







- Unsupervised Learning–Linear Methods
- K-means
- dimension reduction
- Principle component analysis(主成分分析)(PCA)
- Non-negative matrix factorization(NMF)
- Locally Linear Embedding(LLE)
- Laplacian Eigenmaps(拉普拉斯自映射)
- T-distributed Stochastic Neighbor Embedding
二十二、Unsupervised Learning–Linear Methods
Dimension Reduction(降维)分为两种:
Generation(无中生有);
Reduction(化繁为简):Clustering & Dimension
1、Clustering
有一大堆的image,把它们分成一类一类的,然后把每一类贴标签分为cluster 1 ,cluster 2 等等:
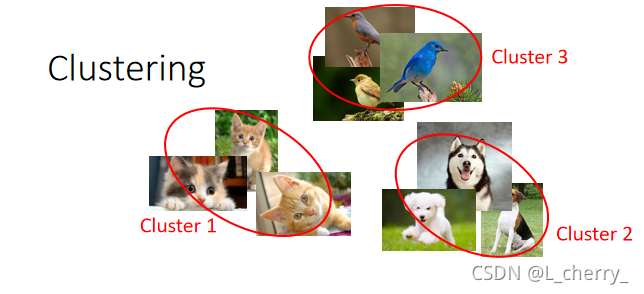
现在的问题是到底要多少cluster?
最常用的方法叫做K-means:
(1)有一大堆unlabelled data X = { x 1 , . . . , x n , . . . , x N } X =\begin{Bmatrix} x^1,...,x^n,...,x^N \end{Bmatrix} X={
x1,...,xn,...,xN},每个 x x x都代表一张image,要把它们做成K个cluster;
(2)首先找这些clutster的center,需要K个center,初始的center从training data中随机地找K个object,center c i , i = 1 , 2 , . . . , K c^i , i = 1,2,...,K ci,i=1,2,...,K,(K random x n x^n xn from X X X);
(3)repeat:
for all x n x^n xn in X X X:
b i n { 1 x n i s m o s t " c l o s e " t o c i 0 O t h e r w i s e b_i^n \left\{\begin{matrix} 1 \quad\quad x^n\quad is \quad most\quad "close"\quad to \quad c^i\\ 0 \quad\quad\quad \quad \quad \quad \quad \quad \quad \quad \quad Otherwise \end{matrix}\right. bin{
1xnismost"close"toci0Otherwise
即决定现在的每一个object属于哪一个cluster, b i n b_i^n bin代表第n个object属于第i个cluster
update你的cluster–update all c i c^i ci:
c i = ∑ x n b i n x n / ∑ x n b i n c^i = \sum_{x^n}^{}b_i^nx^n/ \sum_{x^n}^{}b_i^n ci=∑xnbinxn/∑xnbin
即把所有属于第i个cluster的object统统拿出来做平均,得到第i个cluster的center。
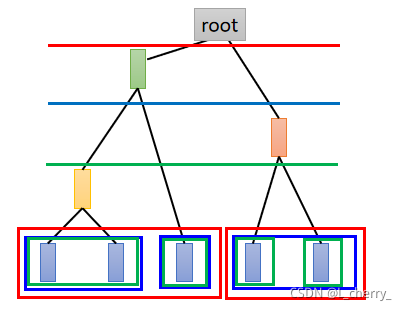
clustering还有另一个方法叫做Hierarchical Agglomerative Clustering(HAC)(层次聚合聚类方法):
(1)先建立一个tree,例如现在有5个example,想对它们建立tree structure,把这5个example两两去算它的相似度,然后挑最相似的一对;
(2)pick a threshold(门槛),决定在哪个位置切开:
但是只做cluster是比较卡的,因为每个cluster都比较以偏概全,所以应该用一个vector来表示object,这个vector中的每一个dimension就代表了某一种特质,这件事情就叫做distributed representation。
如果原来的object是一个非常high dimension的东西,比如image,那么现在把它用它的特质来描述,它就会从比较高维的空间,变成比较低维的空间,这件事情就叫做Dimension Reduction(降维)。
2、Dimension Reduction
举例:考虑MNIST,在MNIST中一个digit是一个28x28 dimension的图片来描述,实际上多数28x28的dimension的vector看起来都不像数字。
那么怎么做Dimension Reduction?
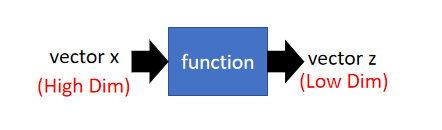
找一个function,这个function的input是一个vector x x x,它的output是另外一个vector z z z,并且 z z z的dimension比input x x x小。
最简单的方法就是 Feature selection(特征选择):
在二维的平面上,发现data都集中在 x 2 x_2 x2这个dimension, x 1 x_1 x1这个dimension没什么用就把它拿掉,选择 x 2 x_2 x2
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1070
1070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









