







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
官方网址:http://spark.apache.org/、https://databricks.com/spark/about

目录
介绍
实际开发Spark 应用程序使用IDEA集成开发环境,Spark所有代码均使用Scala语言开发,利用函数式编程分析处理数据,更加清晰简洁。企业中也使用Java语言开发Spark 程序, 目前基本上都是使用Java8中Lambda表达式和Stream编程实现。
构 建 Maven Project
创建Maven Project工程【bigdata-spark_2.11】,设置GAV三要素的值如下:

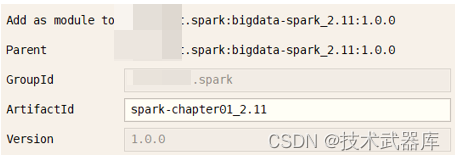
创建Maven Module模块【spark-chapter01_2.11】,对应的GAV三要素值如下:
添加依赖至POM文件中,内容如下:
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.12.10</scala.version>
<scala.binary.version>2.12</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
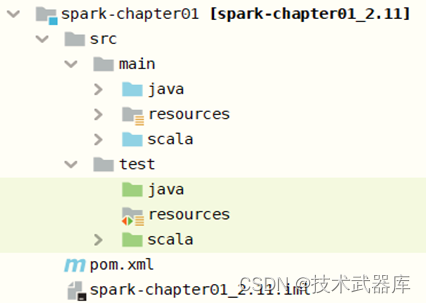
在Maven Module中创建对应文件夹,截图如下所示:
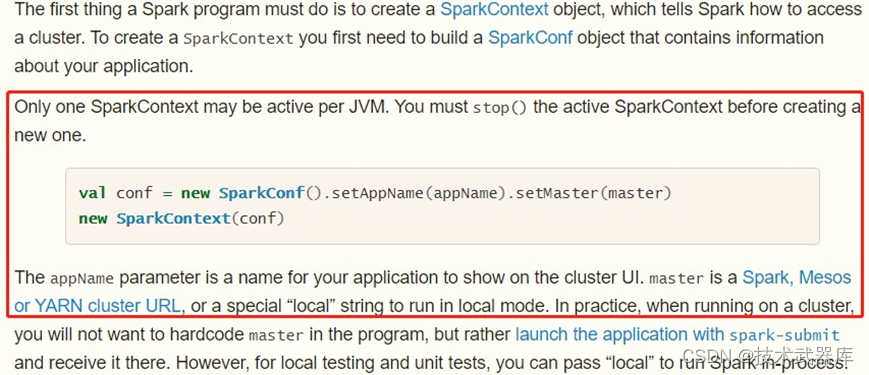
应用入口:SparkContext
Spark Application程序入口为:SparkContext,任何一个应用首先需要构建SparkContext对象, 如下两步构建:
- 第一步、创建SparkConf对象
设置Spark Application基本信息,比如应用的名称AppName和应用运行Master
- 第二步、传递SparkConf对象,创建SparkContext对象
文档:http://spark.apache.org/docs/2.4.5/rdd-programming-guide.html
编程实现
从HDFS上读取数据,所以需要将HDFS Client配置文件放入到Maven Module资源目录下,同时设置应用运行时日志信息。
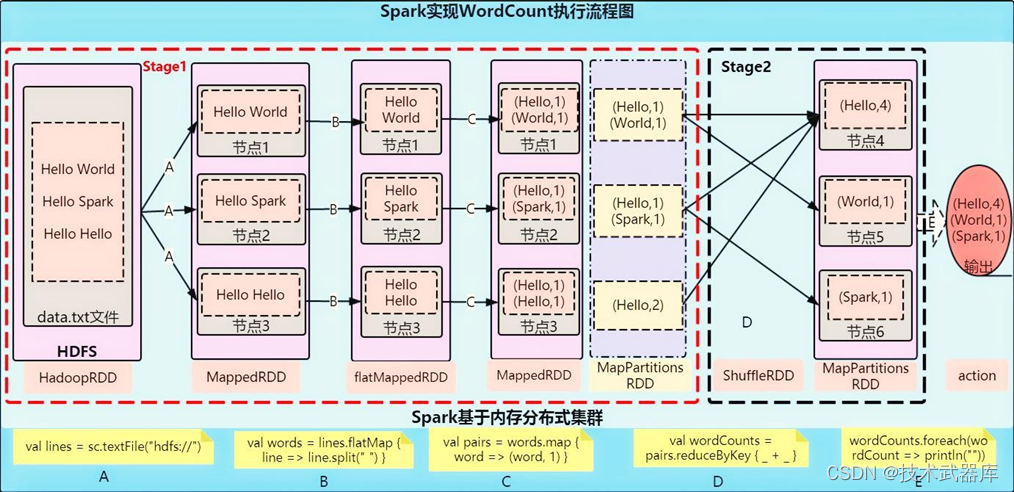
前面已经在spark-shell中编码实现词频统计WordCount,主要流程如下图所示:
创建SparkWordCount.scala文件,代码如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Scala语言使用SparkCore编程实现词频统计:WordCount
* 从HDFS上读取数据,统计WordCount,将结果保存到HDFS上
*/
object SparkWordCount {
// TODO: 当应用运行在集群上的时候,MAIN函数就是Driver Program,必须创建SparkContext对象def main(args: Array[String]): Unit = {
// 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用运行模式
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkWordCount")
// TODO: 构建SparkContext上下文实例对象,读取数据和调度Job执行
val sc: SparkContext = new SparkContext(sparkConf)
// 第一步、读取数据,封装到RDD集合,认为列表List
val inputRDD: RDD[String] = sc.textFile("/datas/wordcount.data")
// 第二步、处理数据,调用RDD中函数,认为调用列表中的函数
// a. 每行数据分割为单词
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
// b. 转换为二元组,表示每个单词出现一次
val tuplesRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
// c. 按照Key分组聚合
val wordCountsRDD: RDD[(String, Int)] = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
// 第三步、输出数据
wordCountsRDD.foreach(println)
// 保存到为存储系统,比如HDFS
wordCountsRDD.saveAsTextFile(s"/datas/swc-output-${System.currentTimeMillis()}")
// 为了测试,线程休眠,查看WEB UI界面Thread.sleep(10000000)
// TODO:应用程序运行接收,关闭资源
sc.stop()
}
}
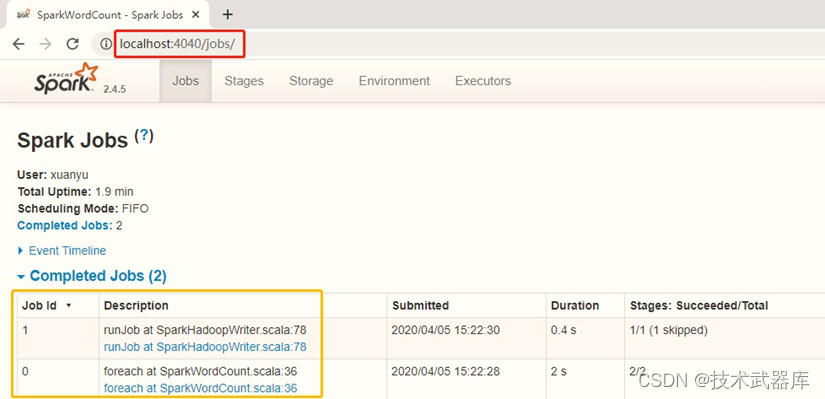
本地模式LocalMode运行应用程序,结果截图如下:
编程实现:TopKey
在上述词频统计WordCount代码基础上,对统计出的每个单词的词频Count,按照降序排序, 获取词频次数最多Top3单词。数据结构RDD中关于排序函数有如下三个:
- sortByKey:针对RDD中数据类型key/value对时, 按照Key进行排序

- sortBy:针对RDD中数据指定排序规则

- top:按照RDD中数据采用降序方式排序,如果是Key/Value对,按照Key降序排序

具体演示代码如下,建议使用sortByKey函数进行数据排序操作,慎用top函数。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Scala语言使用SparkCore编程实现词频统计:WordCount
* 从HDFS上读取数据,统计WordCount,将结果保存到HDFS上, 获取词频最高三个单词
*/
object SparkTopKey {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用运行模式
val sparkConf: SparkConf = new SparkConf()
.setMaster("local[2]")
.setAppName("SparkWordCount")
// TODO: 构建SparkContext上下文实例对象,读取数据和调度Job执行
val sc: SparkContext = new SparkContext(sparkConf)
// 第一步、读取数据
// 封装到RDD集合,认为列表List
val inputRDD: RDD[String] = sc.textFile("/datas/wordcount.data")
// 第二步、处理数据
// 调用RDD中函数,认为调用列表中的函数
// a. 每行数据分割为单词
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
// b. 转换为二元组,表示每个单词出现一次
val tuplesRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
// c. 按照Key分组聚合
val wordCountsRDD: RDD[(String, Int)] = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
// 第三步、输出数据
wordCountsRDD.foreach(println)
/*
(spark,7) (hadoop,5) (hbase,1)
(hive,3) (mapreduce,1)
*/
// TODO: 按照词频count降序排序获取前3个单词, 有三种方式
println("======================== sortByKey =========================")
// 方式一:按照Key排序sortByKey函数, TODO: 建议使用sortByKey函数
/*
def sortByKey(
ascending: Boolean = true,
numPartitions: Int = self.partitions.length
): RDD[(K, V)]
*/
wordCountsRDD
.map(tuple => tuple.swap)
//.map(tuple => (tuple._2, tuple._1))
.sortByKey(ascending = false)
.take(3)
.foreach(println)
println("======================== sortBy =========================")
// 方式二:sortBy函数, 底层调用sortByKey函数
/*
def sortBy[K](
f: (T) => K, // T 表示RDD集合中数据类型,此处为二元组
ascending: Boolean = true,
numPartitions: Int = this.partitions.length
)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
*/
wordCountsRDD
.sortBy(tuple => tuple._2, ascending = false)
.take(3)
.foreach(println)
println("======================== top =========================")
// 方式三:top函数,含义获取最大值,传递排序规则, TODO:慎用
/*
def top(num: Int)(implicit ord: Ordering[T]): Array[T]
*/ wordCountsRDD
.top(3)(Ordering.by(tuple => tuple._2))
.foreach(println)
// 为了测试,线程休眠,查看WEB UI界面Thread.sleep(10000000)
// TODO:应用程序运行接收,关闭资源sc.stop()
}
}
本地模式运行测试,结果截图如下:

Spark 应用提交
使用IDEA集成开发工具开发测试Spark Application程序以后,类似MapReduce程序一样,打成jar包,使用命令【spark-submit】提交应用的执行,提交命令帮助文档:



应用提交语法
使用【spark-submit】提交应用语法如下:
Usage: spark-submit [options] <app jar | python file> [app arguments]
如果使用Java或Scala语言编程程序,需要将应用编译后达成Jar包形式,提交运行。

基本参数配置
提交运行Spark Application时,有些基本参数需要传递值,如下所示:

动态加载Spark Applicaiton运行时的参数,通过–conf进行指定,如下使用方式:

Driver Program 参数配置
每个Spark Application运行时都有一个Driver Program,属于一个JVM Process进程,可以设置内存Memory和CPU Core核数。

Executor 参数配置
每个Spark Application运行时,需要启动Executor运行任务Task,需要指定Executor个数及每个Executor资源信息(内存Memory和CPU Core核数)。

官方案例
Spark 官方提供一些针对不同模式运行Spark Application如何设置参数提供案例,具体如下:
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \ 100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \ 1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \ 1000
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \ 1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \ examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \ http://path/to/examples.jar \ 1000
# Run on a Kubernetes cluster in cluster deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master k8s://xx.yy.zz.ww:443 \
--deploy-mode cluster \
--executor-memory 20G \
--num-executors 50 \ http://path/to/examples.jar \ 1000
应用打包运行
将开发测试完成的WordCount程序打成jar保存,使用【spark-submit】分别提交运行在本地模式LocalMode和集群模式Standalone集群。先修改代码,通过master设置运行模式及传递处理数据路径,代码【SparkSubmit.scala】如下:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Scala语言使用SparkCore编程实现词频统计:WordCount
* 从HDFS上读取数据,统计WordCount,将结果保存到HDFS上
*/
object SparkSubmit {
def main(args: Array[String]): Unit = {
// TODO: 为了程序健壮性,判断是否传递参数
if(args.length != 2){
println("Usage: SparkSubmit <input> <output> ")
System.exit(1)
}
// 创建SparkConf对象,设置应用的配置信息,比如应用名称和应用运行模式
val sparkConf: SparkConf = new SparkConf()
//.setMaster("local[2]")
.setAppName("SparkWordCount")
// TODO: 构建SparkContext上下文实例对象,读取数据和调度Job执行
val sc: SparkContext = new SparkContext(sparkConf)
// 第一步、读取数据,封装到RDD集合,认为列表List val inputRDD: RDD[String] = sc.textFile(args(0))
// 第二步、处理数据
// 调用RDD中函数,认为调用列表中的函数
// a. 每行数据分割为单词
val wordsRDD = inputRDD.flatMap(line => line.split("\\s+"))
// b. 转换为二元组,表示每个单词出现一次
val tuplesRDD: RDD[(String, Int)] = wordsRDD.map(word => (word, 1))
// c. 按照Key分组聚合
val wordCountsRDD: RDD[(String, Int)] = tuplesRDD.reduceByKey((tmp, item) => tmp + item)
// 第三步、输出数据
// 保 存 到 为 存 储 系 统 , 比 如 HDFS wordCountsRDD.saveAsTextFile(s"${args(1)}-${System.nanoTime()}")
// TODO:应用程序运行接收,关闭资源sc.stop()
}
}
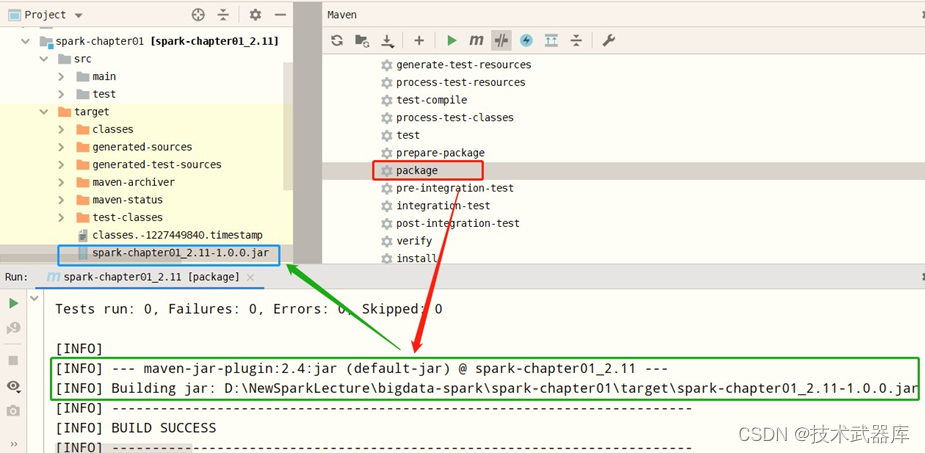
打成jar包【spark-chapter01_2.11-1.0.0.jar】,如下图所示:
上传jar包至HDFS文件系统目录【/spark/apps/】下,方便提交运行时任何地方都可读取jar包。
## 创建HDFS目录
hdfs dfs -mkdir -p /spark/apps/
## 上传jar包
hdfs dfs -put /export/server/spark/spark-chapter01_2.11-1.0.0.jar /spark/apps/
- 本地模式LocalMode提交运行
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master local[2] \
--class cn.lwh.spark.submit.SparkSubmit \ hdfs://node1.cn:8020/spark/apps/spark-chapter01_2.11-1.0.0.jar \
/datas/wordcount.data /datas/swc-output
- Standalone集群提交运行
SPARK_HOME=/export/server/spark
${SPARK_HOME}/bin/spark-submit \
--master spark://node1.cn:7077,node2.cn:7077 \
--class cn.lwh.spark.submit.SparkSubmit \
--driver-memory 512m \
--executor-memory 512m \
--num-executors 1 \
--total-executor-cores 2 \
hdfs://node1.cn:8020/spark/apps/spark-chapter01_2.11-1.0.0.jar \
/datas/wordcount.data /datas/swc-output
运行完成以后,从历史服务器HistoryServer中查看应用,切换到【Executors】Tab页面: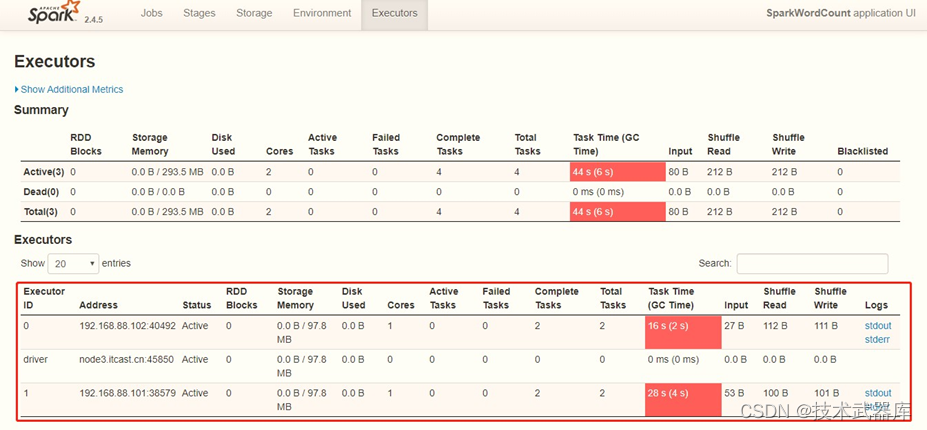
结束
本篇介绍如何使用IDEA开发Spark应用程序就这么多,下篇介绍运行模式Spark on YARN

















 2218
2218











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











