







文章目录
在当今数据驱动的世界中,Elasticsearch(简称ES)成为了一个强大而广泛应用的搜索和分析引擎。ES提供了快速、可扩展且高度可靠的数据存储和检索解决方案。然而,要真正掌握ES的各种功能和最佳实践,需要通过实践才能获得真正的知识。
一、索引创建
在Elasticsearch(ES)中,index操作和create操作是用于创建新文档的两种不同方式。下面是它们的区别:
-
Index操作:
- Index操作用于在指定的索引中创建新的文档。如果指定的索引不存在,Elasticsearch将自动创建该索引。
- 如果执行index操作时指定的文档ID已经存在,则会更新该文档。
- 如果没有指定文档ID,Elasticsearch会自动生成一个唯一的ID,并将其分配给新创建的文档。
- Index操作是幂等的,即多次执行相同的index操作不会创建重复的文档,而是更新现有的文档。
-
Create操作:
- Create操作也用于在指定的索引中创建新的文档。但是,与index操作不同,如果指定的文档ID已经存在,则会引发一个错误。
- 如果没有指定文档ID,Elasticsearch会自动生成一个唯一的ID,并将其分配给新创建的文档。
- Create操作是非幂等的,即多次执行相同的create操作会导致错误。
总结:
Index操作用于创建或更新文档,如果文档ID已存在,则更新该文档;而Create操作只能用于创建新文档,如果文档ID已存在,则会引发错误。
二、经验篇
使用动态模板(Dynamic Template)优化索引
在业务系统中,字符串类型的数据,一般被用作精确查询或模糊查询。
当Elasticsearch被用作大数据量存储中心时,尤其是从Mysql迁移数据进来的情况下,我们很多场景下其实无需对字符串分词,也就是说字符串存储不使用es中的text,我们可以设置属性的类型为keyword。
但是,如果数据结构中的字符串非常多,有没有一种方式,可以使字符串属性自动用keyword方式存储呢?这时候我们可以使用索引动态模板(Dynamic Template)来实现。
动态模板(Dynamic Template)
无需分词的情况下,可以在Elasticsearch动态模板中,设置所有字符串数据都用"type": "keyword"来存储。举个例子,我们可以创建一个适当的动态模板规则。
以下是一个示例:
{
"mappings": {
"dynamic_templates": [
{
"strings_as_keyword": {
"match_mapping_type": "string",
"mapping": {
"type": "keyword"
}
}
}
]
}
}
这个动态模板规则将会把所有字符串字段映射为keyword类型。
动态模板常见设置:https://blog.csdn.net/liuwenqiang1314/article/details/125861920
使用动态模板时,如何防止子属性溢出
使用动态模板时,class属性要i禁用Map结构。原因:es索引key数量默认不能超过1000。
es数据底层存储的时候是按照json结构的,Map结构的数据存储到es,key是不固定的,随着数据量的扩张,key的数量可能超过1000,此时es会抛出异常。
illegal_argument_exception, reason=Limit of total fields [1000] in index [fcs_biz_bill_body_dev] has been exceeded
这个错误是由于Elasticsearch索引中的字段数超过了默认限制(1000个字段)所导致的。当我们尝试在一个索引中创建太多字段时,Elasticsearch会抛出这个异常。
解决此问题有两种方法:
- 增加索引的
index.mapping.total_fields.limit设置值。我们可以通过更新索引设置来增加允许的最大字段数。例如,将其更改为2000:
PUT /fcs_biz_bill_body_dev/_settings
{
"index": {
"mapping": {
"total_fields": {
"limit": 2000
}
}
}
}
请注意,在生产环境中谨慎使用这种方法,因为大量字段可能会影响性能和资源利用率。
检查并优化数据模型:如果不需要那么多字段,请考虑重新设计或优化数据模型以减少不必要的字段。这可能包括删除未使用或重复的属性、合并相关属性等。
2. 对不需要索引的object属性禁用动态模板
在Elasticsearch中,动态模板可以用来控制新字段的映射。要实现遇到Map结构时不创建属性,你可以使用以下设置:
- 通过正则匹配相应的属性
- 设置
mapping.enabled: false
这是一个示例配置:
{
"mappings": {
"_doc": {
"dynamic_templates": [
{
"not_analyzed_map": {
"match_pattern": "regex",
"path_match": "^map_.*$",
"mapping": {
"enabled": false
}
}
}
]
}
}
}
批量处理器(Bulk Processor)不建议处理多个索引模板的请求
一个批量处理器(Bulk Processor)不建议处理多个索引模板的请求,尤其是当这些索引模板的分区规则不一致时,主要是因为以下原因:
-
分区规则不一致:不同的索引模板可能具有不同的分区规则,例如按时间分区、按地理位置分区等。当批量处理器处理多个索引模板的请求时,如果分区规则不一致,会导致数据在不同的分区之间不均匀分布,影响查询性能和数据的存储效率。
-
索引设置不同:每个索引模板可能具有不同的索引设置,如副本数量、刷新间隔、分片数量等。当批量处理器处理多个索引模板时,这些不同的设置可能会导致性能差异或资源的不均衡分配。
-
管理复杂性:处理多个索引模板的请求会增加管理的复杂性,包括索引模板的创建、更新和删除等操作。同时维护多个不同设置和规则的索引模板也会增加配置和维护的工作量。
为了确保良好的性能和简化管理,建议将具有相同分区规则和设置的索引请求分组处理。这样可以确保数据在相同的分区规则下均匀分布,并且能够更有效地管理索引的创建、更新和删除等操作。
三、性能调优
涉及性能的时候,批量的大小很关键。如果你的批量太大,它们会占用过多的内存。如果它们太小,网络开销又会很大。最佳的平衡点,取决于文档的大小——如果文档很大,每个批量中就少放几篇;如果文档很小,就多放几篇——以及集群的能力。
多条搜索(Multi Search)和多条获取(Multi Get)
多条搜索(Multi Search)和多条获取(Multi Get)是两种在Elasticsearch中进行批量操作的功能,但它们的用途和操作对象存在一些区别:
-
多条搜索(Multi Search):
- 多条搜索是同时执行多个搜索请求的功能。可以在单个请求中发送多个搜索请求,并一次性获取它们的结果。
- 多条搜索适用于在不同的索引、类型或查询条件上执行多个搜索操作。
- 多条搜索请求的结果将按照请求的顺序返回,每个搜索请求的结果都是独立的。
-
多条获取(Multi Get):
- 多条获取是同时从多个索引中获取多个文档的功能。它允许在单个请求中指定多个文档的ID,并一次性获取它们的内容。
- 多条获取适用于根据文档的ID获取多个文档的情况,可以跨越不同的索引和类型。
- 多条获取请求的结果将按照请求的顺序返回,每个获取请求的结果都是对应的文档内容。
总结:
多条搜索适用于执行多个搜索请求,获取符合条件的文档结果;而多条获取适用于根据文档的ID获取多个文档的内容。
刷新(Refresh)和冲刷(Flush)
在Elasticsearch中,刷新(Refresh)和冲刷(Flush)是两个不同的操作,它们具有以下区别:
-
刷新(Refresh):
- 刷新是指将索引中的最新更改从内存刷新到磁盘的持久化存储结构(translog)中,以使这些更改对搜索可见,并不会直接刷新到磁盘。
- 当进行索引操作(如文档的创建、更新、删除)时,数据会首先写入内存中的事务日志(translog),而不是直接写入磁盘。刷新操作将事务日志中的数据写入磁盘,以确保最新的更改对搜索可见。
- 刷新操作通常由Elasticsearch自动触发,但也可以通过执行手动刷新操作来强制将最新更改刷新到磁盘。
- 刷新操作会导致短暂的性能开销,因为它需要将数据从内存写入磁盘。但它确保了数据的持久性和一致性。
-
冲刷(Flush):
- 冲刷是指将索引的所有未决更改写入磁盘,以确保数据的持久性。
- 当进行索引操作时,数据首先写入内存中的事务日志和缓冲区。但它们不会立即写入磁盘,而是留存在内存中,直到触发冲刷操作。
- 冲刷操作将内存中的事务日志和缓冲区的数据写入磁盘,确保了数据的持久性和一致性。
- 冲刷操作通常由Elasticsearch自动触发,但也可以通过执行手动冲刷操作来强制将未决更改写入磁盘。
- 冲刷操作可能会导致短暂的性能开销,因为它需要将数据从内存写入磁盘。
总结:
刷新操作将最新的更改从内存刷新到磁盘的持久化存储结构(translog)中,以使其对搜索可见;而冲刷操作将所有未决更改从内存写入磁盘,确保数据的持久性。刷新操作通常是自动触发的,而冲刷操作可以手动触发。
冲刷流程如下图:
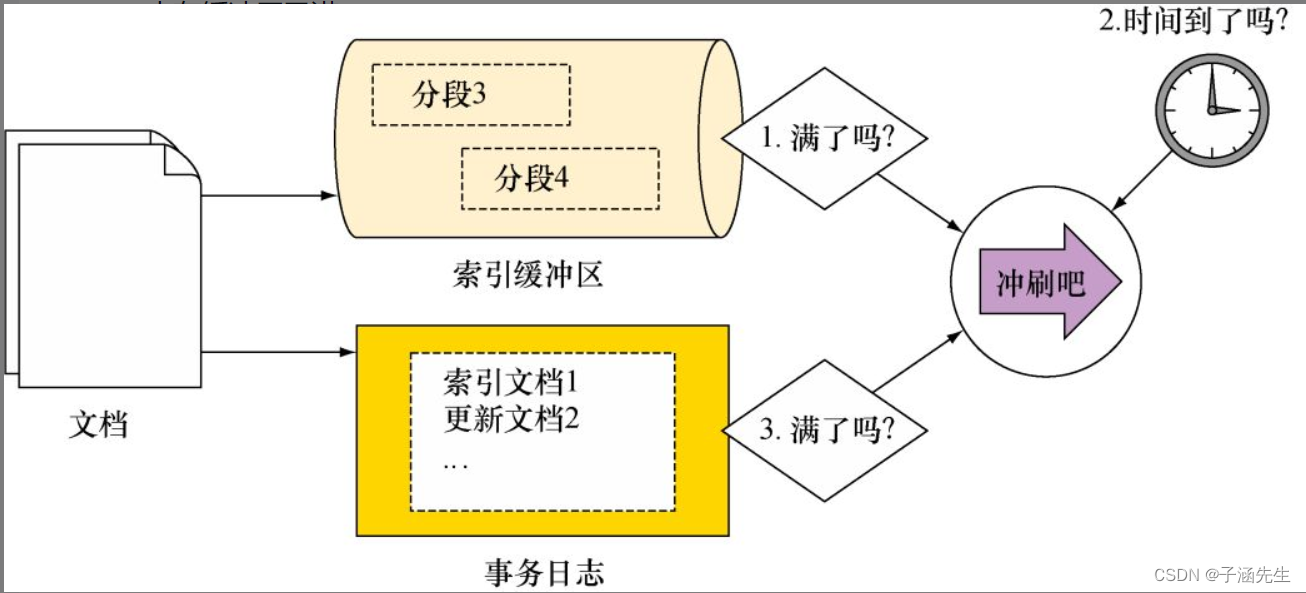
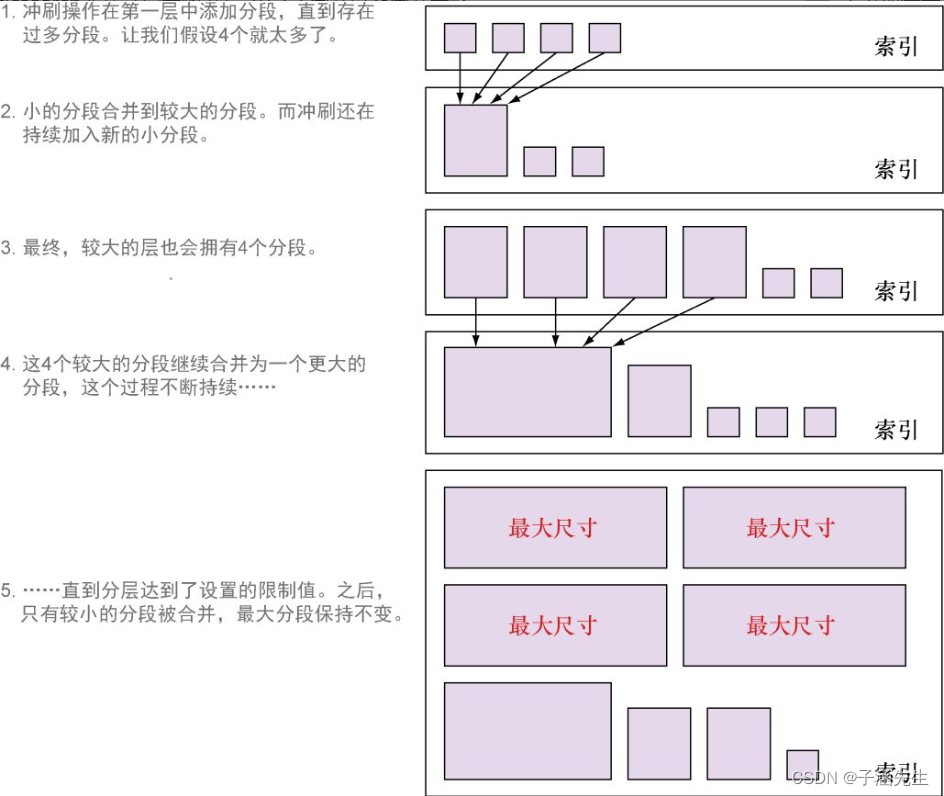
合并分段
- 更新文档不能修改实际的文档,只是索引一篇新的文档。
- 删除也不能从分段中移除文档(这需要重建倒排索引),只是在单独的.del文件中将其标记为“已被删除”。文档只会在分段合并的时候真正地被移除。
那么合并分段的两个目的:
- 第一个是将分段的总数量保持在受控的范围内(这用来保障查询的性能)。
- 第二个是真正地删除文档。
合并分段策略:默认为分层合并策略。
以上就是我对es使用的一些经验总结,以后也会继续补充和完善。
















 2981
2981











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











