







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/
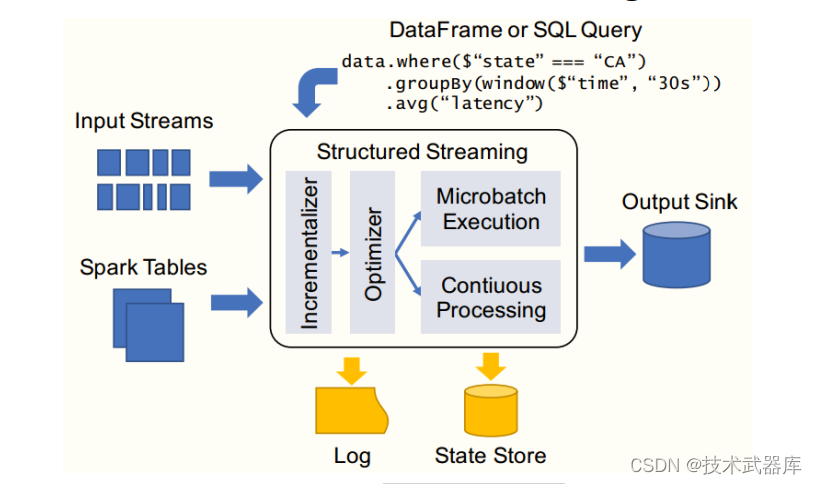
在物联网时代,大量的感知器每天都在收集并产生着涉及各个领域的数据。物联网提供源源不断的数据流,使实时数据分析成为分析数据的理想工具。

模拟一个智能物联网系统的数据统计分析,产生设备数据发送到Kafka,结构化流Structured
Streaming实时消费统计。 对物联网设备状态信号数据,实时统计分析:
- 1)、信号强度大于30的设备
- 2)、各种设备类型的数量
- 3)、各种设备类型的平均信号强度
设备监控数据
编写程序模拟生成物联网设备监控数据,发送到Kafka Topic中,此处为了演示字段较少,实际生产项目中字段很多。
创建 Topic
启动Kafka Broker服务,创建Topic【search-log-topic】,命令如下所示:
# 启动Zookeeper
/export/server/zookeeper/bin/zkServer.sh start
# 启动Kafka Broker
/export/server/kafka/bin/kafka-server-start.sh -daemon /export/server/kafka/config/server.properties
rm -rf /export/server/kafka/logs/*
# 创建topic
bin/kafka-topics.sh --create --topic iotTopic --replication-factor 1 --partitions 3 --zookeeper node01:2181
# 模拟生产者
/export/server/kafka/bin/kafka-console-producer.sh --broker-list 192.168.10.10:9092 --topic iotTopic
# 模拟消费者
/export/server/kafka/bin/kafka-console-consumer.sh --bootstrap-server 192.168.10.10:9092 --topic iotTopic
--from-beginning
# 删除topic
/export/server/kafka/bin/kafka-topics.sh --delete --zookeeper 192.168.10.10:2181/kafka200 --topic iotTopic
模拟数据
模拟设备监控日志数据,字段信息封装到CaseClass样例类【DeviceData】类,代码如下:
package iot
/**
* 物联网设备发送状态数据
* @param device 设备标识符ID
* @param deviceType 设备类型,如服务器mysql, redis, kafka或路由器route
* @param signal 设备信号
* @param time 发送数据时间
*/
case class DeviceData(
device: String, //
deviceType: String, //
signal: Double, //
time: Long //
)
模拟产生日志数据类【MockIotDatas】具体代码如下:
package iot
import java.util.Properties
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import org.json4s.jackson.Json
import scala.util.Random
object MockIotDatas {
def main(args: Array[String]): Unit = {
// 发送Kafka Topic
val props = new Properties()
props.put("bootstrap.servers", "192.168.10.10:9092")
props.put("acks", "1")
props.put("retries", "3")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
val producer = new KafkaProducer[String, String](props)
val deviceTypes = Array(
"db", "bigdata", "kafka", "route", "bigdata", "db", "bigdata", "bigdata", "bigdata"
)
val random: Random = new Random()
while (true){
val index: Int = random.nextInt(deviceTypes.length)
val deviceId: String = s"device_${(index +1) * 10 + random.nextInt(index + 1)}"
val deviceType: String = deviceTypes(index)
val deviceSignal: Int = 10 + random.nextInt(90)
// 模拟构造设备数据
val deviceData = DeviceData(deviceId, deviceType, deviceSignal, System.currentTimeMillis())
// 转换为JSON字符串
val deviceJson: String = new Json(org.json4s.DefaultFormats).write(deviceData)
//打印测试
println(deviceJson)
Thread.sleep(100 + random.nextInt(500))
//生产到Kafka
val record = new ProducerRecord[String, String]("iotTopic", deviceJson)
producer.send(record)
}
// 关闭连接
producer.close()
}
}
相当于大机房中各个服务器定时发送相关监控数据至Kafka中,服务器部署服务有数据库db、大数据集群bigdata、消息队列kafka及路由器route等等,数据样本:
{"device":"device_50","deviceType":"bigdata","signal":91.0,"time":1590660338429}
{"device":"device_20","deviceType":"bigdata","signal":17.0,"time":1590660338790}
{"device":"device_32","deviceType":"kafka","signal":93.0,"time":1590660338908}
{"device":"device_82","deviceType":"bigdata","signal":72.0,"time":1590660339380}
{"device":"device_32","deviceType":"kafka","signal":10.0,"time":1590660339972}
基于DataFrame分析
按照业务需求,从Kafka消费日志数据,基于DataFrame数据结构调用函数分析,代码如下:
package iot
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.types.{DoubleType, LongType}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 对物联网设备状态信号数据,实时统计分析:
* 1)、信号强度大于30的设备
* 2)、各种设备类型的数量
* 3)、各种设备类型的平均信号强度
*/
object IotStreamingOnline {
def main(args: Array[String]): Unit = {
// 1. 构建SparkSession会话实例对象,设置属性信息
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
// 导入隐式转换和函数库
import org.apache.spark.sql.functions._
import spark.implicits._
// 2. 从Kafka读取数据,底层采用New Consumer API
val iotStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.10.10:9092").option("subscribe", "iotTopic")
// 设置每批次消费数据最大值
.option("maxOffsetsPerTrigger", "100000")
.load()
// 3. 对获取数据进行解析,封装到DeviceData中
val etlStreamDF: DataFrame = iotStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
// 将数据转换Dataset
.as[String] // 内部字段名为value
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 解析JSON数据: {"device":"device_65","deviceType":"db","signal":12.0,"time":1589718910796}
.select(
get_json_object($"value", "$.device").as("device_id"),
get_json_object($"value", "$.deviceType").as("device_type"),
get_json_object($"value", "$.signal").cast(DoubleType).as("signal"),
get_json_object($"value", "$.time").cast(LongType).as("time")
)
// 4. 依据业务,分析处理
// TODO: signal > 30 所有数据,按照设备类型 分组,统计数量、平均信号强度
val resultStreamDF: DataFrame = etlStreamDF
// 信号强度大于10
.filter($"signal" > 30)
// 按照设备类型 分组
.groupBy($"device_type")
// 统计数量、评价信号强度
.agg(
count($"device_type").as("count_device"),
round(avg($"signal"), 2).as("avg_signal")
)
// 5. 启动流式应用,结果输出控制台
val query: StreamingQuery = resultStreamDF.writeStream
.outputMode(OutputMode.Complete())
.format("console")
.option("numRows", "10").option("truncate", "false")
.start()
query.awaitTermination()
query.stop()
}
}
其中使用函数get_json_object提取JSON字符串中字段值,将最终结果打印控制台。
基于SQL分析
按照业务需求,从Kafka消费日志数据, 提取字段信息,将DataFrame注册为临时视图,编写SQL执行分析,代码如下:
package iot
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.types.{DoubleType, LongType}
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 对物联网设备状态信号数据,实时统计分析,基于SQL编程
* 1)、信号强度大于30的设备
* 2)、各种设备类型的数量
* 3)、各种设备类型的平均信号强度
*/
object IotStreamingOnlineSQL {
def main(args: Array[String]): Unit = {
// 1. 构建SparkSession会话实例对象,设置属性信息
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.config("spark.sql.shuffle.partitions", "3")
.getOrCreate()
import org.apache.spark.sql.functions._
import spark.implicits._
// 2. 从Kafka读取数据,底层采用New Consumer API
val iotStreamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "192.168.10.10:9092")
.option("subscribe", "iotTopic")
// 设置每批次消费数据最大值
.option("maxOffsetsPerTrigger", "100000")
.load()
// 3. 对获取数据进行解析,封装到DeviceData中
val etlStreamDF: DataFrame = iotStreamDF
// 获取value字段的值,转换为String类型
.selectExpr("CAST(value AS STRING)")
.as[String] // 将数据转换Dataset, 内部字段名为value
// 过滤数据
.filter(line => null != line && line.trim.length > 0)
// 解析JSON数据: {"device":"device_65","deviceType":"db","signal":12.0,"time":1589718910796}
.select(
get_json_object($"value", "$.device").as("device_id"),
get_json_object($"value", "$.deviceType").as("device_type"),
get_json_object($"value", "$.signal").cast(DoubleType).as("signal"),
get_json_object($"value", "$.time").cast(LongType).as("time")
)
// 4. 依据业务,分析处理
// TODO: signal > 30 所有数据,按照设备类型 分组,统计数量、平均信号强度
// 4.1 注册DataFrame为临时视图
etlStreamDF.createOrReplaceTempView("view_tmp_stream_iots")
// 4.2 编写SQL执行查询
val resultStreamDF: DataFrame = spark.sql(
"""
|SELECT
| device_type, COUNT(device_type) AS count_device, ROUND(AVG(signal), 2) AS avg_signal
|FROM view_tmp_stream_iots
|WHERE signal > 30 GROUP BY device_type
|""".stripMargin)
// 5. 启动流式应用,结果输出控制台
val query: StreamingQuery = resultStreamDF.writeStream
.outputMode(OutputMode.Complete())
.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
println("===========================================")
println(s"BatchId = ${batchId}")
println("===========================================")
if (!batchDF.isEmpty) batchDF.coalesce(1).show(20, truncate = false)
}
.start()
query.awaitTermination()
query.stop()
}
}
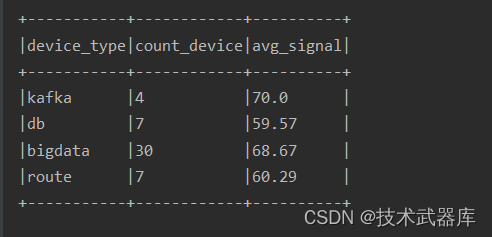
运行流式应用,结果如下图所示:

















 2633
2633











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











