







版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
传送门:大数据系列文章目录
官方网址:http://spark.apache.org/、 http://spark.apache.org/sql/
目录
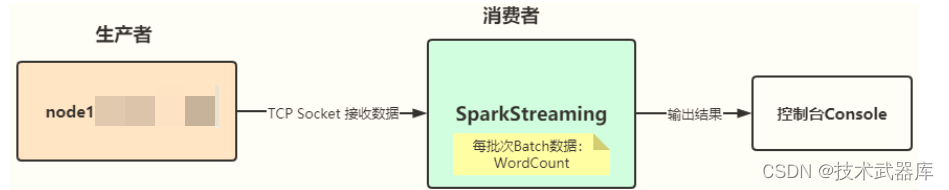
SparkStreaming官方提供Example案例,功能描述: 从TCP Socket数据源实时消费数据,对每
批次Batch数据进行词频统计WordCount, 流程图如下:

文档: http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#a-quick-example
官方案例运行
运行官方提供案例,使用【 $SPARK_HOME/bin/run-example】 命令运行,效果如下:
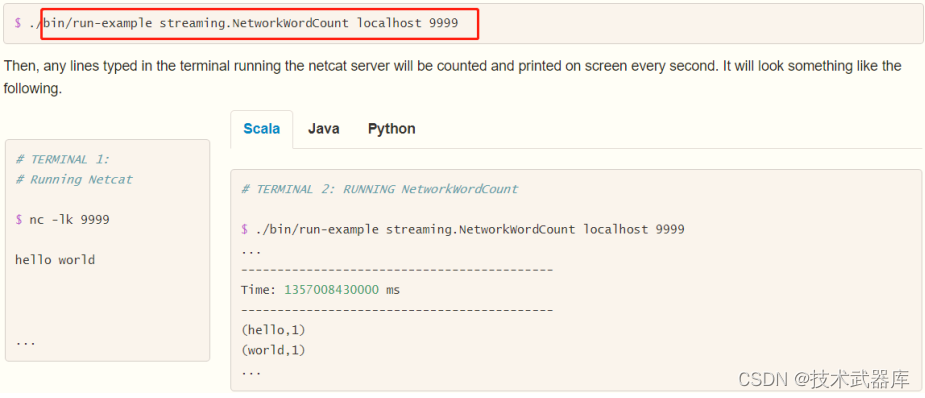
具体步骤如下:
第一步、准备数据源启动端口,准备数据
nc -lk 9999
spark spark hive hadoop spark hive
第二步、 运行官方案例
◼ 使用官方提供命令行运行案例
# 官方入门案例运行:词频统计
/export/server/spark/bin/run-example --master local[2] streaming.NetworkWordCount node1 9999
第三步、 运行结果

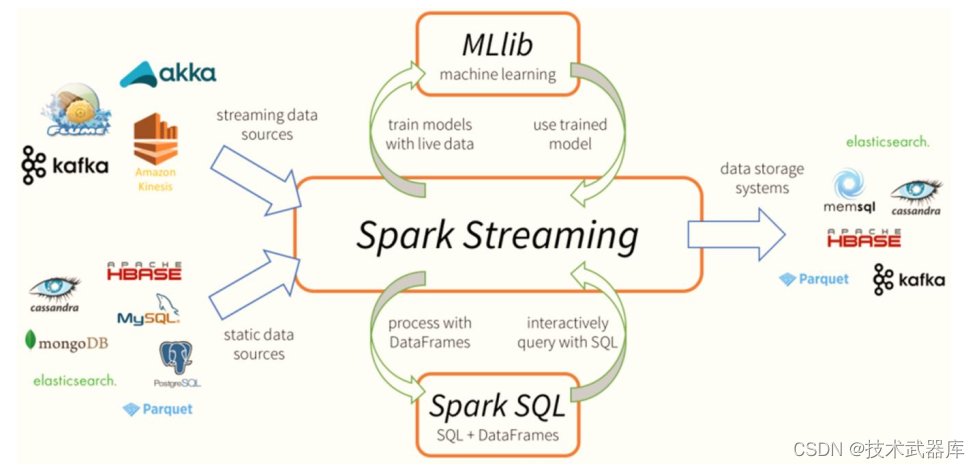
SparkStreaming模块对流式数据处理, 介于Batch批处理和RealTime实时处理之间处理数据方式。

编程实现
基于IDEA集成开发环境,编程实现: 从TCP Socket实时读取流式数据,对每批次中数据进行
词频统计WordCount。
StreamingContext
回顾SparkCore和SparkSQL及SparkStreaming处理数据时编程:
1)、 SparkCore
- 数据结构: RDD、 SparkContext:上下文实例对象
2)、 SparkSQL
- 数据结构: Dataset/DataFrame = RDD + Schema
- SparkSession:会话实例对象, 在Spark 1.x中SQLContext/HiveContext
3)、 SparkStreaming
- 数据结构: DStream = Seq[RDD]
- StreamingContext:流式上下文实例对象, 底层还是SparkContext
- 参数: 划分流式数据时间间隔BatchInterval: 1s, 5s(演示)
文档: http://spark.apache.org/docs/2.2.0/streaming-programming-guide.html#initializing-streamingcontext
从官方文档可知,提供两种方式构建StreamingContext实例对象,截图如下:
第一种方式: 构建SparkConf对象

第二种方式: 构建SparkContext对象

编写代码
针对SparkStreaming流式应用来说, 代码逻辑大致如下五个步骤:
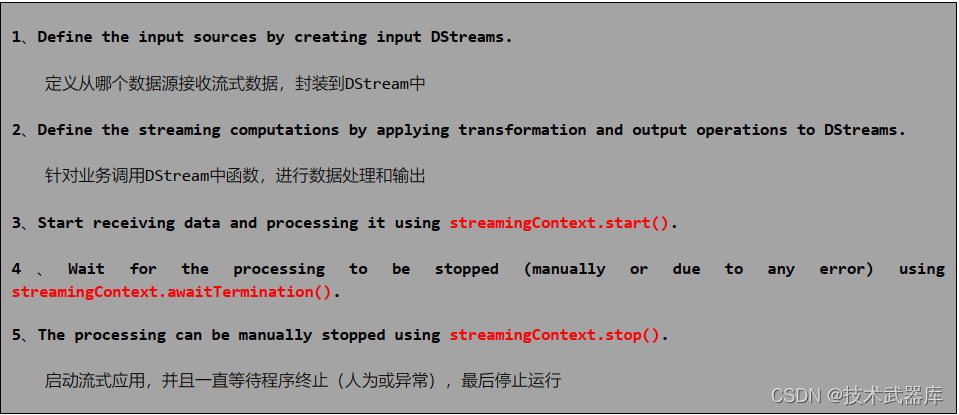
完整StreamingWordCount代码如下所示:
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 基于IDEA集成开发环境,编程实现从TCP Socket实时读取流式数据,对每批次中数据进行词频统计。
*/
object StreamingWordCount {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[3]")
// b.创建流式上下文对象, 传递SparkConf对象, TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
new StreamingContext(sparkConf, Seconds(5))
}
Logger.getRootLogger.setLevel(Level.WARN)
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.10.10", 9999)
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// TODO: 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
执行结果
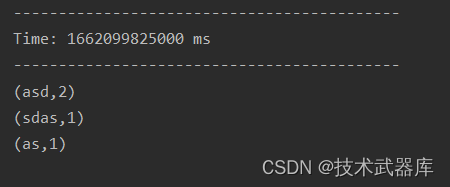
运行结果监控截图:

Streaming 应用监控
运行上述词频统计案例,登录到WEB UI监控页面: http://localhost:4040,查看相关监控信息。
其一、 Streaming流式应用概要信息
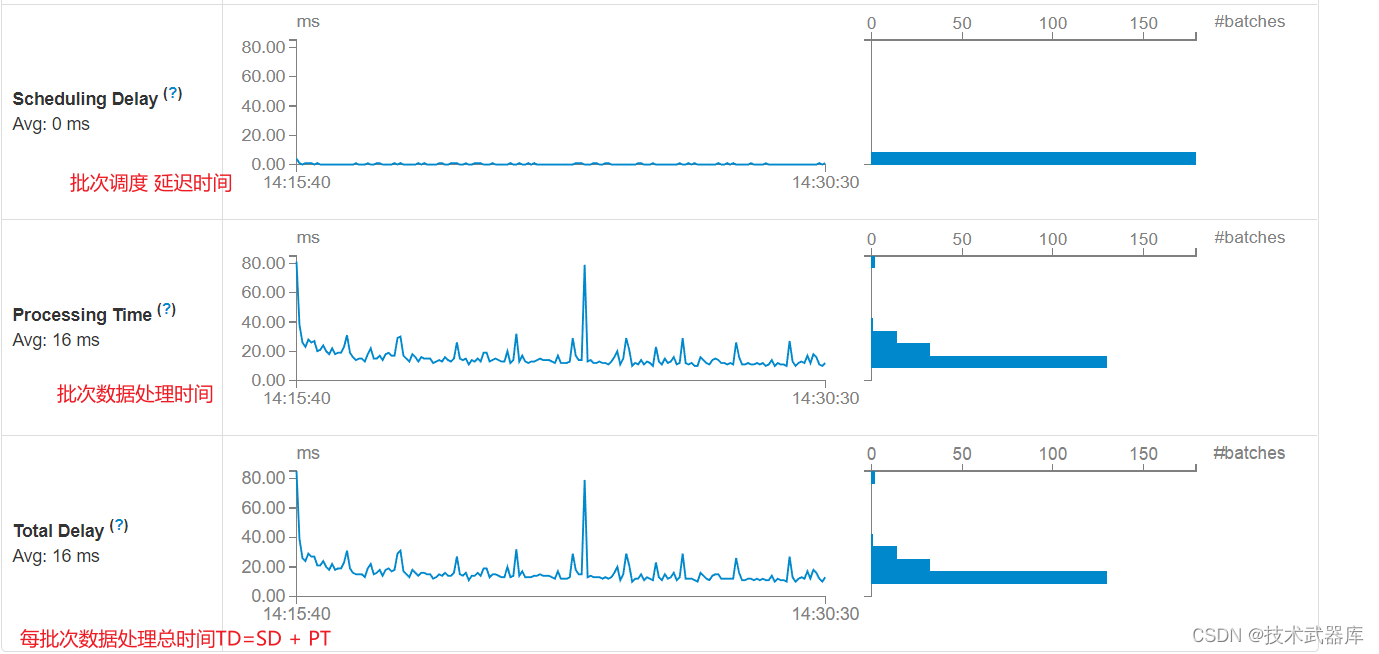
每批次Batch数据处理总时间TD = 批次调度延迟时间SD + 批次数据处理时间PT。

其二、性能衡量标准
SparkStreaming实时处理数据性能如何(是否可以实时处理数据)??如何衡量的呢??

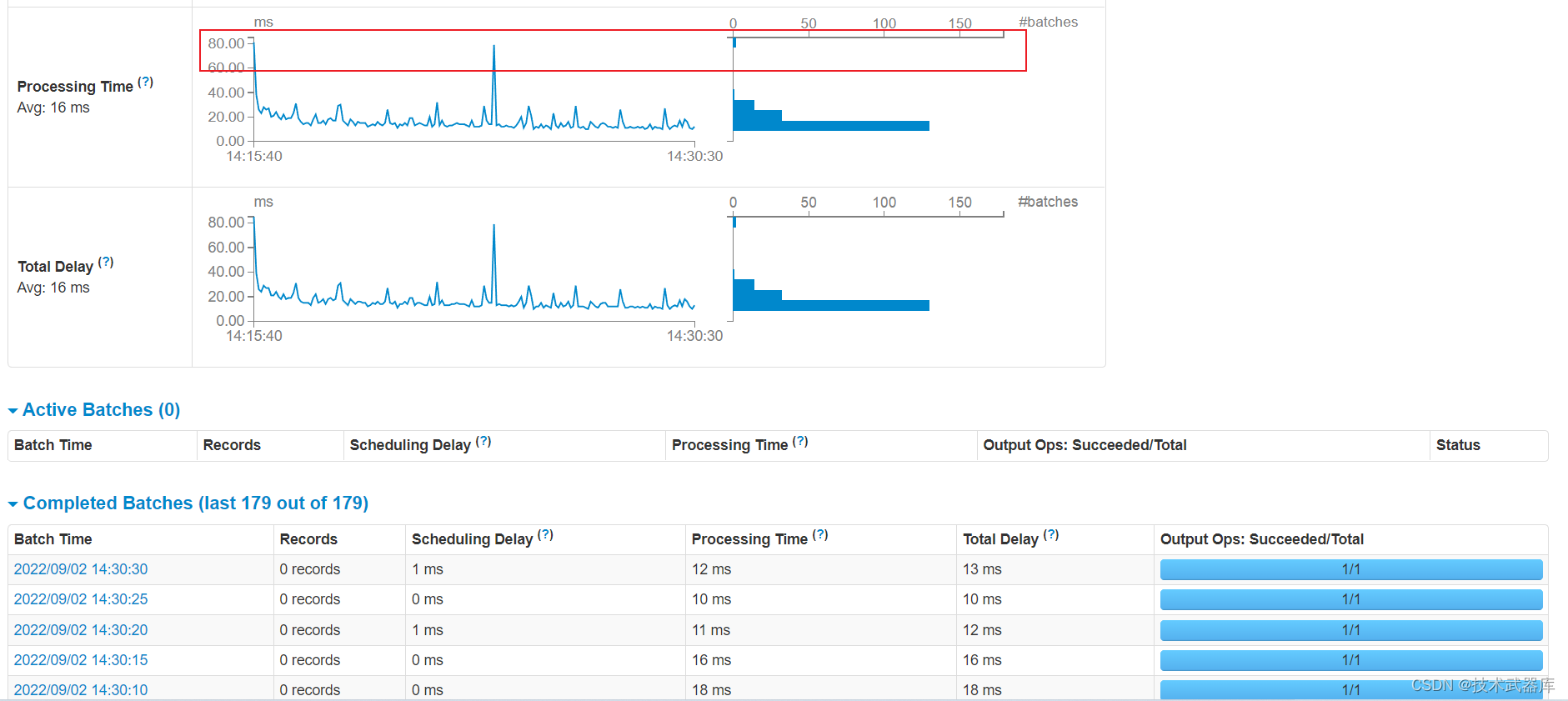
Streaming 工作原理
SparkStreaming处理流式数据时,按照时间间隔划分数据为微批次(Micro-Batch),每批次数
据当做RDD,再进行处理分析。

以上述词频统计WordCount程序为例,讲解Streaming工作原理。
创建 StreamingContext
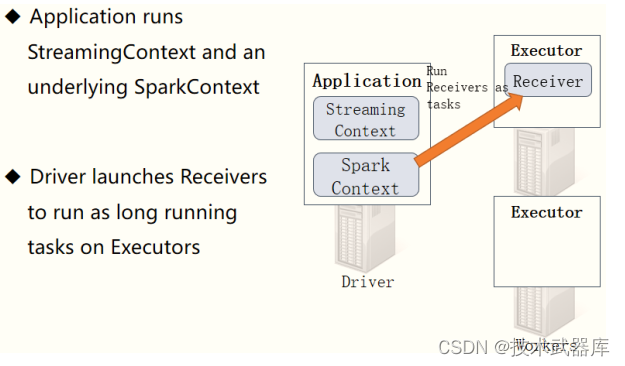
当SparkStreaming流式应用启动(streamingContext.start) 时,首先创建StreamingContext
流式上下文实例对象,整个流式应用环境构建,底层还是SparkContext。
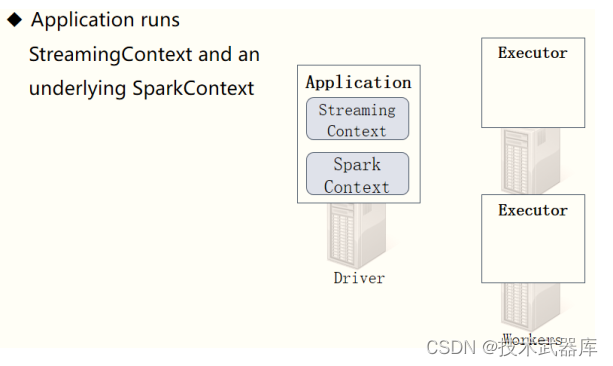
当StreamingContext对象构建以后, 启动接收器Receiver,专门从数据源端接收数据,此接收
器作为Task任务运行在Executor中,一直运行(Long Runing),一直接收数据。
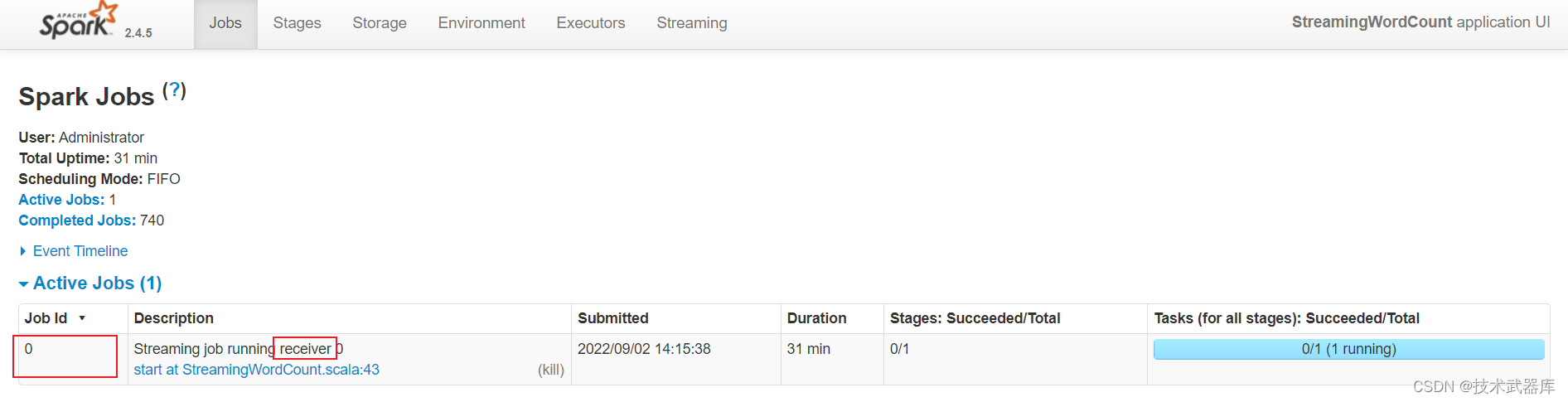
从WEB UI界面【Jobs Tab】可以看到【Job-0】是一个Receiver接收器,一直在运行,以Task
方式运行,需要1Core CPU。
可以从多个数据源端实时消费数据进行处理,例如从多个TCP Socket接收数据,对每批次数据
进行词频统计,使用DStream#union函数合并接收数据流,演示代码如下:
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* 从TCP Socket 中读取数据,对每批次(时间为5秒)数据进行词频统计,将统计结果输出到控制台。
* TODO: 从多个Socket读取流式数据,进行union合并
*/
object StreamingDStreamUnion {
def main(args: Array[String]): Unit = {
// TODO: 1. 构建StreamingContext流式上下文实例对象
val ssc: StreamingContext = {
// a. 创建SparkConf对象,设置应用配置信息
val sparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[4]")
// b.创建流式上下文对象, 传递SparkConf对象, TODO: 时间间隔 -> 用于划分流式数据为很多批次Batch
val context = new StreamingContext(sparkConf, Seconds(5))
// c. 返回
context
}
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream01: DStream[String] = ssc.socketTextStream("192.168.10.10", 9999)
val inputDStream02: DStream[String] = ssc.socketTextStream("192.168.10.10", 9988)
// 合并两个DStream流
val inputDStream: DStream[String] = inputDStream01.union(inputDStream02)
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
// 过滤不合格的数据
.filter(line => null != line && line.trim.length > 0)
// 按照分隔符划分单词
.flatMap(line => line.trim.split("\\s+"))
// 转换数据为二元组,表示每个单词出现一次
.map(word => (word, 1))
// 按照单词分组,聚合统计
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
// TODO: 5. 对于流式应用来说,需要启动应用
ssc.start()
// 流式应用启动以后,正常情况一直运行(接收数据、处理数据和输出数据),除非人为终止程序或者程序异常停止
ssc.awaitTermination()
// 关闭流式应用(参数一:是否关闭SparkContext,参数二:是否优雅的关闭)
ssc.stop(stopSparkContext = true, stopGracefully = true)
}
}
接收器接收数据
启动每个接收器Receiver以后,实时从数据源端接收数据(比如TCP Socket),也是按照时间
间隔将接收的流式数据划分为很多Block(块)。
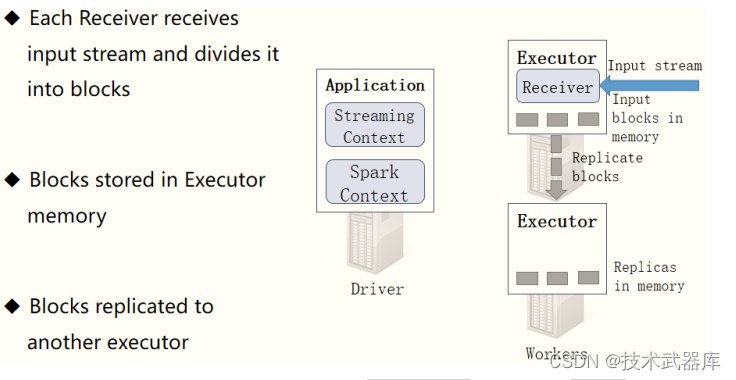
接收器Receiver划分流式数据的时间间隔BlockInterval ,默认值为200ms,通过属性
【spark.streaming.blockInterval】设置。接收器将接收的数据划分为Block以后,按照设置的存储
级别对Block进行存储,从TCP Socket中接收数据默认的存储级别为: MEMORY_AND_DISK_SER_2,先存储内存,不足再存储磁盘,存储2副本。
从TCP Socket消费数据时可以设置Block存储级别,演示代码如下:
// TODO: 2. 从数据源端读取数据,此处是TCP Socket读取数据
/*
def socketTextStream(
hostname: String,
port: Int,
storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
): ReceiverInputDStream[String]
*/
val inputDStream: ReceiverInputDStream[String] = ssc.socketTextStream("192.168.10.10", 9999,
// TODO: 设置Block存储级别为先内存,不足磁盘,副本为1
storageLevel = StorageLevel.MEMORY_AND_DISK
)
汇报接收Block报告
接收器Receiver将实时汇报接收的数据对应的Block信息,当BatchInterval时间达到以后,
StreamingContext将对应时间范围内数据block当做RDD,加载SparkContext处理数据。
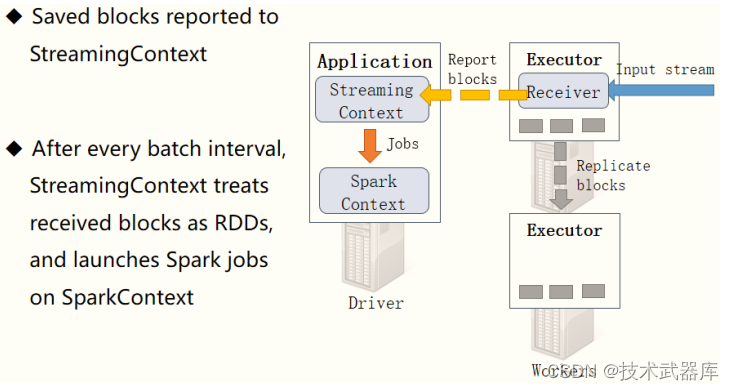
以此循环处理流式的数据,如下图所示:
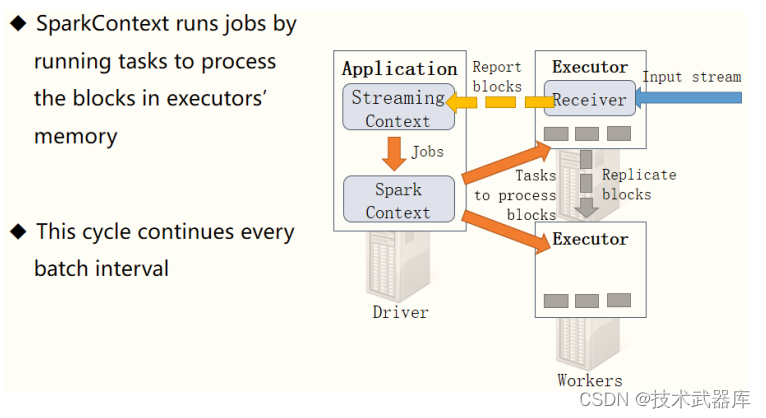
Streaming 工作原理总述
整个Streaming运行过程中,涉及到两个时间间隔:
批次时间间隔: BatchInterval
- 每批次数据的时间间隔,每隔多久加载一个Job;
Block时间间隔: BlockInterval
-
接收器划分流式数据的时间间隔,可以调整大小哦,官方建议最小值不能小于50ms;
-
默认值为200ms,属性: spark.streaming.blockInterval, 调整设置
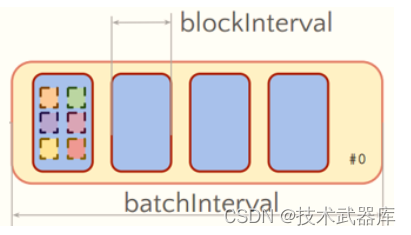

从代码层面结合实际数据处理层面来看, Streaming处理原理如下,左边为代码逻辑,右边为
实际每批次数据处理过程。

具体运行数据时,每批次数据依据代码逻辑执行。
// TODO: 3. 对每批次的数据进行词频统计
val resultDStream: DStream[(String, Int)] = inputDStream
.filter(line => null != line && line.trim.length > 0)
.flatMap(line => line.trim.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
// TODO: 4. 将结果数据输出 -> 将每批次的数据处理以后输出
resultDStream.print(10)
流式数据流图如下:


















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











