







- RNN
- LSTM
- Attention-based Model
十一、Recurrent Neural Network(RNN)(循环神经网络)
1、Slot Filling
智慧客服,订票系统,需要Slot Filling(槽位填充)这项技术,假设现在有人说“我要买11月2日去上海的票”,比如在订票系统的Slot分为Destination和time of arrival,系统需要自动辨别每一个词汇属于哪个Slot。
如何解决slot filling呢?
可以使用Feedforward network:input是一个词汇,变成一个vector,丢到这个network中去,output应该是一个Probability distribution(代表input中的词汇属于每一个slot的几率)。
那么怎么把词汇变成一个vector呢?
使用1-of-N encoding(方法很多,这是其中之一):

或者是Beyond 1-of-N encoding的方法:方法(1)需要在1-of-N encoding*中多加一个dimension,叫做“other”,不是词典里有的词汇就归类到“other”中去;方法(2)用某一个词汇的字母来表示它的vector,比如apple这个词汇,里面有“app”、“ppl”、“ple”,那么对应到这三种表达的dimension就是1,其它都为0:

假如现在,一个人说“arrive Shanghai on November 2nd”,可以确定,“arrive”、“on"都为"other”,“Shanghai"为destination,“November”、“2nd"为"time”;但是另一个说"leave Shanghai on November 2nd”,这个时候的"Shanghai"就为"place of departure"(出发地点),但是对network来说,input是一样的,output就是一样的,这个时候就希望我们的network是有记忆的,这个有记忆的network就叫做Recurrent Neural Network(RNN):
每一次hidden layer里面的neural产生output的时候,output就会被存到memory里面去;下一次,当有input时,hidden layer 的neural不仅会考虑输入的input,还会考虑存储在memory里的。

举例:假设现有network,所有的neural的weight都是1,并且没有bias,所有的激活函数都是linear,现在的input sequence(输入序列):
[
1
1
]
[
1
1
]
[
2
2
]
\begin{bmatrix} 1\\ 1 \end{bmatrix}\begin{bmatrix} 1\\ 1 \end{bmatrix}\begin{bmatrix} 2\\ 2 \end{bmatrix}
[11][11][22]…要把它们输入这个network,在这之前必须给memory一个起始值,假设这里在没存任何东西设置memory得初始值为0,然后输入第一个序列,得到得output为
[
4
4
]
\begin{bmatrix} 4\\ 4 \end{bmatrix}
[44]$ (1x1+1x1=4),并且把绿色的neural得到的output(2 2)存入memory:

现在输入第二个input序列,经过一个neural得到的output为6(1x1+1x1+2+2=6,这里的2和2也变成input),最后再经过红色的neural得到的output为12(6x1+6x1=12):

这里说明,即使给RNN一样的input,得到的output也是可能不一样的。
接下来继续输入input的第三个序列:

发现:RNN考虑input sequence的时候并不是independent的,如果改变input序列的顺序,output可能是会完全不一样的。
现在用RNN处理slot filling,举例:“arrive Shanghai on November 2nd”,然后把"arrive"变成vector丢到neural network中,neural network的hidden layer的output写成
a
1
a^1
a1,根据这个
a
1
a^1
a1得到
y
1
y^1
y1,这个
y
1
y^1
y1就是"arrive"属于每一个slot的几率;接下来
a
1
a^1
a1会被存到memory中去,input变为"Shanghai",此时的neural network的hidden layer会同时考虑memory和input,得到
a
2
a^2
a2,以此类推…(这里的neural network是同一个,在不同的时间点使用了三次):

有了memory之后,输入同一个词汇希望得到不同的output的问题可以被解决,现在同样输入"Shanghai",一个前面接的"leave",另一个前面接的"arrive",因为它们两个的vector不同,就会导致存储hidden layer的memory值不同,所以最后的output值不同。

以上的RNN只有一层hidden layer,但它当然也可以是deep的:

这种把hidden layer的值存起来,再读出来的network叫做Elman Network(埃尔曼网络);有另一种network存的是整个network的output的值,在下一个时间点再读进来,这个network叫做Jordan Network(因为output是有target的,所以有更好的performance)。
RNN也可以是双向的,句子中的每个词汇可以从句首读到句尾,但也可以反过来,从句尾读到句首,也就是说,可以同时train一个正向的RNN,又同时train一个逆向的RNN,把同一个词汇的hidden layer拿出来都接给一个output layer:

这样做的好处是,产生output时这个neural network看的范围比较广。
2、LSTM
现在比较常用的memory称之为Long Short-term Memory(LSTM):
有三个gate:(1)当neural network的其它部分想要被写到memory cell里面的时候,必须先通过一个闸门–Input gate,这个Input gate被打开的时候才能把值写到Memory Cell中,如果 Input gate关闭,其它neural 就不能把值写进去,这个Input gate是打开还是关闭,是neural network自己学的;(2)输出的地方也有一个Output Gate,它决定外界其它部分可不可以从Memory把值拿出来,同样,Output Gate什么时候打开或关闭,也是neural network自己学到的;(3)第三个gate叫做Forget Gate,它决定Memory Cell什么时候把存在里面的东西忘掉,同样也是neural network自学的。
整个LSTM可以看成有4个input,1个output,4个input为(1)想要被存到Memory Cell里面的值(不一定存的进去);(2)操控input gate的信号;(3)操控output gate的信号;(4)操控forget gate的信号。

如下图是一个Memory Cell,假设想存到Memory Cell里的input为
z
z
z,操控Input Gate的signal叫做
z
i
z_i
zi(scalar,数值),操控Forget Gate的signal叫做
z
f
z_f
zf,操控Output Gate的signal叫做
z
o
z_o
zo,最后得到的output叫做
a
a
a。假设现在Memory Cell在输入这些之前里面已经存了值C,那么得到的output(如下图):
(1)把
z
z
z通过Activation function得到
g
(
z
)
g(z)
g(z),把
z
i
z_i
zi通过另外的Activation function得到
f
(
z
i
)
f(z_i)
f(zi)(三个gate通过的Activation function通常会选择sigmoid function,它的值介于0~1之间,如果Activation function的output是1,说明这个gate是被打开的状态,如果是0,说明是关闭的状态)
(2)接下来把得到的
g
(
z
)
g(z)
g(z)和
f
(
z
i
)
f(z_i)
f(zi)相乘,得到
g
(
z
)
f
(
z
i
)
g(z)f(z_i)
g(z)f(zi);
(3)把
z
f
z_f
zf通过Activation function得到
f
(
z
f
)
f(z_f)
f(zf),然后把存在Memory里的值
c
c
c乘上
f
(
z
f
)
f(z_f)
f(zf),得到
c
f
(
z
f
)
cf(z_f)
cf(zf);把以上两项结果相加得到
c
′
c'
c′,
c
′
=
g
(
z
)
f
(
z
i
)
+
c
f
(
z
f
)
c' = g(z)f(z_i) +cf(z_f)
c′=g(z)f(zi)+cf(zf),
c
′
c'
c′就是新的存在Memory里的值;(从中可以看出Input Gate就是
z
z
z是否可以存入Memory的关卡,假设
f
(
z
i
)
f(z_i)
f(zi) = 0,
g
(
z
)
f
(
z
i
)
g(z)f(z_i)
g(z)f(zi) = 0,就等于没有输入;假设
f
(
z
i
)
f(z_i)
f(zi) = 1,
g
(
z
)
f
(
z
i
)
g(z)f(z_i)
g(z)f(zi) =
g
(
z
)
g(z)
g(z);假设
f
(
z
f
)
f(z_f)
f(zf) = 1,Forget Gate打开,等于还是记得之前存储的值,假设
f
(
z
f
)
f(z_f)
f(zf) = 0,Forget Gate关闭,Memory里的值就会变成0)。注意:Forget Gate打开就是记得,关闭就是忘记。
(4)把
c
′
c'
c′通过Activation function得到
h
(
c
′
)
h(c')
h(c′);
(5)把
z
o
z_o
zo通过Activation function得到
f
(
z
o
)
f(z_o)
f(zo),和
h
(
c
′
)
h(c')
h(c′)相乘得到
h
(
c
′
)
f
(
z
o
)
h(c')f(z_o)
h(c′)f(zo);如果
f
(
z
o
)
f(z_o)
f(zo) =1,等于
h
(
c
′
)
h(c')
h(c′)可以通过这个output gate被读取出来,如果
f
(
z
o
)
f(z_o)
f(zo) = 0,那么
h
(
c
′
)
h(c')
h(c′)就不能被输出。

LSTM举例:network里面只有一个LSTM的cell,input都是3维的vector,output都是1维的vector,这个3维的vector和output、memory里面的值的关系:假设第二维的值
x
2
x_2
x2是1的时候,
x
1
x_1
x1的值就会被写到memory里面去;假设
x
2
x_2
x2是-1时,memory的值就会被reset;假设
x
3
x_3
x3的值是1的时候,output会打开,才能够看到输出:

如上图,蓝色的框框为memory,初始的memory为0,
x
2
x_2
x2 = 0,不做操作;当
x
2
x_2
x2 = 1,memory取此时
x
1
x_1
x1的值3;当遇到下一个
x
2
x_2
x2 = 1,
x
1
x_1
x1的值被加到memory中去,memory的值就为3+4=7;当
x
2
=
−
1
x_2 = -1
x2=−1时,memory里的值被reset。
以下是一个Memory Cell的实际例子:

总共有4个input scalar,来源于input的3维的vector乘上一个linear的transform得到的结果,比如把第一维的三个值乘上三个值再加上bias就得到input;以此类推…其中,要乘上哪些值,bias的值应该是多少是通过training data用gradient descent得到的。
现在假设需要乘上的值和bias都已知,上图的g和h的activation function都是linear的,memory里的初始值为0,现在input第一个vector
[
3
1
0
]
\begin{bmatrix} 3\\ 1\\ 0 \end{bmatrix}
⎣⎡310⎦⎤(如下图),input =
x
1
x_1
x1 = 3,input gate=100x1-10(
x
2
=
1
x_2 = 1
x2=1),经过sigmoid function后约等于1,input gate打开,得到的值为1x3 = 3;forget gate=100x1+10,经过sigmoid function后约等于1,forget gate打开,然后把0x1+3 =3存到memory中;output gate=0x100-10 = -10(
x
3
=
0
x_3 = 0
x3=0),经过sigmoid function后约等于0,output gate仍旧关闭,所以output输出就为0;

接下来,input第二个vector
[
4
1
0
]
\begin{bmatrix}4\\ 1\\ 0 \end{bmatrix}
⎣⎡410⎦⎤(如下图),input = 4,input gate = 100-10,经过sigmoid function后约等于1,打开,两者相乘1x4 = 4;forget gate = 100+10,经过sigmoid function后约等于1,打开,此时memory里的值等于4+1x3 = 7,经过一个linear 的activation function得到7;output gate = -10,经过sigmoid function后约等于0,关闭,输出为0;

接下来,input第三个vector
[
2
0
0
]
\begin{bmatrix}2\\ 0\\ 0 \end{bmatrix}
⎣⎡200⎦⎤(如下图),input = 2,input gate = 0x100-10,经过sigmoid function后约等于0,关闭,两者相乘等于0;forget gate =0x100+10,经过sigmoid function后约等于1,打开,此时memory里的值为0+1x7 = 7,经过一个linear 的activation function得到7;output gate = -10,经过sigmoid function后约等于0,关闭,输出为0;

接下来,input第四个vector
[
1
0
1
]
\begin{bmatrix}1\\ 0\\ 1 \end{bmatrix}
⎣⎡101⎦⎤(如下图),input = 1,input gate = 0x100-10,经过sigmoid function后约等于0,关闭,两者相乘等于0;forget gate =0x100+10,经过sigmoid function后约等于1,打开,此时memory里的值为0+1x7 = 7,经过一个linear 的activation function得到7;output gate = 1x100-10,经过sigmoid function后约等于1,打开,输出为7:

接下来,input第五个vector
[
3
−
1
0
]
\begin{bmatrix}3\\ -1\\ 0 \end{bmatrix}
⎣⎡3−10⎦⎤(如下图),input = 3,input gate = -1x100-10,经过sigmoid function后约等于0,关闭,两者相乘等于0;forget gate =-1x100+10,经过sigmoid function后约等于0,关闭,此时memory里的值清空,为0,经过一个linear 的activation function得到0;output gate = -10,经过sigmoid function后约等于0,关闭,输出为0:

LSTM和之前看到的neural network有什么关系?
在之前的neural network里面会有很多的neuron,把input乘上不同的weight,当作是不同neuron的输入,每一个neuron都是一个function;现在把LSTM想成这些neuron。
原来的neural network:

LSTM:

LSTM和RNN有什么关系?
假设现在画一整排的LSTM的memory cell,每一个LSTM里面的cell都有一个scalar,把所有的scalar接起来变成一个vector,写作
c
t
−
1
c^{t-1}
ct−1,input一个vector
x
t
x^t
xt,经过一个linear的transform变成另外一个vector
z
z
z,
z
z
z的每一个dimension变成操控每一个LSTM的input,
z
z
z的维数等于LSTM的个数,
z
z
z的第一维丢给第一个LSTM,第二维丢给第二个LSTM,以此类推…
这个
x
t
x^t
xt再乘上另一个transform得到
z
i
z^i
zi,
z
i
z^i
zi的维数等于LSTM的个数,
z
i
z^i
zi的每一个dimension都会操控一个LSTM的input gate,同理,forget gate和output gate也是如此。

LSTM过程:

真正的LSTM会把hidden layer的输出接到下一个cell的input,也就是不仅仅考虑这个时间点的input,还会考虑上一个时间点的output;还会加入"peephole"(窥视孔),即把存在memory里的值
c
t
c^t
ct也加入到下一个cell的input中:

叠了很多层之后:

(Keras supports “LSTM”、“GRU”、“SimpleRNN” layers)
3、Learning target
RNN如何做learning?
(1)定义Loss Function
假设现在有一组training data,里面有一些sentences,例如:“arrive Shanghai on November 2nd”,并且会给sentence一些label,比如这个句子的label就是标注每个词汇属于那个slot:

把每个词汇丢到RNN,会得到相应的output
y
i
y^i
yi,然后
y
i
y^i
yi会和reference vector(这个reference vector的长度和slot的数目一致)计算cross entropy,比如现在丢进去的是“arrive”,slot应该对应到"other",那么它的reference vector的对应“other”的维的值为1,其它的维为0,其它词汇的情况同理:

注意:每个词汇应该按顺序丢进去!
所以cost就是每一个时间点的output和reference vector的cross entropy的和,也就是要去minimize的对象。
那么training也是用gradient descent,假如现在已经定出了Loss
Function L,现需要update某个参数
w
w
w,即:
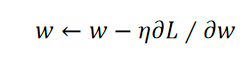
之前讲过feedforward neural network时,gradient descent用在其中的一个比较有效的演算法叫做Backpropagation(反向传播),为了在RNN中计算方便,开发了一套演算法叫做Backpropagation through time(BPTT)。
然而RNN的training是非常困难的,有时候还会出现如下图绿色线条的状况:

这个原因是RNN的error surface(误差面)有一些地方非常陡峭的,有一些地方是平坦的:

可以运用Clipping(裁剪)这个方式,当gradient大于某个threshold(门槛)时,就不要让他超过那个threshold。
解决RNN中gradient vanishing的问题的方法:LSTM。(确保Forget Gate大多数时间都是打开的,很少会关闭)
(现在有另外一个版本用gate操控memory cell的方法叫做Gated Recurrent Unit(GRU),只有两个gate)。
还有其他的解决RNN中gradient vanishing的问题的方法:
Clockwise RNN(顺时针RNN)、Structurally Constrained Recurrent Network(SCRN)(结构约束递归网络)等:

4、RNN Applications
RNN可以做到多对1:inpu是一个vector sequence(向量序列),output只是一个vector;
(1)这个可以用来做Sentiment Analysis(情绪分析):

如上图,分析哪些评论是正向的,哪些是负面的,learn一个RNN,input是一个character sequence,RNN把它读过一遍,在最后一个时间点把hidden layer拿出来,可能还会再通过几个transform,然后就可以得到最后的Sentiment Analysis。
(2)也可以用来做Key Term Extraction(关键词提取):RNN对一篇文章,指出它有哪些关键词汇。
收集一堆training data,即document,并且里面包含各自的label,即可直接train一个RNN,这个RNN把document当作input,然后通过embedding layer,使用RNN把这个document读过一次,然后把出现在最后一个时间点的output拿来做attention, 丢到network中,得到最后的output:

RNN可以做到多对多:input和output都是序列,但是output更短;
Speech Recognition(语音辨识):input是一段语音,每隔一小段时间的语音就用一个vector来表示,output是character sequence:

但是这种方式无法标识出叠词,解决方法:Connectionist Temporal Classification(CTC)(连接主义时间分类):output时多输出一个符号
Φ
\Phi
Φ,代表“null”,输出的时候就可以把
Φ
\Phi
Φ拿掉:

CTC:training
穷举所有可能的alignment,训练的时候当作全都是对的一起去train:

RNN可以多对多,没有限制:input和output都是sequences,并且长度不同–Sequence to sequence learning;
Machine Translation(machine learning):
假设现在input为machine learning,用RNN读取,然后在最后一个时间点的memory就存储了所有input sequence的information,接下来让machine出一个character,然后把它当作input,再把memory里存的值读进来,output下一个character,以此类推…:

但是这样它不知道什么时候才会停下来,所以得加一个新的symbol"==="(断),比如在”习“后面接这个symbol他就会停下来:

RNN也可以Beyond Sequence;
用于Syntactic parsing(句法分析):让machine看一个句子,可以得到这个句子得树状结构:

Sequence-to-sequence Auto-encoder-Text:
(1)一般把一个document表示成一个vector使用bag-of-word的方法,但是会忽略words的顺序:

使用Sequence-to-sequence Auto-encoder-Text把一个document变成一个vector(考虑words的顺序):
input一个sequence,使用RNN把它变成embedding的vector,然后把这个embedding的vector当作decode的输入,让它返回一模一样的句子:

这个Sequence-to-sequence Auto-encoder-Text的另一版本叫做skip thought,output target不再是同一个句子,而是下一个句子:

(2)Sequence-to-sequence Auto-encoder-Text还可以用于语音,它可以把一段audio segment(word-level)变成Fixed-length vector,这个可以用来做语音的搜寻:直接比对声音信号的相似度,machine就可以在database中把相关的部分找出来。
具体做法是把audio 的database做segmentation,切成一段段的,每一段用Audio segment to Vector的技术变成vector,然后输入一个query,也用Audio segment to Vector的技术变成vector,接着计算这两个vector的相似程度:

如何把一个audio segment变成vector:
先把audio segment抽成acoustic features,然后把它丢到RNN中,这个RNN的角色就是一个Encoder,它读过acoustic features之后,在最后一个时间点存在memory里的值就代表了整个input的声音信号的information,这个存在memory里的vector就是我们需要的。

但是只有这个RNN Encoder无法train,同时还要RNN Decoder,它的作用就是把encoder存在memory里的值拿来当input,然后产生acoustic features,希望这个
y
1
y_1
y1和
x
1
x_1
x1越接近越好(如下图),根据
y
1
y_1
y1产生
y
2
y_2
y2以此类推…这个训练的target就是希望
y
i
y_i
yi和
x
i
x_i
xi越接近越好:

训练时,这个RNN Encoder和RNN Decoder是一起train的。
Demo:聊天机器Chat-bot:使用Sequence-to-sequence learning来训练Chat-bot,收集很多对话,比如电影台词,某个人说“How are you”,另一个个人回答“I am fine”,当Sequence-to-sequence它的input是“How are you”,它的model的output就得是“I am fine”。

Attention-based Model
除了RNN之外,另一个会用到memory的东西。machine可以有很大的记忆的容量,即很大的database,database里面的每一个vector就代表某种information被存在machine的记忆里,当你输入一个input时,会被丢进一个中央处理器,这个中央处理器是一个DNN/RNN, 它会操控一个读写头–Reading Head Controller,这个读写头会决定这个Reading Head放的位置,machine再从这个Reading Head放的位置读取information,然后产生最后的output:

这个model还有一个2.0版本–Attention-based Model v2:
会在中央处理器DNN/RNN上增加一个Writing Head Controller,它会决定Writing Head放的位置,然后machine就会通过这个Writing Head把information写进database。

这个东西就被叫做Neural Turing Machine(神经图灵机)。
Applications:
(1)Attention-based Model常常被用在Reading Comprehension(阅读理解)上,就是让machine去读一个document,把document里面的每句话变成一个vector,现在提出一个问题query,它作为input被丢进中央处理器,这个中央处理器控制了一个Reading Head Controller,决定现在这个database里面哪些句子是跟中央处理器有关的,然后把这个句子读到中央处理器里面,读取的过程是可以重复数字的,也就是不会只从一个地方读取,从一个地方读取之后会换到另一个地方读取,然后把所有读到的information集合起来输出一个最终的答案。

(2)也会被应用在Visual Question Answering(视觉问答):
让machine看一张图,通过CNN可以把这张图每一小块region用一个vector表示,接下来输入一个Query,这个Query被丢到中央处理器里面,这个中央处理器取操控Reading Head Controller,Reading Head Controller决定了读取information的位置,读取后输入到中央处理器里面,最后输出answer:

(3)也会被应用在Speech Question Answering(语音问答):
语音的托福测验:让machine听一段声音,然后问它问题,然后从四个选项里面选出正确选项;

model architecture(模型架构):

如上图,让machine先读一下question,然后把这个question做语义分析,得到这个question semantics,声音的部分先用语音辨识把它转成文字,然后再用这些文字做语义分析,得到这段文字的语义,通过question semantics做attention,决定在这段文字里面哪些部分是和回答问题有关的,根据此产生答案,答案也可以回去修正产生出来的答案,最后machine得到它的答案,再把它的答案和其它选项计算相似度,选择相似度最高的那个选项:

Deep & Structured
deep learning 和structure learning之间的关系:

实际上,deep learning和structured learning是可以被结合起来的,比如,input feature先通过RNN/LSTM,然后得到的output再作为HMM/CRF/Structured Perceptron/SVM等的input,这样就可以同时享有两者的好处。
以下是实例:
-
Speech Recognition:CNN/LSTM/DNN +HMM
x x x是声音信号, y y y是语音辨识的结果:
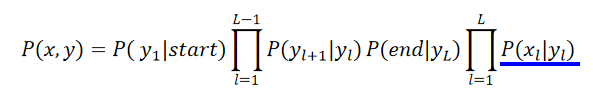
在RNN中都给出的output是 P ( y l ∣ x l ) P(y_l | x_l) P(yl∣xl),但是我们需要的是 P ( x l ∣ y l ) P(x_l | y_l) P(xl∣yl),就可以做一个转换:
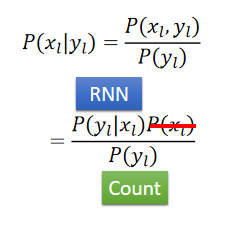
其中 P ( y l ∣ x l ) P(y_l | x_l) P(yl∣xl)从RNN中来, P ( y l ) P(y_l ) P(yl)可以直接统计, P ( x l ) P( x_l) P(xl)可以直接无视,跟 x x x有关的项不会影响inference的结果。

-
Semantic Tagging:Bi-directional LSTM + CRF/Structured SVM
先用Bi-directional LSTM 抽出feature,在把这些feature来定义CRF/Structured SVM:

-
Considering GAN


本文是对blibli上李宏毅机器学习2020的总结,如有侵权会立马删除。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









