







目录
复现环境:
| 系统 | 版本 |
|---|---|
| Windows | 11 |
| CUDA | 12.6.2 |
| cuDNN | 9.5.0 |
| Python | 3.12 |
| PyTorch | 2.6.0 |
CUDA查看
首先我们需要看一下操作系统是否支持GPU。打开任务管理器,点击性能,如图:
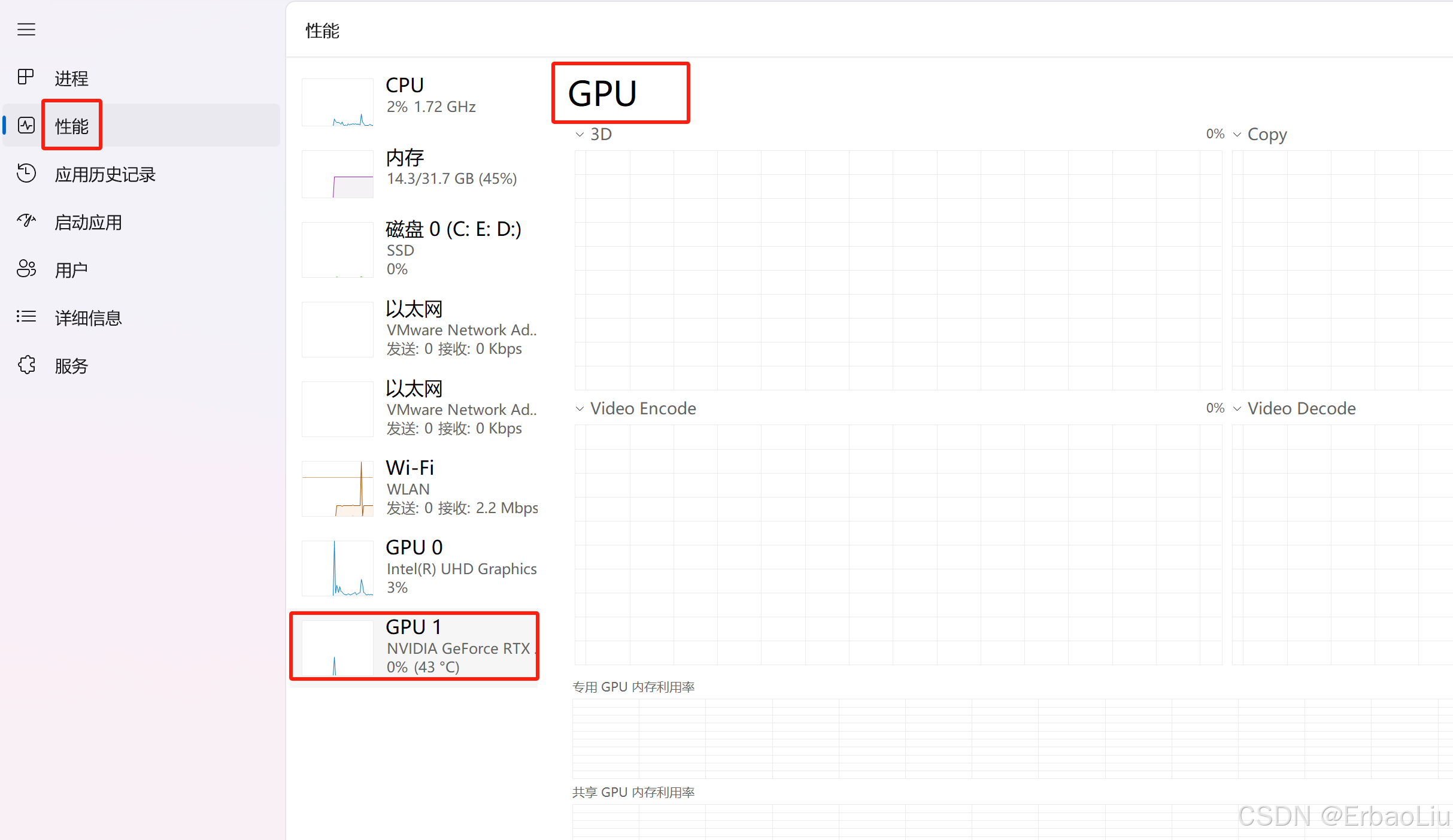
这表明作者电脑支持GPU计算。如果电脑不支持GPU,后续操作也就不需要了,只能使用CPU进行深度学习。在Windows11中显示的GPU 0和GPU 1表示你的计算机中检测到了多个图形处理单元(GPU),最常见是集成显卡 + 独立显卡,GPU 0:通常是集成显卡(Integrated GPU,如 Intel UHD Graphics、AMD Radeon Vega 等),集成在CPU中,功耗低,适合日常办公和轻度任务。GPU 1:通常是独立显卡(Dedicated GPU,如 NVIDIA GeForce、AMD Radeon、Intel ARC 等),性能更强,用于游戏、设计、3D 渲染等高性能需求。如果你的电脑安装了多块独立显卡(如 NVIDIA SLI/AMD CrossFire 配置、或工作站多卡并行),则:GPU 0 和 GPU 1 可能代表两块独立的显卡(如两块 NVIDIA RTX 显卡)。这种配置常见于高性能计算、深度学习或多屏输出需求。
下面开始安装CUDA。
CUDA(Compute Unified Device Architecture)是显卡厂商NVIDIA推出的一种通用并行计算架构,旨在利用GPU(图形处理器)进行高性能计算。CUDA是利用GPU进行高性能计算的一个工具包。
执行如下命令,检查操作系统是否已经安装了CUDA:
nvcc -V如果执行命令后,如图:

说明并未安装CUDA。 如果已经安装,执行命令后,应该有对应信息显示,如下:

假设读者并未安装CUDA。首先我们需要确认安装什么版本的CUDA,可以执行如下命令,查看Windows操作系统NVIDIA GPU的驱动版本以及支持的CUDA最高版本:
nvidia-smi如图:
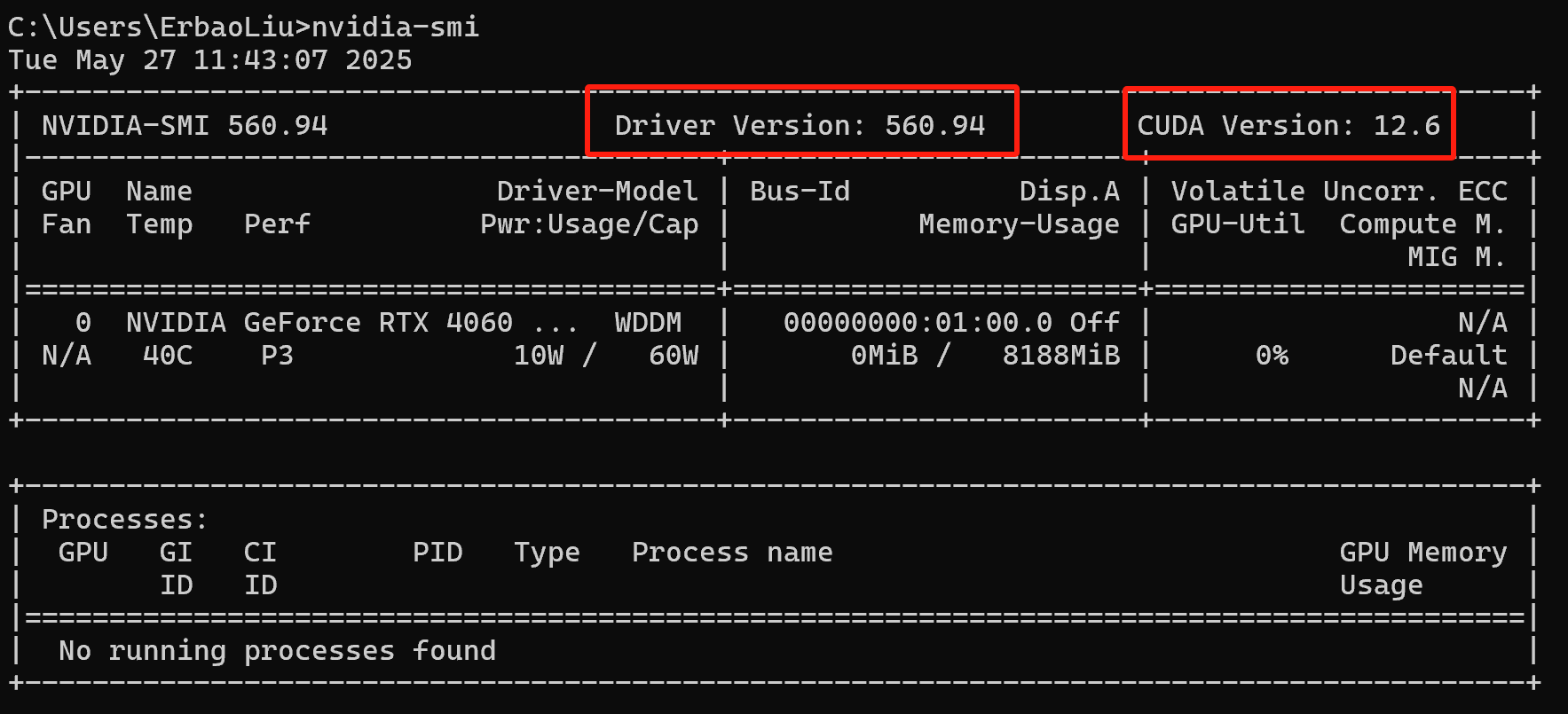
可以看到NVIDIA显卡的驱动版本为560.94,支持的CUDA最高版本为12.6。
NVIDIA的显卡驱动程序和CUDA是两个不同的概念!CUDA是NVIDIA推出的使用GPU进行计算的一个工具包(TooKit)。如果没有显卡驱动根本用不了显卡,因此当我们使用一台电脑的时候默认会已经安装NVIDIA的显卡驱动,例如作者驱动版本为560.94,我们可以更新我们的驱动,更新链接为:
https://www.nvidia.com/Download/index.aspx?lang=en-us
在这个里面可以根据自己的显卡类型选择最新的驱动程序。在windows上进行深度学习的代码需要使用CUDA工具包来使用GPU进行高性能计算,这也是我们需要安装CUDA的原因。
登录如下地址,可以查看CUDA版本和对应的NVIDIA GPU驱动版本兼容表格:
CUDA 12.6 Update 2 Release Notes
如图:
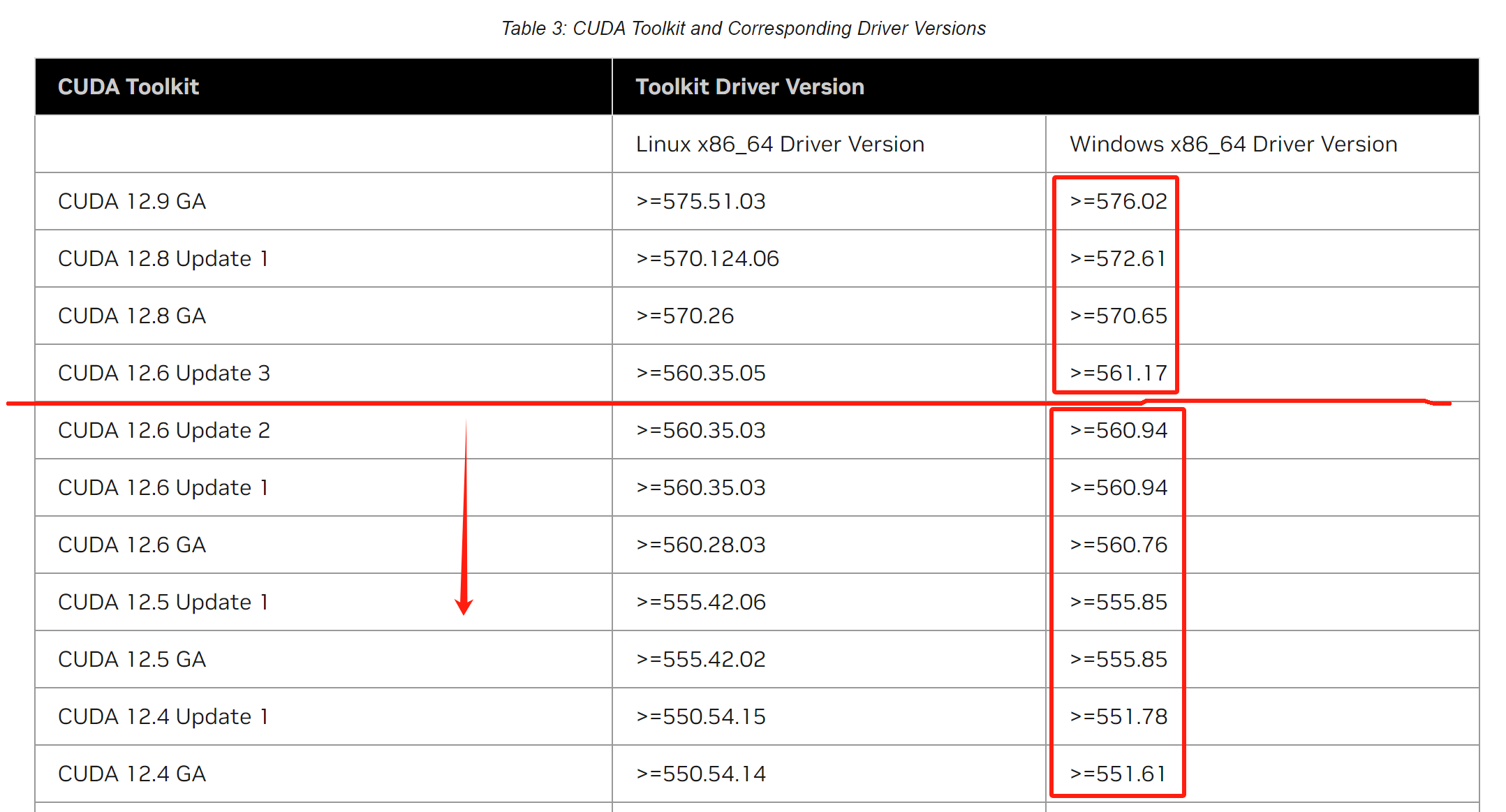
可以看到CUDA版本不高于CUDA 12.6 Update 2版本均可。
CUDA下载
CUDA下载地址如下:
CUDA Toolkit Archive | NVIDIA Developer
如图:
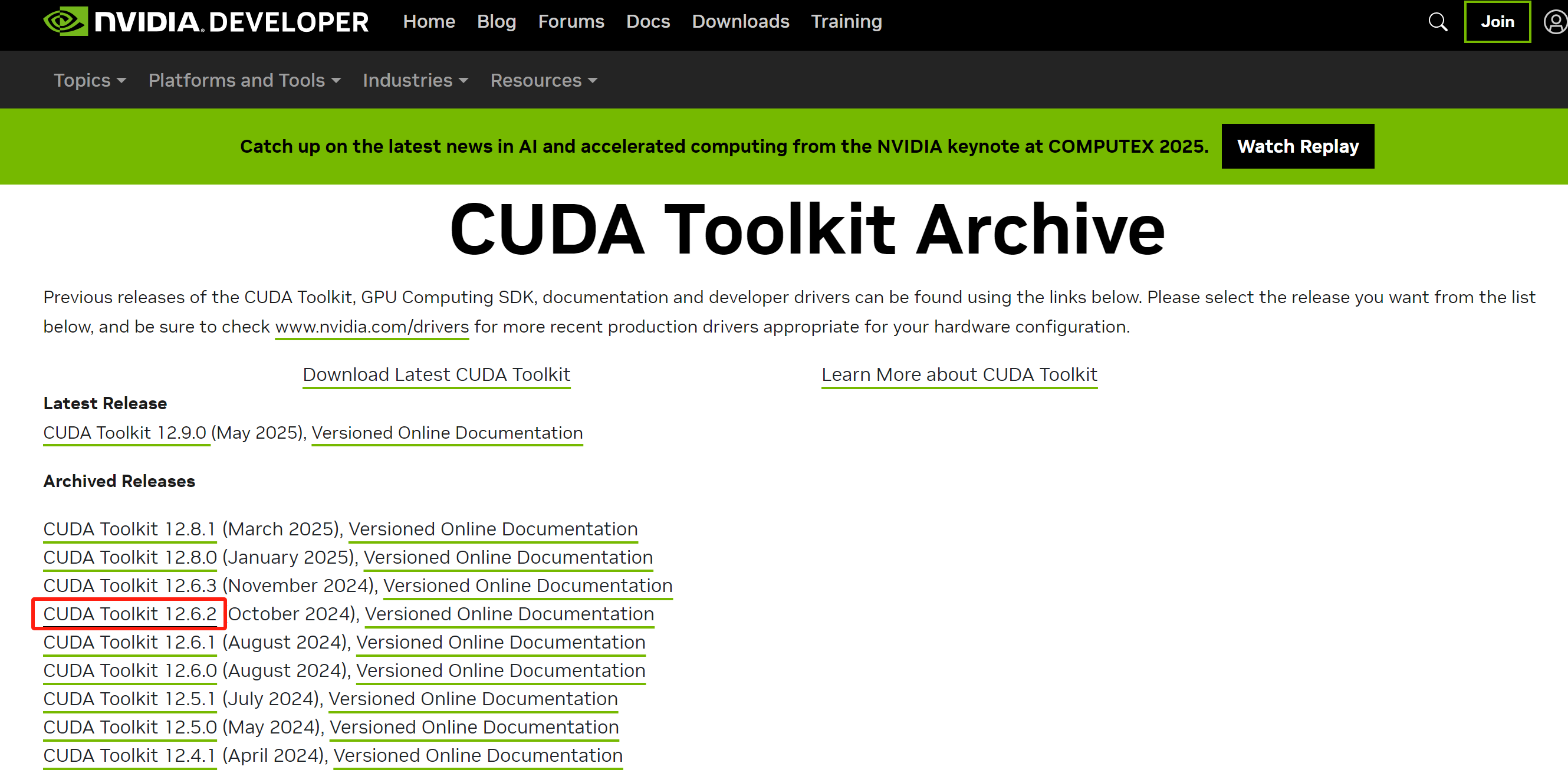
选择对应的版本,例如作者选择CUDA Toolkit 12.6.2。点击后如图:
选择对应的操作系统,例如作者选择Windows,如图:
依次选择对应操作系统配置,如图:
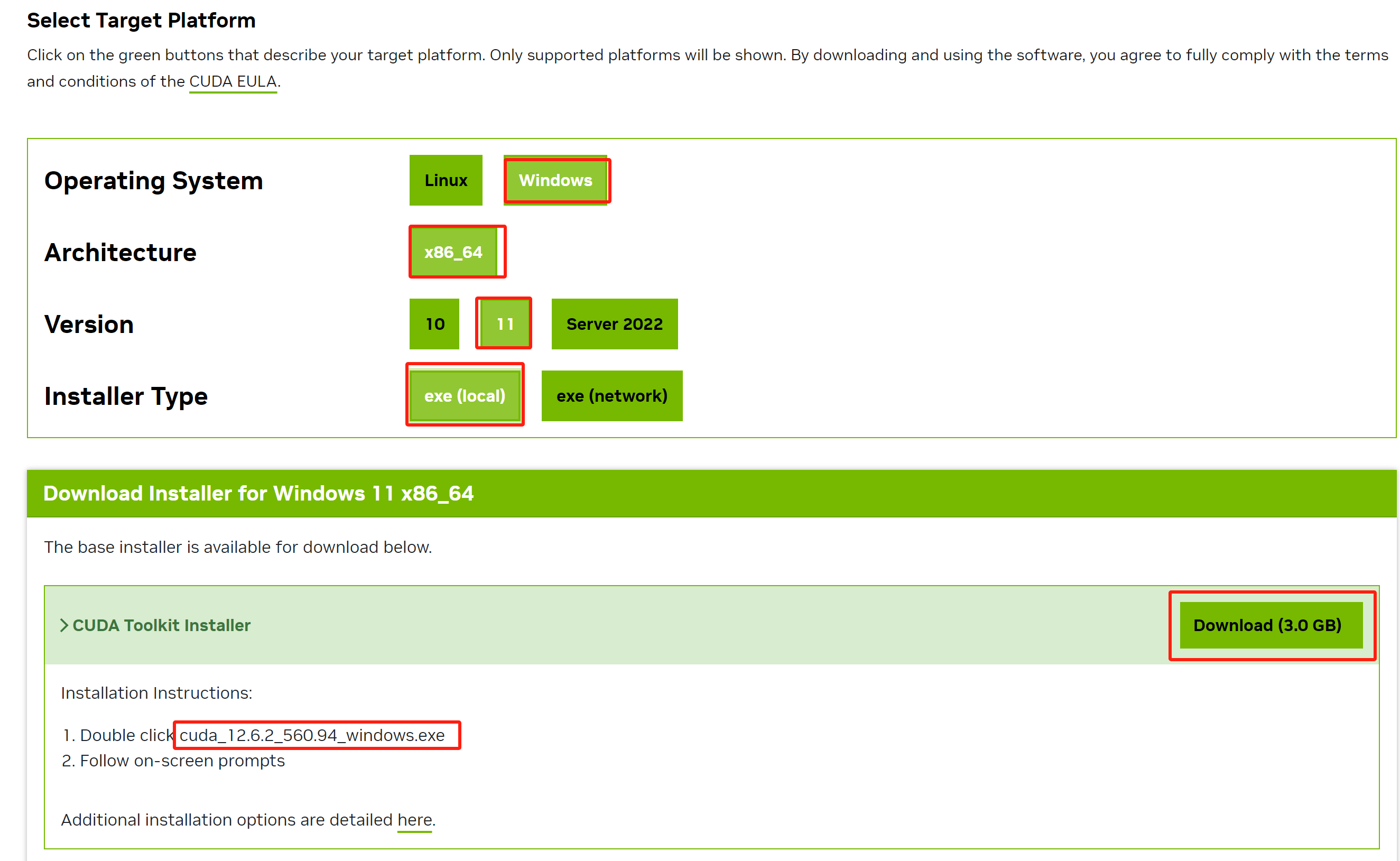
点击Download下载CUDA。下载成功后,安装包名称如下:
cuda_12.6.2_560.94_windows.exe
安装包的名称上正好对应CUDA版本以及显卡驱动版本。
CUDA安装
双击下载的CUDA安装可执行程序,需要选择一个临时目录存放抽取的安装包(安装完成后会自动删除临时目录、安装的目标目录在后面选择),如图:

下面按照步骤安装即可:
选择自定义,如图:
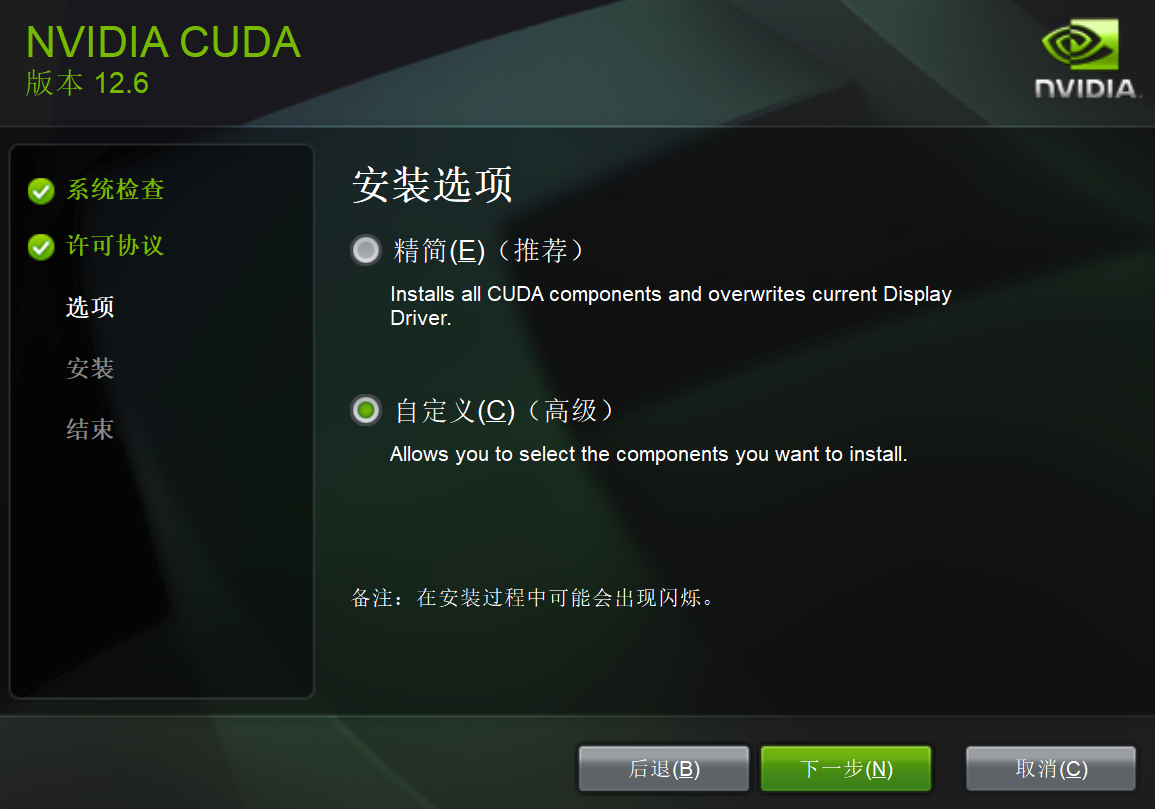
点击下一步,如图:
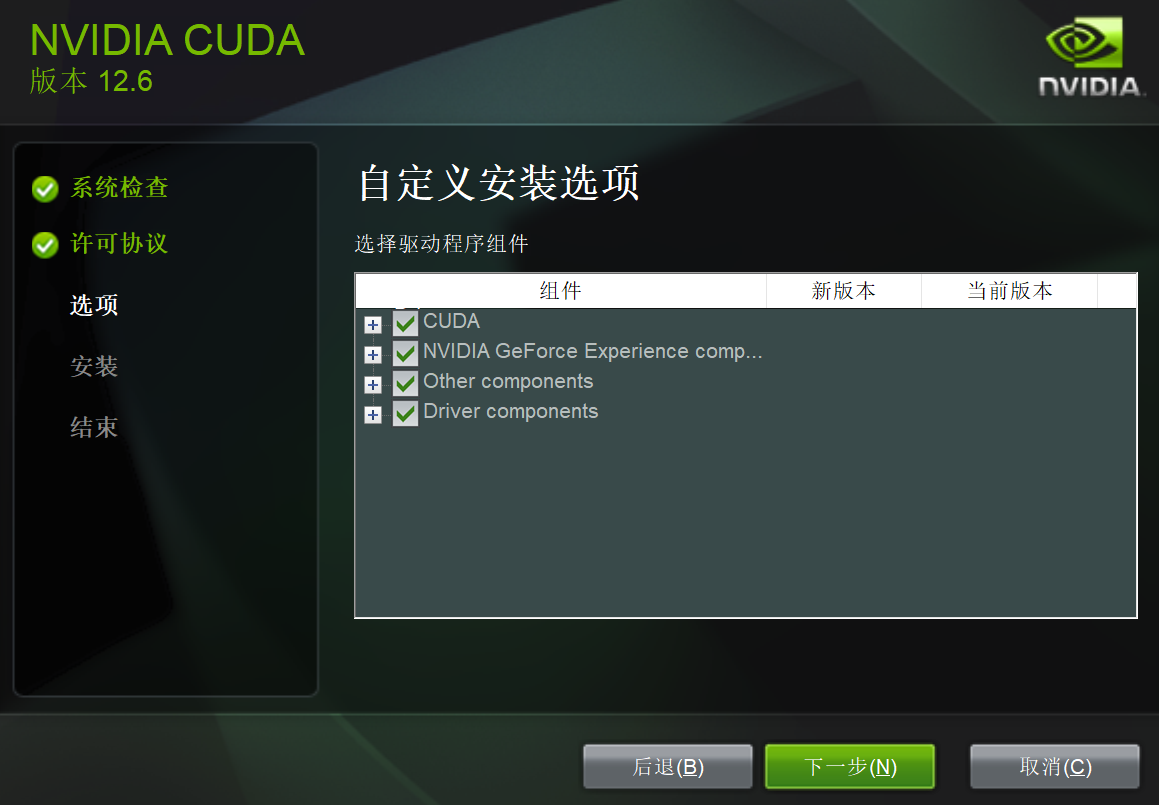
继续点击下一步,需要选择安装的目录,选择好安装目录后,如图:
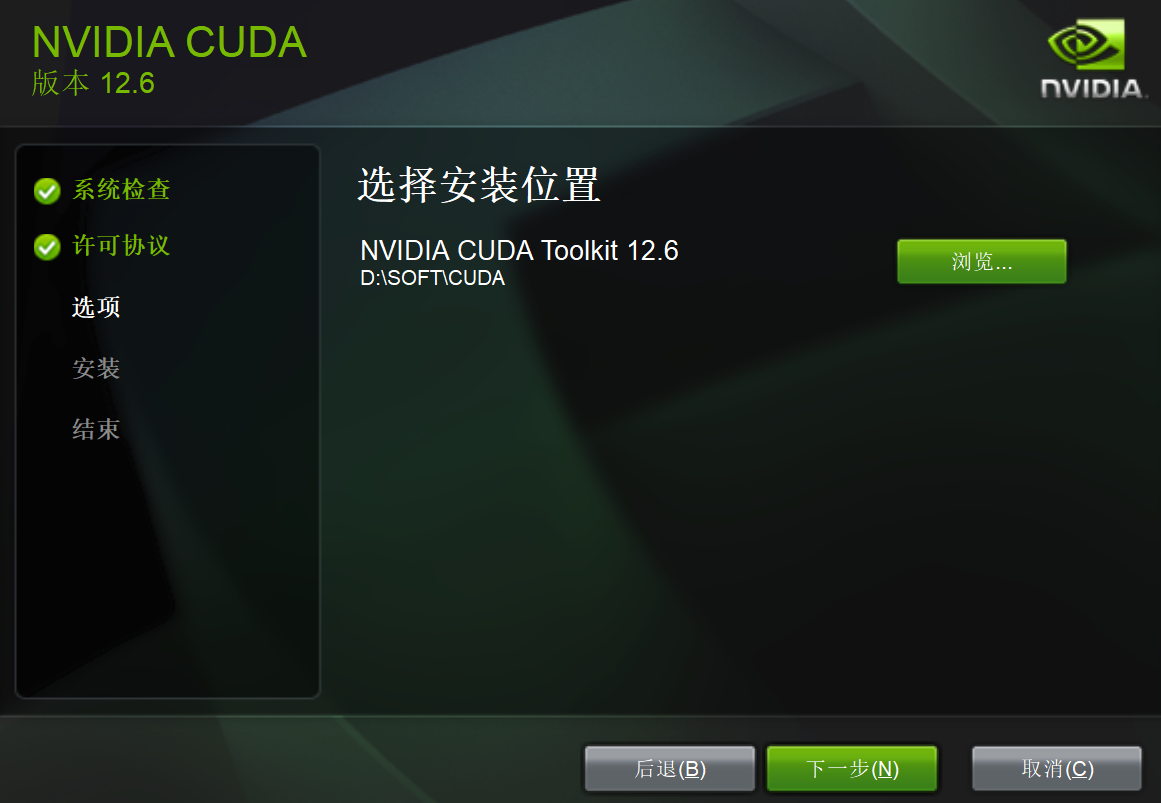
点击下一步,如图:
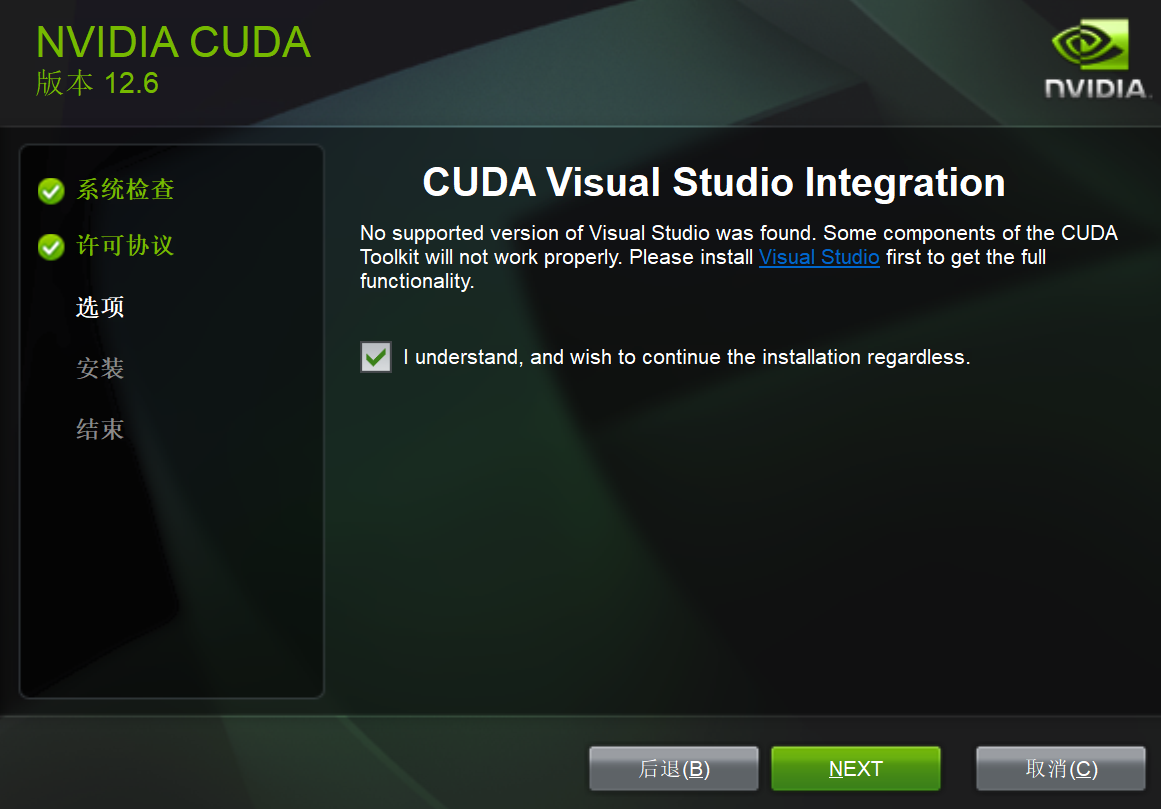
点击NEXT,如图:
点击下一步,如图:
点击关闭,安装完成。
打开命令窗口,执行如下命令,检查是否安装成功:
nvcc -V结果如图:

表示已经安装成功。
cuDNN安装
cuDNN(CUDA Deep Neural Network library)是一个由NVIDIA开发的深度学习GPU加速库,旨在为深度学习任务提供高效、标准化的原语(基本操作)来加速深度学习框架在NVIDIA GPU上的运算。
cuDNN安装需要先注册账号。登录如下地址:
cuDNN 9.5.0 Downloads | NVIDIA Developer
登录成功后,如图:
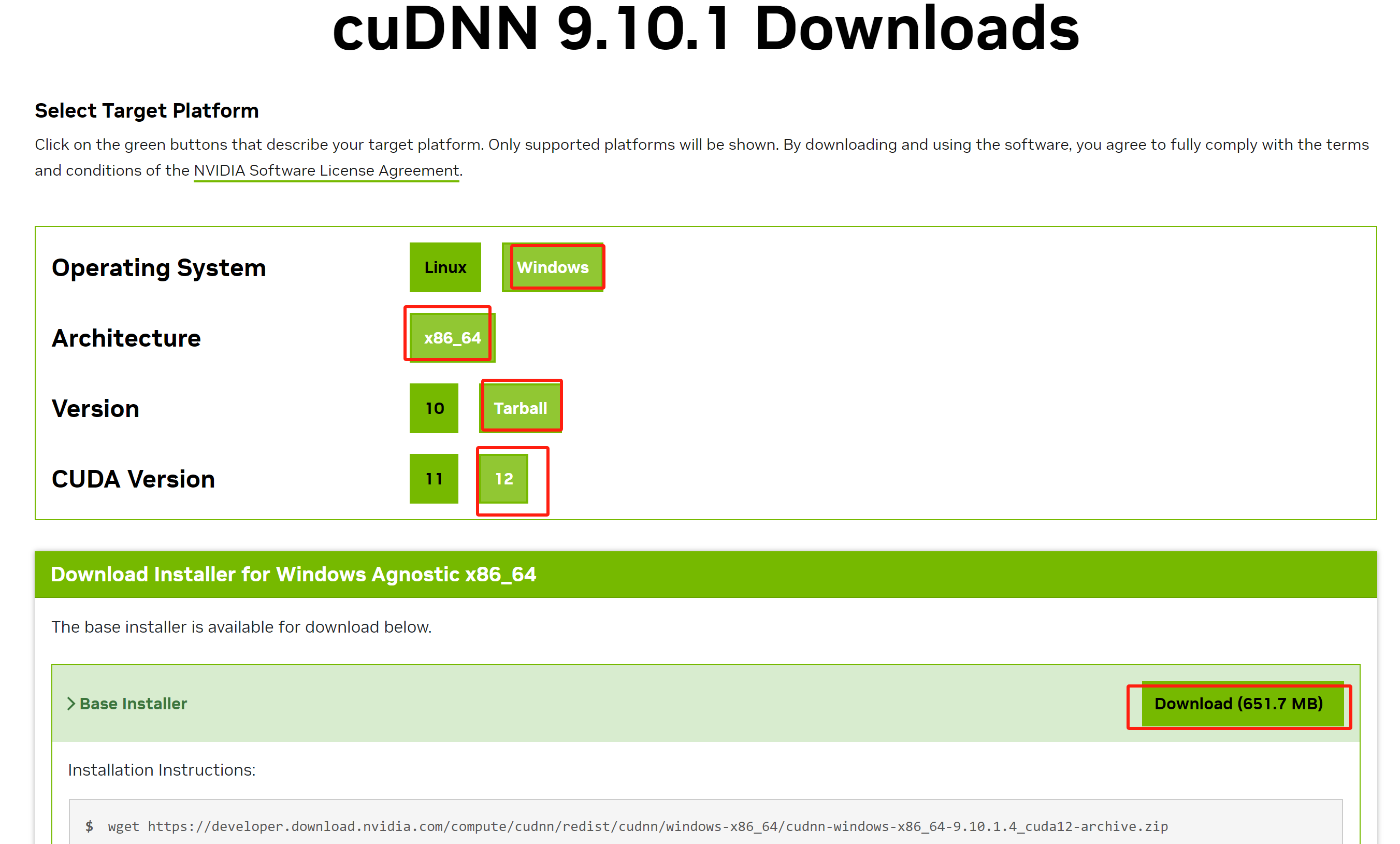
选择对应版本进行下载。如果当前界面没有你需要的版本,可访问如下历史版本页面进行下载:
https://developer.nvidia.com/rdp/cudnn-archive
如图:
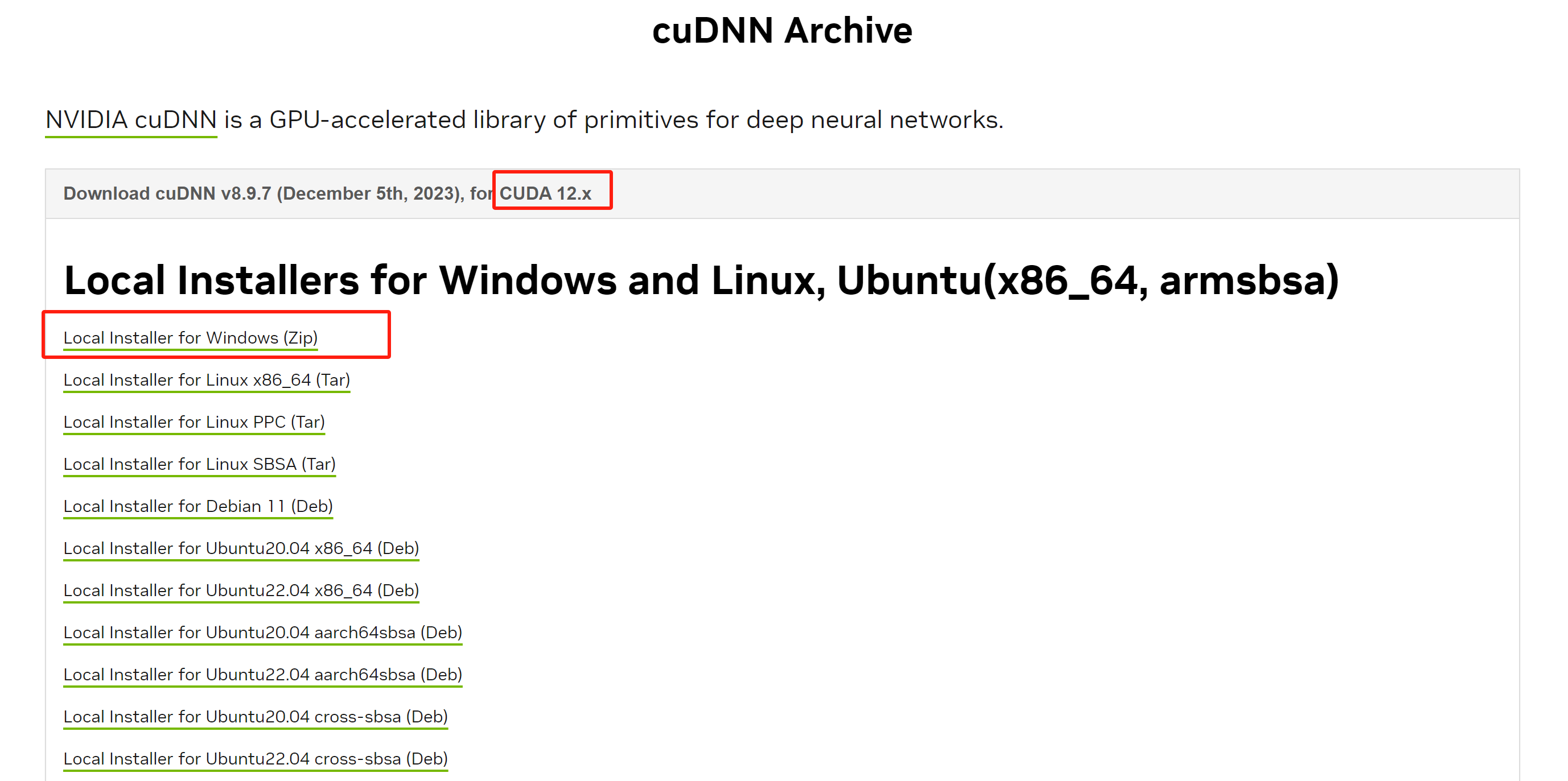
下载完成后,安装包名称如下:
cudnn-windows-x86_64-9.10.1.4_cuda12-archive.zip
解压后,目录结构如图:

将目录bin、lib、include复制到CUDA的安装目录下(LICENSE除外),可以先对CUDA安装目录下的这三个目录做备份,以免出现覆盖无法恢复。如图:
如果复制过程中出现重复提醒,只是目录重复,里面的文件并不重复,可直接替换。cuDnn的所有文件都是以cudnn开头。例如:

最后将如下path添加到环境变量Path中:
D:\SOTF\CUDA\bin
D:\SOTF\CUDA\include
D:\SOTF\CUDA\lib
D:\SOTF\CUDA\libnvvp配置完成后,我们可以验证是否配置成功,主要使用CUDA内置的deviceQuery.exe 和 bandwithTest.exe:
首先win+R启动cmd,cd到CUDA安装目录下的 …\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe,应该得到下图:
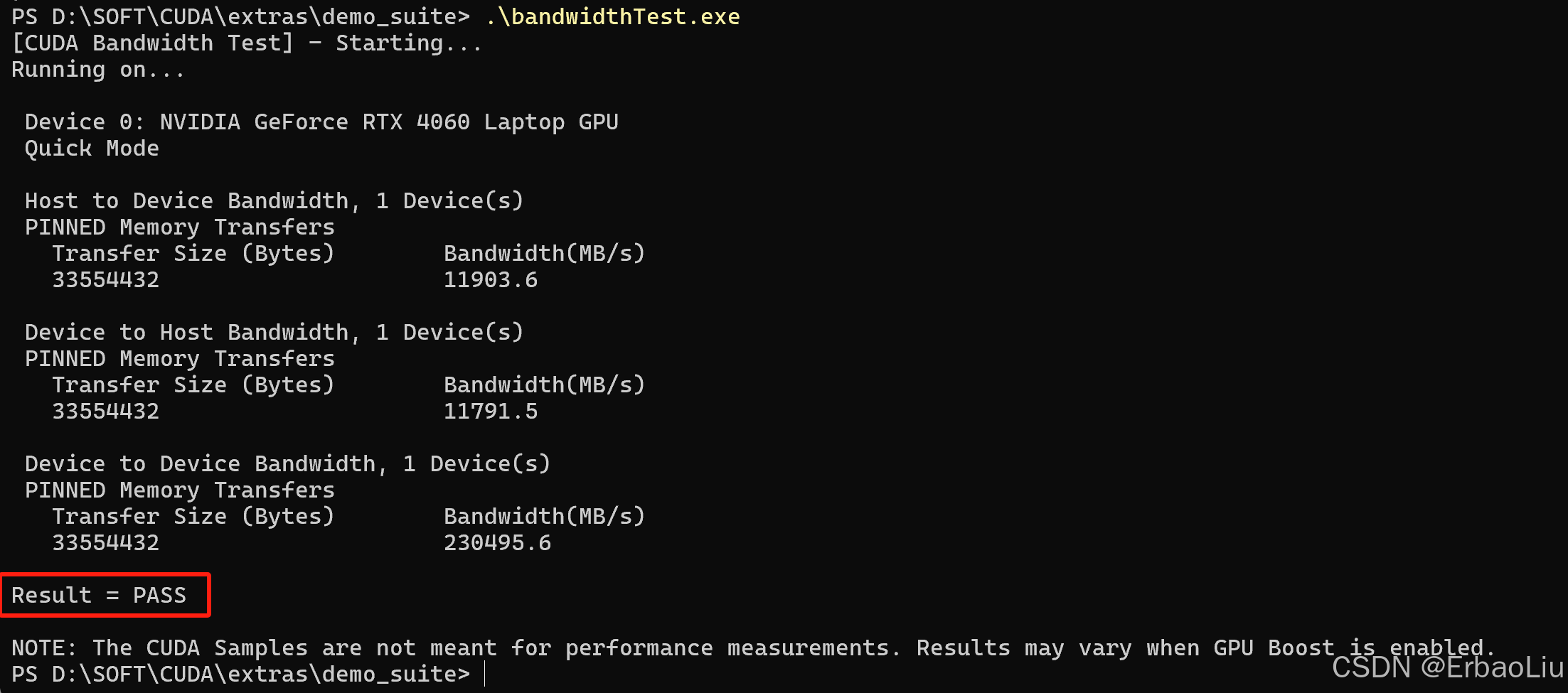
执行bandwidthTest.exe,如图:
执行deviceQuery.exe,如下:
PS D:\SOFT\CUDA\extras\demo_suite> .\deviceQuery.exe
D:\SOFT\CUDA\extras\demo_suite\deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 4060 Laptop GPU"
CUDA Driver Version / Runtime Version 12.6 / 12.1
CUDA Capability Major/Minor version number: 8.9
Total amount of global memory: 8188 MBytes (8585216000 bytes)
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
MapSMtoCores for SM 8.9 is undefined. Default to use 128 Cores/SM
(24) Multiprocessors, (128) CUDA Cores/MP: 3072 CUDA Cores
GPU Max Clock rate: 1890 MHz (1.89 GHz)
Memory Clock rate: 8001 Mhz
Memory Bus Width: 128-bit
L2 Cache Size: 33554432 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.6, CUDA Runtime Version = 12.1, NumDevs = 1, Device0 = NVIDIA GeForce RTX 4060 Laptop GPU
Result = PASS
PS D:\SOFT\CUDA\extras\demo_suite>PyTorch安装
PyTorch是一个开源的深度学习框架,主要用于构建和训练深度学习模型。 它是由Facebook的AI研究实验室(FAIR)开发的,以其灵活性和易用性著称,特别适合于图像识别、自然语言处理等应用。PyTorch使用Python编写,这使得它对于大多数机器学习开发者和数据科学家来说,学习和使用起来相对简单。PyTorch的核心特点包括:12
- 动态计算图:与TensorFlow的静态计算图不同,PyTorch的计算图是动态的,可以根据计算需要实时改变,这使得实验和原型设计变得非常快速和灵活。
- GPU加速:PyTorch完全支持GPU,能够利用GPU的强大计算能力来加速深度学习模型的训练过程,这对于大规模数据处理尤为重要。
- 自动微分:PyTorch使用反向模式自动微分技术,可以自动计算梯度,这对于训练深度学习模型至关重要。
- 模块化设计:PyTorch提供了丰富的模块和工具,如torch.nn用于构建神经网络,torch.optim用于优化模型参数,torch.autograd用于自动微分等,这使得构建和管理复杂的深度学习模型变得简单。
此外,PyTorch还具有高度的灵活性和可扩展性,支持多种硬件平台,并且有一个活跃的社区,提供了大量的教程和资源,使得用户可以快速上手并解决实际问题。因此,PyTorch成为了深度学习领域非常受欢迎的选择之一。
登录PyTorch官网地址:
如图:
点击Get started,如图:
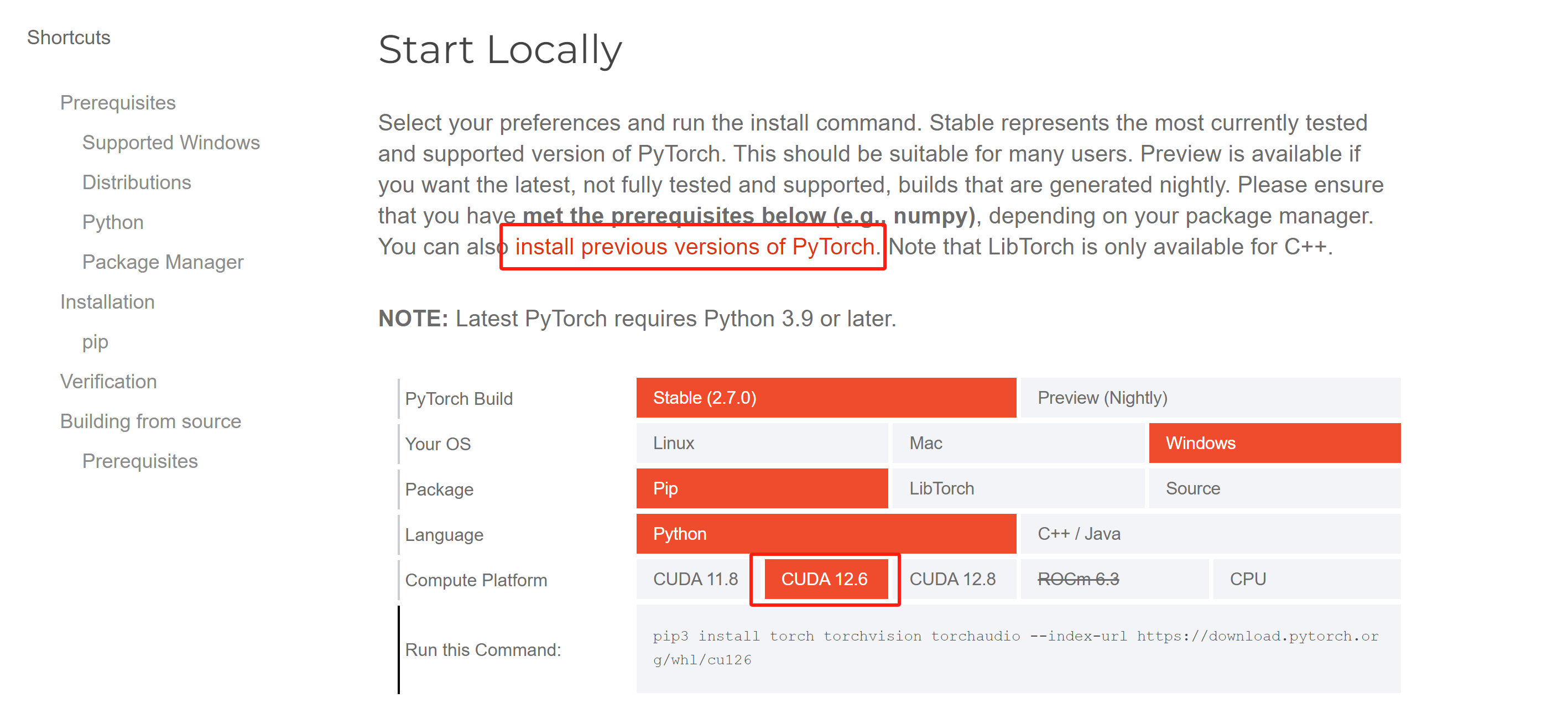
选择对应的CUDA版本,如果当前界面没有需要安装的版本,点击历史版本的链接安装,如图:
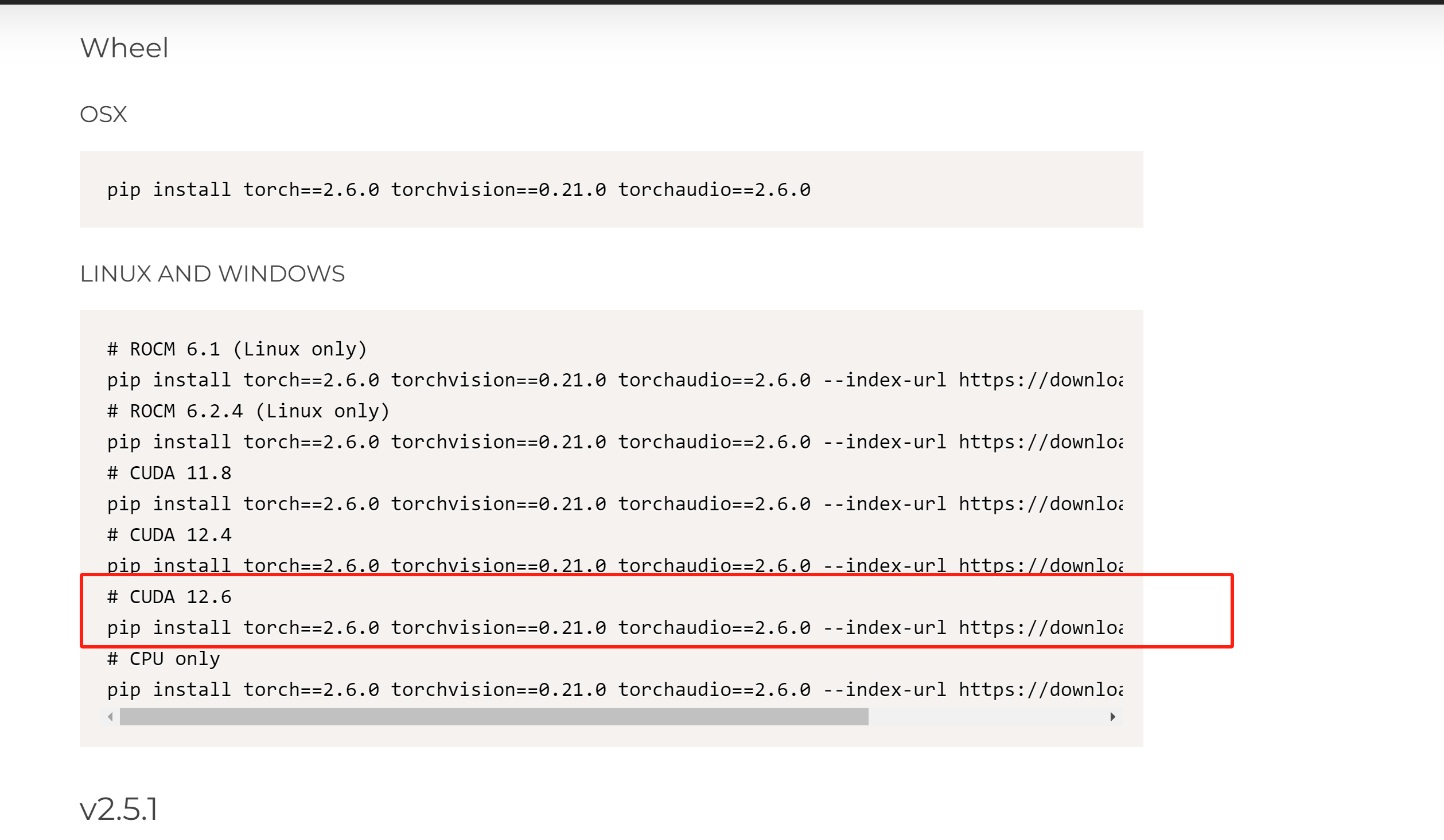
找到对应版本的命令,作者选择CUDA12.6对应的PyTorch版本,安装命令如下:
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
如果需要加速,可先执行如下命令设置清华镜像后,再执行上面的安装命令:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple执行后如下:

安装包比较大,需要等待一段时间。如果读者还是觉得慢,可登录阿里镜像下载PyTorch的轮子进行安装:
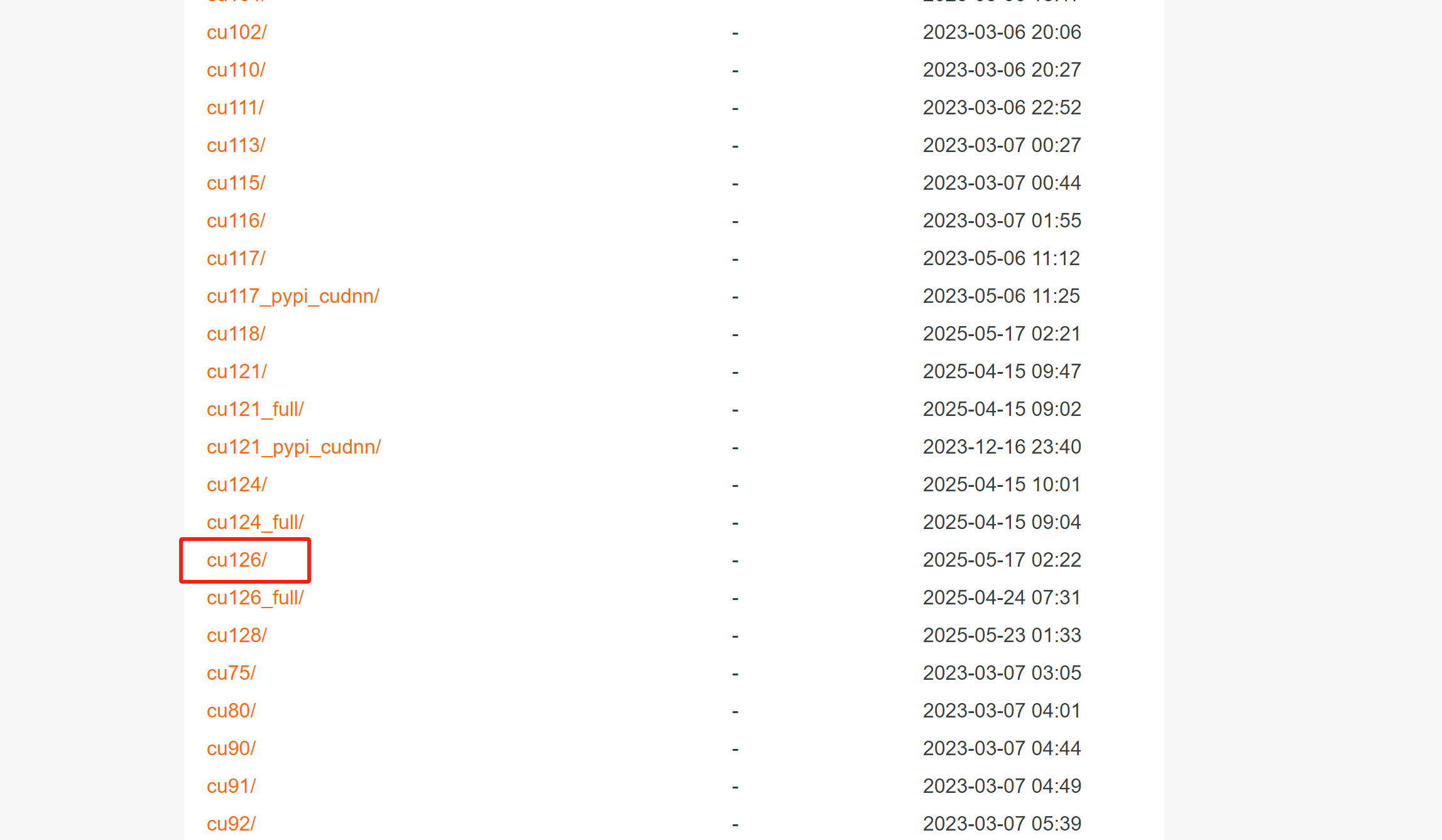
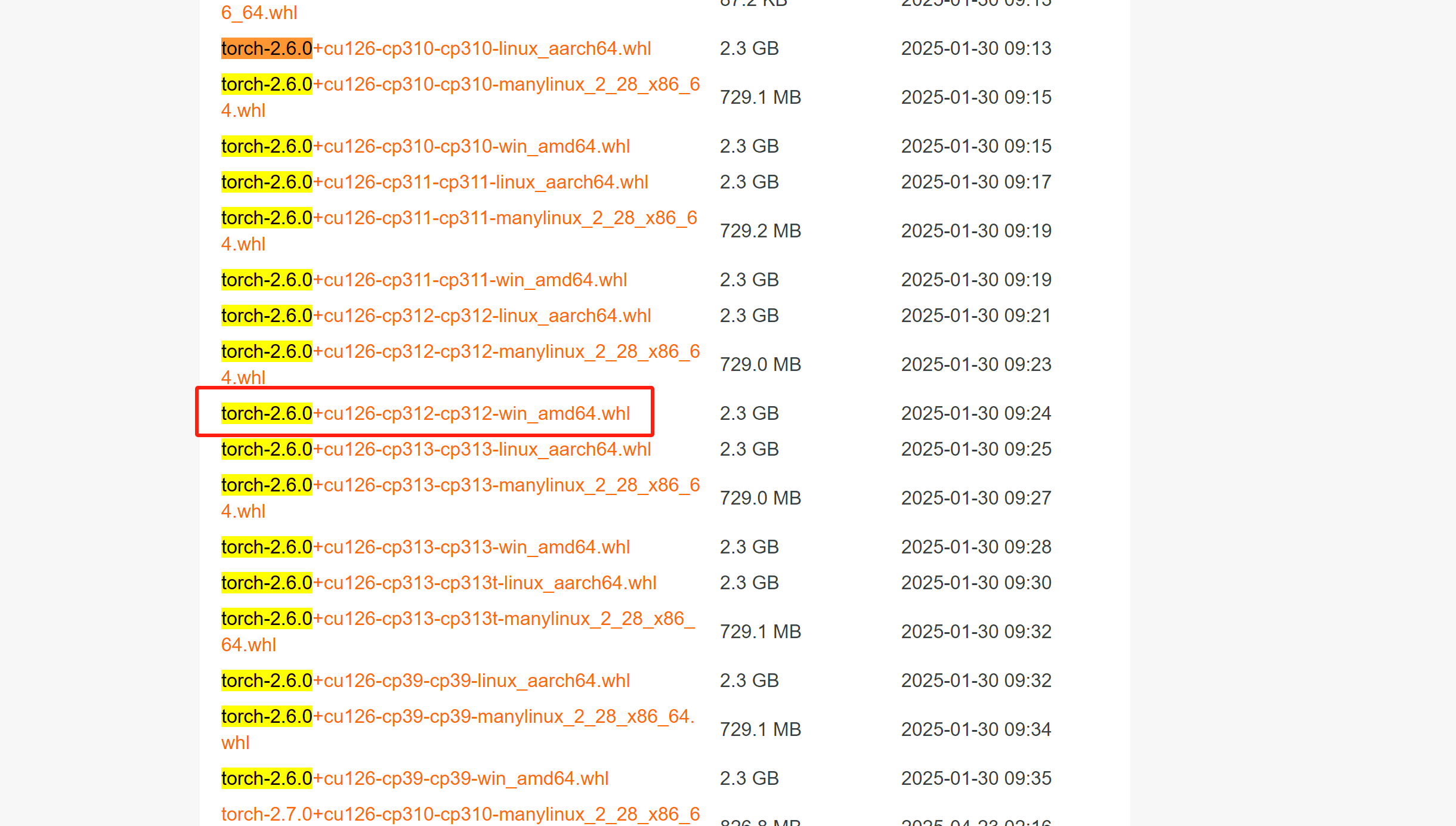
下载完成后,安装轮子的名称如下:
torch-2.6.0+cu126-cp312-cp312-win_amd64.whl
进入轮子所在目录,执行如下命令进行安装(注意也需要事先设置清华镜像后加速安装):
pip install "torch-2.6.0+cu126-cp312-cp312-win_amd64.whl"如图:
 建议使用清华镜像配合阿里轮子安装。
建议使用清华镜像配合阿里轮子安装。
测试
可以执行如下命令,查看torch版本以及使用的设备(GPU或者CPU):
import torch
# 查看torch版本.
print(torch.__version__)
# 检查使用设备.
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
print(f"Using {device} device")
# 查看cuda是否可用.
print(torch.cuda.is_available())
# 查看cuda版本.
print(torch.version.cuda)
# 查看GPU数量
print(torch.cuda.device_count())
# 查看设备名称.
print(torch.cuda.get_device_name(0))如果PyTorch安装成功了,输出结果如下:
2.6.0+cu126
Using cuda device
True
12.6
1
NVIDIA GeForce RTX 4060 Laptop GPU以下代码可以测试对比NumPy和PyTorch在CPU上的计算性能,以及PyTorch在CPU和GPU上的计算性能:
import torch
import numpy as np
import time
class Benchmark:
"""For measuring running time."""
def __init__(self, description='Done'):
self.description = description
def __enter__(self):
self.start_time = time.time()
return self
def __exit__(self, *args):
self.stop_time = time.time()
print(f'{self.description}: {self.stop_time - self.start_time:.4f} sec')
# GPU计算热身
size = 6000
with Benchmark('numpy'):
for _ in range(10):
a = np.random.normal(size=(size, size))
b = np.dot(a, a)
device = torch.device('cuda')
with Benchmark('torch-gpu'):
for _ in range(10):
a = torch.randn(size=(size, size), device=device)
b = torch.mm(a, a)
device = torch.device('cpu')
with Benchmark('torch-cpu'):
for _ in range(10):
a = torch.randn(size=(size, size), device=device)
b = torch.mm(a, a)运行结果:
numpy: 21.3148 sec
torch-gpu: 1.7530 sec
torch-cpu: 5.5417 sec


















 1855
1855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











