHead(host, path);
printWriter.println(requestHead);
printWriter.flush();
}
String line = null;
while ((line = bufferedReader.readLine()) != null) {
lines.append(line);
lines.append(System.lineSeparator());
}
}
return lines.toString();
}
/**
*
* @param host 主机名
* @param path 主机上某个文件的路径
* @return 获得host指定主机上的path指定的文件的请求头
*/
private static String generateRequestHead(String host, String path) {
StringBuffer requestHeader = new StringBuffer();
requestHeader
.append("GET " + path + " HTTP/1.1\n")
.append("Accept: text/html, application/xhtml+xml, */*\n")
.append("Accept-Language:zh-CN,zh;q=0.8\n")
.append("User-Agent: Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.2; WOW64; Trident/6.0)\n")
.append("HOST:" + host + "\n")
.append("\n");
return requestHeader.toString();
}
/**
* 把字符串写进文件,文件已经存在会覆盖原文件
* @param content 字符串
* @param pathName 文件路径名
* @param charsetName 字符集
*/
private static void writeFile(String content, String pathName, String charsetName) {
Path path = Paths.get(pathName);
try {
Files.write(path, content.getBytes(charsetName), StandardOpenOption.CREATE);
} catch (IOException e) {
e.printStackTrace();
}
}
}
想更细致的了解管道化连接,可以阅读《HTTP权威指南》4.6节,本文的图也来自这本书。















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









