







本文将会介绍四个Demo案例,分别是updateStateByKey算子的使用,SparkStreaming写入MySQL,窗口函数使用和黑名单过滤。。。
案例一、updateStateByKey算子的使用
首先先看一下updateStateByKey的介绍

这个算子可以在保持任意状态下去更新信息,但是有两个要求:
- 状态可以是任意类型
- 定义状态的更新,要用函数指定更新前的状态和更新后的状态
需求:统计到目前为止累计出现的单词的个数(需要保持以前的状态)

调用的那个函数,看一下官网案例:

要维护文本数据流中看到的每个单词的运行计数(也就现在这个状态),在这里,运行状态是Int类型的,会自动给输入的字段进行更新函数的调用,传入进来的Seq举个例子就是像(a,1)(b,1)这样的会记录下来,然后去操作但是不管操作如何,都会执行runningCount,把旧的序列进行聚合操作。但是为什么新数据是Seq属性,老数据是Option呢?因为也许这里会产生新的值,那么老的值肯定就不存在,是Null,所以要用Option。

旧数据执行的是getOrElse(0),是因为不确定旧数据是否是存在的。。。
使用的算子是stateful的,因为要用StreamingContext声明一个checkpoint

案例二、计算累计出现的单词个数并写去MySQL
操作是相似的,下面会用到foreach操作,来看一下:
算子作用于一个函数通过流产生的每一个RDD,然后推送到外部系统,基本都用于流操作中。。
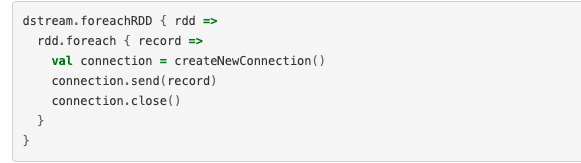
不要在Spark驱动程序中创建连接对象,然后尝试在Spark工作程序中使用它来保存RDD中的记录,否则会出现问题,就是下面这样:
这是不对的,产生序列化错误,因为工作的地方和连接产生的地方是不同的,正确方方法是在worker中创建连接,但是又会产生另外一个问题:
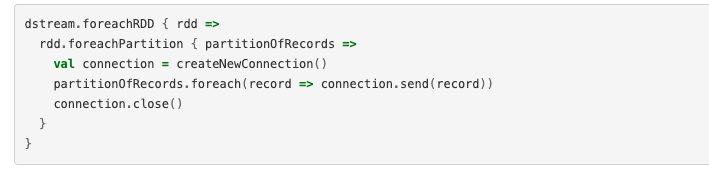
做到了在工作的地方建立连接,但是相对的又会产生很多资源消耗,因为要使用 rdd.foreachPartition用一个连接,推送一个分区内所有的记录:
但是如果有的时候需要分开推送,有的推送有的不推送那又怎么办呢?需要使用到连接池技术:




下面来看一下程序:需求是将统计结果写入到MySQL数据库中

案例三、窗口函数的使用
==window:==定时的进行一个时间段内的数据处理。。。
下面来看一下官方的介绍:
在固定时间范围的情况下,捕捉该范围的数据进行操作,并且操作之后会滑动一定的时间单位,不断的去进行运算,使用窗口函数需要制定两个参数:
- 窗口长度 - 窗口的持续时间(图中的3)
- 滑动间隔 - 执行窗口操作的间隔(图中的2)
而且既然滑动了,那么就不能有重复的计算,所以滑动的记录要求一定得是窗口长度的整倍数。。。
官网的例子:
代表每10秒执行前30秒的data,并且除此之外还有一些其他的API,但是所含参数必须要有上面提到的两个参数



案例四、黑名单过滤
需要两个步骤:第一是使用transform算子,然后使用SparkStreaming整合RDD进行操作

最关键的一步是:需要的是将端口输入的(k,v)形式的消息,取出value值也就是姓名,拿去判断,因为输入进来的信息之间有逗号,所以Scala使用.split(",")分开然后取出第二个值,取出输入的姓名之后就要拿去和blackRDD去对比了,因此需要filter操作,这个时候过滤之前的值应该是(<20180808,zs>,),过滤之后的目的就是,只删选出第二个值为true的姓名,然后将姓名重新组合成map。。。















 354
354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









