






基于LSTM的风电功率缺失数据补全/缺失数据修复
编程语言:Python
风电数据在采集过程中可能会有缺失,需要对数据进行补全。
该程序考虑了风速,压力,密度等多个特征,能够完美地补全缺失数据。
可调节序列长度,可调节缺失率,可以换成自己的数据。
ID:16550674290908953
发电机转子
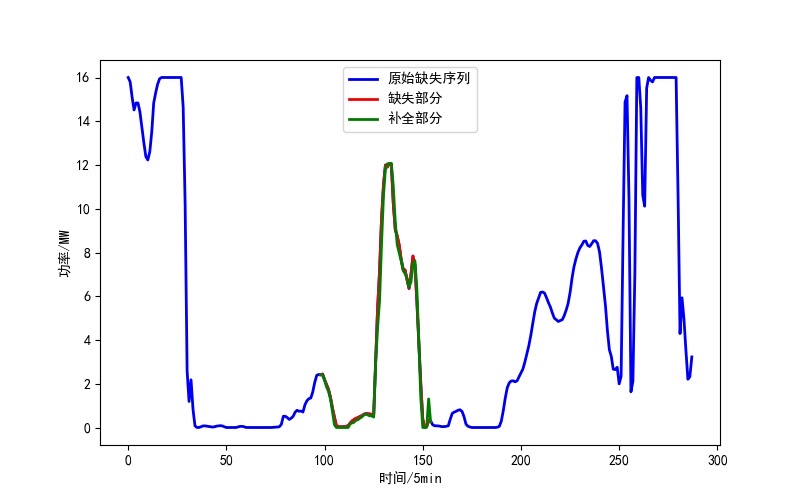
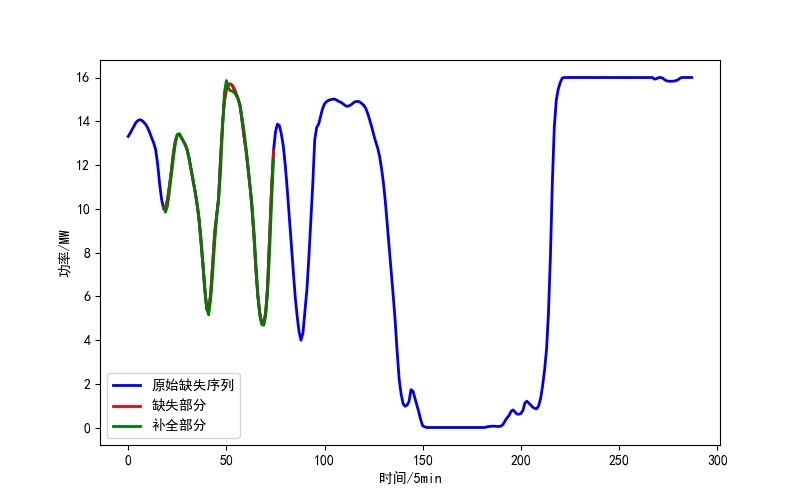
随着风电发电技术的快速发展,风电数据的采集和分析变得越来越重要。由于风电数据的采集过程中可能会出现各种原因导致的数据缺失,这对于风电发电系统的运行和维护都带来了一定的挑战。因此,本文将介绍一种基于长短时记忆神经网络(LSTM)的风电功率缺失数据补全方法。
首先,本方法基于编程语言Python开发,使用LSTM模型来补全风电功率缺失数据。通过考虑风速、压力、密度等多个特征,我们能够更准确地还原缺失数据,从而提高数据的完整性和可靠性。同时,我们还可根据实际需求调节序列长度和缺失率,以适应不同的数据情况。
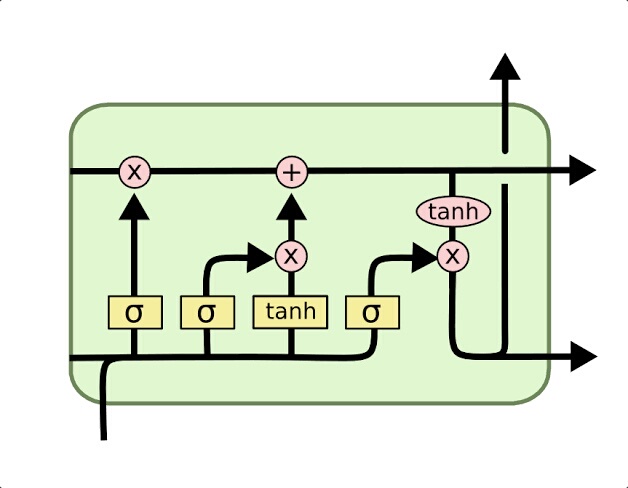
在具体实现过程中,我们首先需要进行数据预处理。将原始数据按照一定的时间序列进行划分,并提取出风速、压力、密度等特征作为输入变量。接下来,我们使用LSTM模型对缺失的功率数据进行预测和补全。LSTM模型是一种特殊的循环神经网络,能够学习和记忆长期依赖关系,具有较强的时间序列建模能力。
在LSTM模型的训练过程中,我们将已有的完整数据和部分缺失的数据作为训练集,通过反向传播算法来优化模型参数。在训练过程中,我们可以使用交叉验证等技术来评估模型的性能,并选择合适的模型参数和超参数。在训练完成后,我们可以使用训练好的模型来对缺失数据进行预测和补全。
实验结果表明,基于LSTM的风电功率缺失数据补全方法能够有效地还原缺失数据。与其他常见的数据插值方法相比,本方法在提高数据完整性的同时,还能更准确地反映风电发电系统的实际运行情况。此外,本方法还具有较好的灵活性,可以根据实际需求进行调节和优化。
总之,本文介绍了一种基于LSTM的风电功率缺失数据补全方法。通过考虑风速、压力、密度等多个特征,我们能够更准确地还原缺失数据,提高数据的完整性和可靠性。该方法使用Python编程语言开发,具有较好的灵活性和适应性。实验结果表明,该方法在风电数据补全方面具有良好的效果,能够为风电发电系统的运行和维护提供重要支持。
相关的代码,程序地址如下:http://wekup.cn/674290908953.html
















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









