







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
官方网址:http://spark.apache.org/、https://databricks.com/spark/about

前言
之前我介绍了Spark基础相关的文章共6篇文章,从这个文章开始,我就要开始介绍SparkCore系列的东西了,大家有想看之前Spark基础的,可以通过上面的[大数据系列文章目录]传送门过去看。
RDD的介绍
对于大量的数据,Spark 在内部保存计算的时候,都是用一种叫做弹性分布式数据集(Resilient Distributed Datasets,RDD)的数据结构来保存的,所有的运算以及操作都建立在 RDD 数据结构的基础之上。
在Spark开山之作Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing这篇paper中(以下简称 RDD Paper),Matei等人提出了RDD这种数据结构, 文中开头对RDD的定义是:

也就是说RDD设计的核心点为:
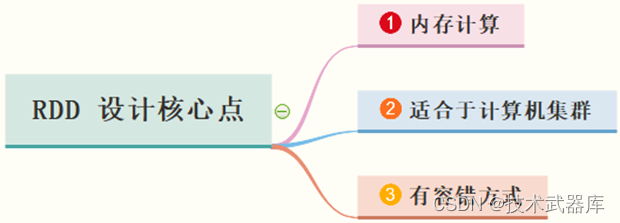
RDD提供了一个抽象的数据模型,不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy等等)。
RDD 定 义
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象, 代表一个 不可变、可分区、里面的元素可并行计算的集合。拆分核心要点三个方面:

可以认为RDD是分布式的列表List或数组Array,抽象的数据结构,RDD是一个抽象类Abstract Class和泛型Generic Type:

RDD弹性分布式数据集核心点示意图如下:
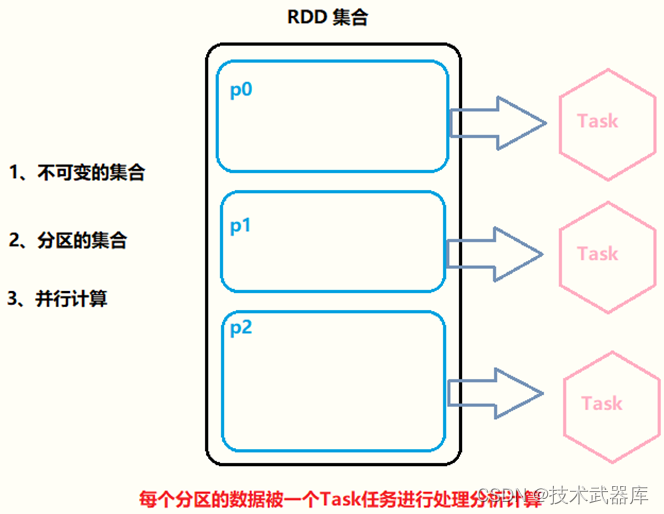
RDD将Spark的底层的细节都隐藏起来(自动容错、位置感知、任务调度执行,失败重试等), 让开发者可以像操作本地集合一样以函数式编程的方式操作RDD这个分布式数据集,进行各种并行计算,RDD中很多处理数据函数与列表List中相同与类似。
RDD 特 性
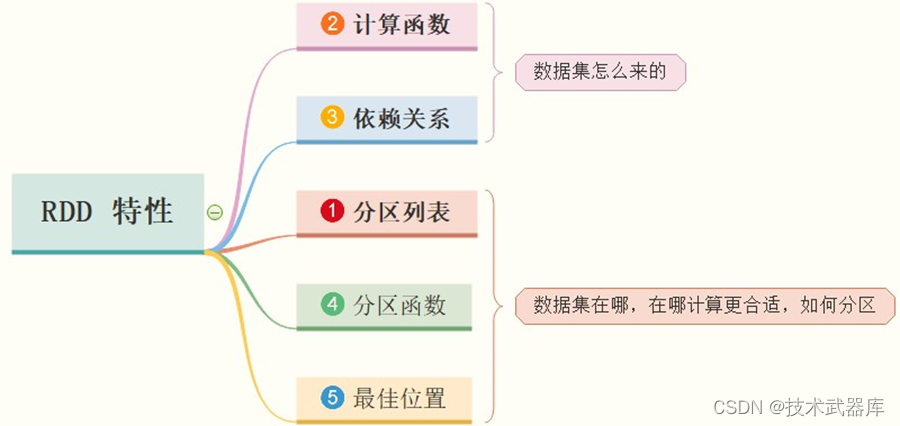
RDD 数据结构内部有五个特性(摘录RDD 源码):

前三个特征每个RDD都具备的,后两个特征可选的。
第一个:A list of partitions
- 一组分片(Partition)/一个分区(Partition)列表,即数据集的基本组成单位;
- 对于RDD来说,每个分片都会被一个计算任务处理,分片数决定并行度;
- 用户可以在创建RDD时指定RDD的分片个数,如果没有指定,那么就会采用默认值;

第二个:A function for computing each split
- 一个函数会被作用在每一个分区;
- Spark中RDD的计算是以分片为单位的,compute函数会被作用到每个分区上;
第三个:A list of dependencies on other RDDs
-
一个RDD会依赖于其他多个RDD;
-
RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算(Spark的容错机制);

第四个:Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) -
可选项,对于KeyValue类型的RDD会有一个Partitioner,即RDD的分区函数;
-
当前Spark中实现了两种类型的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
-
只有对于key-value的RDD,才有Partitioner,非key-value的RDD,Parititioner值是None。
-
Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。

第五个:Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file) -
可选项,一个列表,存储存取每个Partition的优先位置(preferred location);
-
对于一个HDFS文件来说,这个列表保存的就是每个Partition所在的块的位置。
-
按照"移动数据不如移动计算"的理念,Spark在进行任务调度的时候,会尽可能选择那些存有数据的worker节点来进行任务计算。(数据本地性)

RDD 是一个数据集的表示,不仅表示了数据集,还表示了这个数据集从哪来、如何计算,主要属性包括五个方面(必须牢记,通过编码加深理解,面试常问):
RDD 设计的一个重要优势是能够记录 RDD 间的依赖关系,即所谓血统(lineage)。通过丰富的转移操作(Transformation),可以构建一个复杂的有向无环图,并通过这
个图来一步步进行计算。
WordCount中RDD
以词频统计WordCount程序为例,查看整个Job中各个RDD类型及依赖关系,WordCount程序代码如下:

运行程序结束后,查看WEB UI监控页面,此Job(RDD调用foreach触发)执行DAG图:

上图中相关说明如下:
第一点、黑色圆圈表示一个RDD
- 上图中有5个黑色圆圈,说明整个Job中有个5个RDD
- 【1号】RDD类型:HadoopRDD,从HDFS或LocalFS读取文件数据;
- 【2号、3号和4号】RDD类型:MapPartitionsRDD,从一个RDD转换而来,没有经过shuffle 操作;
- 【5号】RDD类型:ShuffledRDD,从一个RDD转换而来,经过Shuffle重分区操作,Spark Shuffle类似MapReduce流程中Map Phase和Reduce Phase中的Shuffle;
第二点、浅蓝色矩形框表示调用RDD函数
- 上图中【5号】RDD所在在蓝色矩形框上的函数【reduceByKey】,表明【5号】RDD是【4 号】RDD调用reduceByKey函数得到;
第三点、查看ShuffleRDD源码,实现RDD的5个特性

RDD 设计的一个重要优势是能够记录 RDD 间的依赖关系,即所谓血统(lineage)。通过丰富的转移操作(Transformation),可以构建一个复杂的有向无环图,并通过这
个图来一步步进行计算。
下回分解
下篇文章将带大家如何通过代码的方式去实现一个小案例,去使用SparkRDD,亲身感受一下RDD的魅力所在,同时给大家说下,后续Spark的代码都是通过Scala的方式,因为Spark底层也是Scala编写的,所以没有了解Scala的同学,可以先学习下和Java差不多,是基于Java的封装,运行也要依赖于JVM。

















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











