







堆排序
注:堆排序涉及到二叉树,对二叉树还不了解到小伙伴建议先看看树和二叉树
什么是堆
- 在学习堆排序之前,我们要先知道堆是什么
- 堆的逻辑结构是一棵完全二叉树
- 堆的物理结构是一个数组
- 即我们可以将堆看成是一棵完全二叉树的顺序存储
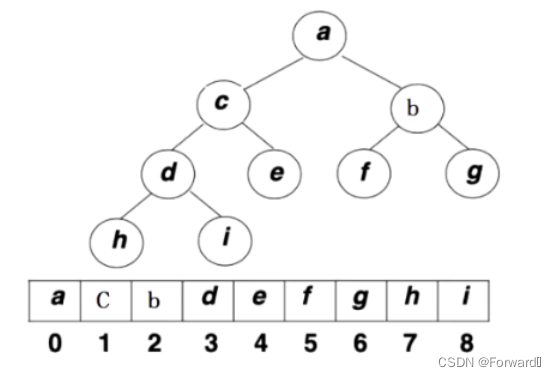
父子节点的关系
- 我们可以通过数组的下标来确定父子节点的关系,结论如下
leftchild = parent * 2 + 1rightchild = parent * 2 + 2parent = (child - 1) / 2
堆的两个特性
-
结构性:用数组表示的完全二叉树
-
有序性:任意节点的关键值是其子树所有节点的最大值(或最小值)
- ”最大堆(MaxHeap)“,也叫”大顶堆“:最大值,即每棵子树的根节点的值都大等于于其子节点的值
- ”最小堆(MaxHeap)“,也叫”小顶堆“:最小值,即每棵子树的根节点的值都小于等于其子节点的值
-
例如上图,是小顶堆
-
又例如:
(101, 88, 46, 70, 34, 39, 45, 58, 66, 10)是大堆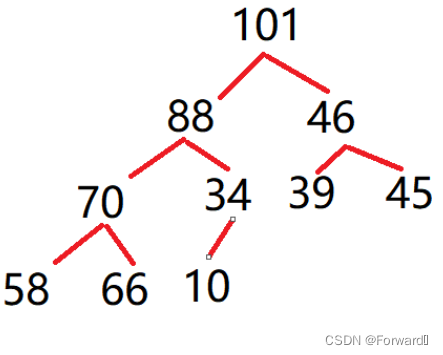
怎么堆排序
- 堆排序实际上也是一种选择排序,只是利用了堆来提高了效率
建堆
-
假设我们要对一个乱序数组进行堆排序,那么首先就要在这个数组的基础上建立大堆或小堆
-
我们以建小堆为例:
-
由于堆这一概念基于完全二叉树,因此我们先要将数组看成完全二叉树的形式,如对于数组
{27,15,19,18,28,34,65,49,25,37}: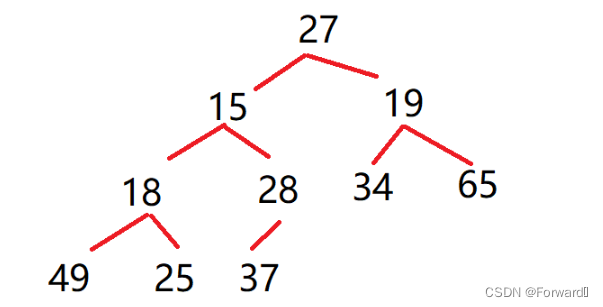
-
接下来我们就采用向下调整算法来实现先建堆
-
向下调整算法:
-
使用前提:左右子树都是小堆
-
步骤:从根节点开始,选出左右孩子值较小的那一个并跟父亲比较,如果小于,那么就交换父亲节点和较小值节点的值,然后继续向下调整,调到叶子节点或父亲小于较小值就终止
-
具体过程如图所示:

-
向下调整算法代码实现
void AdjustDown(int *nums, int numsSize, int root)
{
int parent = root;
int child = parent * 2 + 1; //首先默认左右孩子的较小值是左孩子,然后再在循环里判断取值
while ( child < numsSize)
{
//如果右孩子小于左孩子,那么child取值为右孩子的下标
if (child + 1 < numsSize &&nums[child] > nums[child + 1])
child += 1;
//如果字节点的值小于父节点,那么就交换这两个值
if (nums[child] < nums[parent])
{
Swap(&nums[child], &nums[parent]); //Swap需要自己实现
//继续向下调整
parent = child;
child = parent * 2 + 1;
}
//如果没有交换子节点和父节点,就说明这已经是一个小堆
else
break;
}
}
- 如果是建大堆,则将代码改为:
void AdjustDown(int *nums, int numsSize, int root)
{
int parent = root;
int child = parent * 2 + 1; //首先默认左右孩子的较小值是左孩子,然后再在循环里判断取值
while ( child < numsSize)
{
//如果右孩子大于左孩子,那么child取值为右孩子的下标
if (child + 1 < numsSize &&nums[child] < nums[child + 1])
child += 1;
//如果字节点的值大于父节点,那么就交换这两个值
if (nums[child] > nums[parent])
{
Swap(&nums[child], &nums[parent]); //Swap需要自己实现
//继续向下调整
parent = child;
child = parent * 2 + 1;
}
//如果没有交换子节点和父节点,就说明这已经是一个小堆
else
break;
}
}
确保左右子树都是小堆
-
我们不可能保证,对于给定的任意一个数组,进行堆排序的向下调整算法时都能保证它的左右子树都是大堆或小堆
-
因此在进行向下调整算法前我们还要先对数组进行调整,使其左右子树满足使用条件。那么如何实现?
-
我们以数组
{3,5,2,7,8,6,1,9,4,0}为例: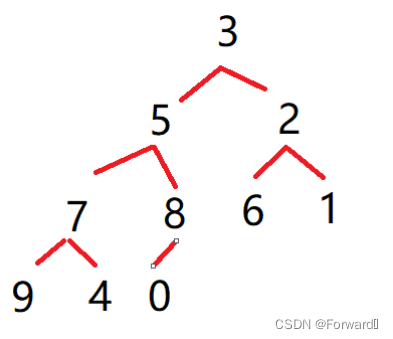
-
要满足每个父节点的左右子树都是小堆,那么我们就可以采用分治思想,从最小、最后的一棵子树开始看,不断进行向下调整算法,从而可以做到每棵子树是小堆,即自下而上建堆
- 有小伙伴可能会问怎么得到最后一棵子树的父节点呢?不知道小伙伴还是否记得左右孩子与父节点的关系式:
leftchild = parent * 2 + 1、rightchild = parent * 2 + 2,我们知道最后一个叶子节点的下标是numsSize-1,那么最后一棵子树的父节点下标就是(numsSize - 2) / 2
- 有小伙伴可能会问怎么得到最后一棵子树的父节点呢?不知道小伙伴还是否记得左右孩子与父节点的关系式:
建堆实现代码
- 注:此处建立的是小堆
void HeapBuild(int* nums, int numsSize)
{
for (int i = (numsSize - 2) / 2; i >= 0; i--)
AdjustDown(nums, numsSize, i);
}
实现排序
-
假设我们要实现对数组
{3,5,2,7,8,6,1,9,4,0}的升序排序,那么首先我们就要思考一个问题:是用大堆还是用小堆? -
假设我们使用的是小堆:那么建堆后的数组是这样的:
0 3 1 4 5 6 2 9 7 8,把它看成完全二叉树形式: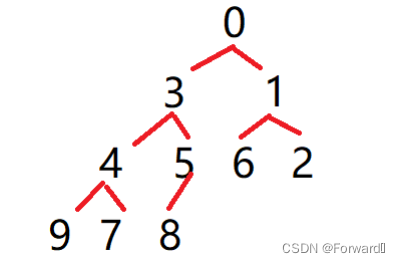
-
由于是要实现升序排序,且用的是小堆,因此堆顶元素就是最小值,在第二次建小堆得到次小值时就要将第一个数“0”忽略,即对数组
3 1 4 5 6 2 9 7 8建小堆,但是如果这样,数据之间的关系就会被打乱,在使用向下调整算法时就不能满足所有子树都是小堆的情况,如图: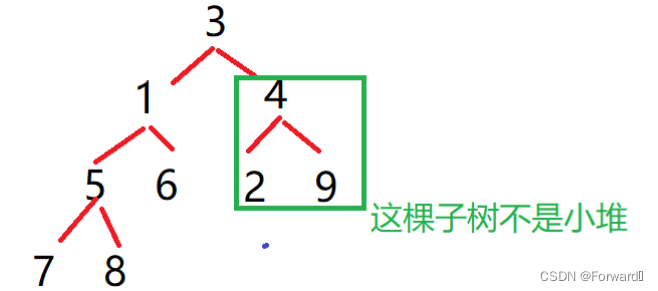
-
因此如果要用小堆来实现升序排序,就先要保证其左右子树都是小堆,效率不高
-
而如果用的是大堆来排序,那第一次建堆后是这样的:
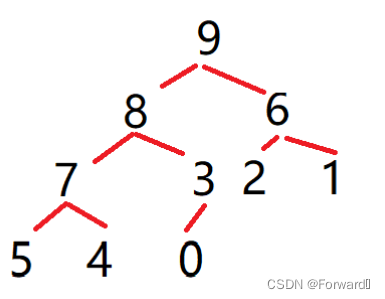
-
因为是要进行升序排序且用的是大堆,因此,堆顶元素就是最大值,我们可以将堆顶元素和最后一个元素交换位置,这样数组中最大的元素就到了数组最后的位置,之后也只需要对前
numsSize-1个数据处理即可,如图: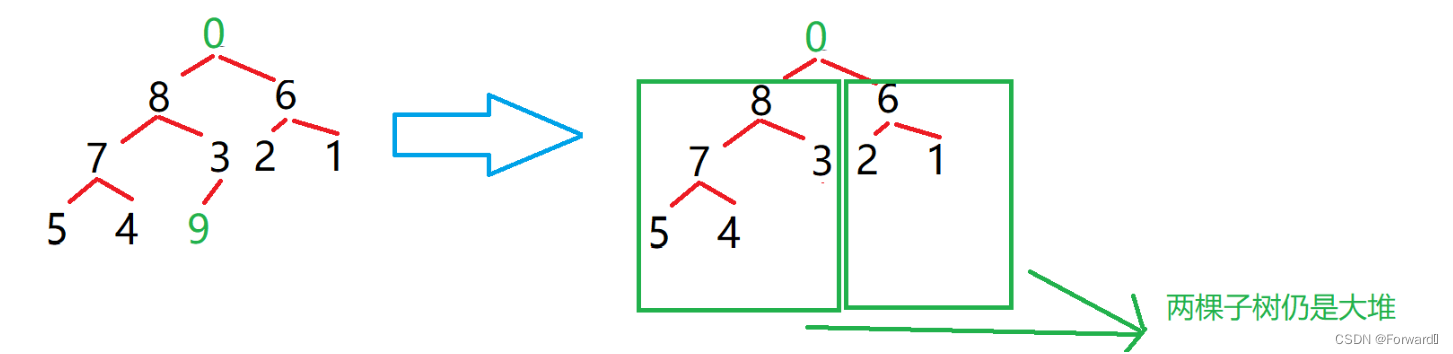
-
从上图中我们可以看到,根节点“0”的左右子树仍然为大堆,可见利用大堆来进行升序排序不会打乱数据之间的关系,这样就可以直接用向下调整算法来再建大堆,重复上述步骤,最终得到升序序列。
实现升序排序代码
//建大堆
void AdjustDown(int *nums, int numsSize, int root)
{
int parent = root;
int child = parent * 2 + 1; //首先默认左右孩子的较小值是左孩子,然后再在循环里判断取值
while ( child < numsSize)
{
//如果右孩子大于左孩子,那么child取值为右孩子的下标
if (child + 1 < numsSize &&nums[child] < nums[child + 1])
child += 1;
//如果字节点的值大于父节点,那么就交换这两个值
if (nums[child] > nums[parent])
{
Swap(&nums[child], &nums[parent]); //Swap需要自己实现
//继续向下调整
parent = child;
child = parent * 2 + 1;
}
//如果没有交换子节点和父节点,就说明这已经是一个小堆
else
break;
}
}
void HeapSort(int* nums, int numsSize)
{
//建堆
for (int i = (numsSize - 2) / 2; i >= 0; i--)
AdjustDown(nums, numsSize, i);
//排序
int end = numsSize - 1;
while (end > 0)
{
/*
不断交换堆顶和最后一个元素的值
交换完后忽略最后一个元素,重新建大堆
继续交换
直到只剩下一个元素
*/
Swap(&nums[end], &nums[0]);
AdjustDown(nums, end, 0);
end--;
}
}
- 同理,如果要实现降序排序,只需要将建大堆改为建小堆即可
堆排序时间复杂度
-
由于论证过程过于复杂,下面直接给出结论
-
向下调整算法
AdjustDown()的时间复杂度为O(log2N) -
自下而上建堆的时间复杂度为O(N)
-
建堆后排序的时间复杂度为O(Nlog2N)
-
因此整个堆排序的时间复杂度为O(Nlog2N)
回顾
-
我们再来看看为什么实现升序排序为什么要用大堆而不是用小堆:
-
我们前面提到,如果是小堆,那么将第一个数(小堆堆顶元素)排除在后,数据次序就会被打乱,要建小堆首先就需要保证其左右子树都是小堆,而这一过程的时间复杂度是O(N),由于要对N个元素排序,那么这一过程就要进行N次,因此整体的时间复杂度为O(N2)
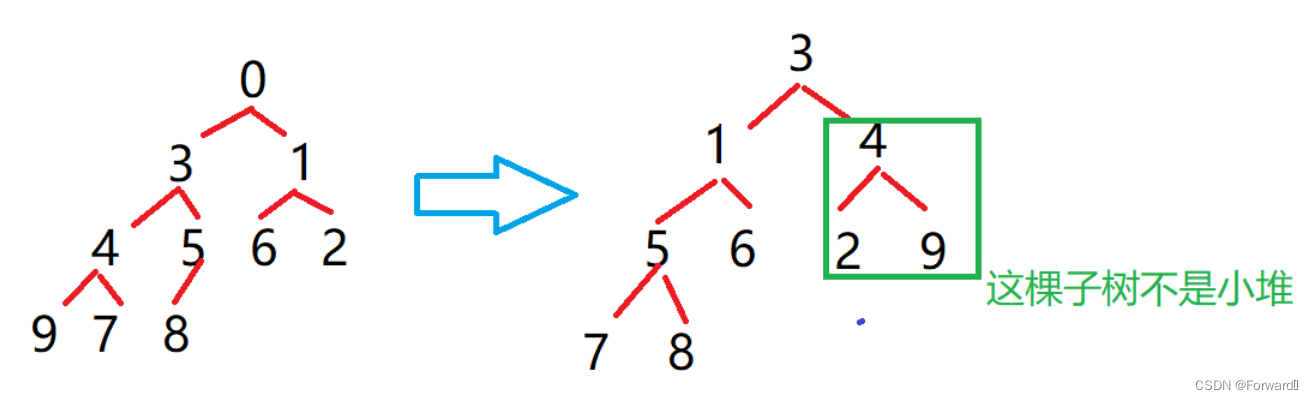
-
如果用的是大堆,那么将第一个数(大堆堆顶元素)和最后一个数交换后,将最后一个数排除在外,数据的次序不会被打乱,因此我们可以直接以第一个数为根,它的左右子树直接就是大堆,可以直接进行向下调整算法,时间复杂度为O(log2N),因为有N个数,因此整体的时间复杂度就是O(Nlog2N)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TrAcM5hB-1686977041763)(C:/Users/HUASHUO/AppData/Roaming/Typora/typora-user-images/image-20230617123547296.png)]](https://img-blog.csdnimg.cn/7929d668f50041029c44c8b5a649d35c.png)
















 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











