







- Embeddings from Language Model(ELMO)
- Bidirectional Encoder Representations from Transformers(BERT)
- Generative Pre-Training(GPT)
二十五、ELMO,BERT,GPT
怎么让机器去读人类的文字。
在BERT之前的方法:

同一个词汇是可能有不同的意思的,举例:

过去在做embedding时每一个word type有一个embedding,不同的token属于同一个type,它所对应的vector就是一模一样的。事实上并不是如此,不同的token就算它们是同样的type,也有可能有不同的语义,我们希望给不同意思的token,即使是同样的type,也要给不同的embedding。过去的做法就是给它们不同的type不同的embedding。这样做是不够的。
现在期待机器可以更进一步做到每一个word token都有一个embedding(即使它有同样的word type),这个word tokens的embedding取决于它的上下文context,上下文越相近的token,它们就有越相近的embedding。这个技术叫做Contextualized Word Embedding(语境化词语嵌入)。
(一)Embeddings from Language Model(ELMO)
怎么给每个word token不同的embedding?
这个技术叫做Embeddings from Language Model(ELMO):
是一个RNN-based language model(trained from lots of sentences),举例现在有一个句子“潮水 退了 就 知道 谁 没穿 裤子”,教你的RNN-based language model如果看到一个begin of sentence的符号,就要输出“潮水”,接下来再给你“潮水”这个符号,你就要输出“退了”,给你“潮水”和“退了”的符号就要输出“就”…即给它很多句子让它去学怎么预测下一个token。
学完以后就有word embedding,我们可以把RNN的hidden layer拿出来说它就是现在输入的那个词汇的word embedding。假设你把“退了”这个词汇输进去,RNN会吐一个embedding出来给你,这个embedding就是“退了”这个词汇的embedding。
同样的词汇,如果上下文不同的话,RNN 出来的embedding就会不一样。
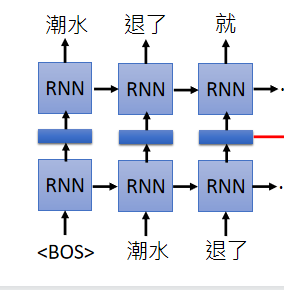
这样好像只考虑到每个词汇的前文,没有考虑到后文,解决方法:再train一个反向的RNN,从句子的尾巴读过来。今天如果要得到“退了”这个词汇的word embedding,就把“退了”这个词汇在正向的RNN的 embedding跟逆向的RNN的embedding接起来:

这个RNN可以是deep的,train的时候会遇到问题,因为它有很多层,每一层都有embedding,那到底应该要用哪一层呢?

ELMO的做法是:现在每一层都会给我们word embedding,每一层的每个词汇都会有embedding,每个词汇都不止一个embedding,方法就是把这些embedding加起来一起用。但是怎么加起来?
ELMO会做weighted sum,它会把第一层吐出来的embedding乘上
α
1
\alpha_1
α1,第二层吐出来的embedding乘上
α
2
\alpha_2
α2,然后统统加起来得到一个embedding,再把这个embedding做接下来的tasks,并且
α
1
\alpha_1
α1和
α
2
\alpha_2
α2是learn出来的。
如何learn
α
1
\alpha_1
α1和
α
2
\alpha_2
α2是根据接下来的tasks决定的。

(二)Bidirectional Encoder Representations from Transformers(BERT)
BERT = Encoder of Transformer
Learned from a large amount of text without annotation(从大量没有注释的文本中学习),只要搜集一大堆句子就可以训练一个BERT。BERT做的事情就是给一个句子,每一个句子都会吐一个embedding出来,就结束了。BERT的架构就和transformer中的encoder一样,里面有self-attention layer等。

(此文中的例子是用中文的词当作单位,实际上在BERT中用字当作单位是更为恰当的,因为中文的词汇数目太大)
怎么训练BERT?
假设没有label data,只有搜集的一大堆没有任何annotation的句子。两个训练方法:
(1)Masked LM:我们把输入的句子随机用15%的词汇置换成一个特殊的token [MASK],BERT要做的事情就是猜测这些盖住的地方应该是哪个词汇。方法:假设在输入的词汇中第二个词汇是挖空的,加下来把这些东西都通过BERT,每个input token都会得到一个embedding,加下来把挖空的地方的embedding丢到一个Linear Multi-class Classifier里面,要求这个classifier预测现在被masked这个词汇是哪一个。如果两个词汇填在同一个地方没有违和感,它们就有类似的embedding。

(2)Next Sentence Prediction:给它两个句子,然后预测这两个句子是接在一起的,还是不是。
举例来说给BERT两个句子,一个是“醒醒吧”,一个是“你没有妹妹”,你希望这两个句子是可以接在一起的,那就希望BERT能够准确预测这两个句子应该要被接在一起。这里需要引入一个特别的符号 [SEP],这个符号代表两个句子之间的boundary。
怎么预测两个句子是不是相接的?还要再给它输入一个特殊的符号 [CLS],通常放在句子的开头,代表说在这个位置要做classification。从这个[CLS]输入的位置输出来的embedding丢到一个Linear Binary Classifier,让这个classifier去output现在这两个句子是否应该被接在一起。

在训练时你会知道哪些句子是相接的,就可以去训练这个BERT。这个Classifier和整个BERT架构是一起训练的,以上两个训练方法是同时使用的。
怎样使用BERT?
把BERT当作抽feature的工具,就像ELMO一样,输出新的embedding给你,你可以拿这个新的embedding做你想做的事。
把BERT的model和要解的任务一起做训练,有以下四个例子:
(1)input一个sentence,output一个class,比如Sentiment analysis;比如Document Classification;
把现在要做分类的句子丢给BERT,在开头的地方加一个代表分类的符号 [CLS],接下来你把代表分类的符号这个位置的output的embedding丢给一个Linear Classifier,这个Linear Classifier去预测input的sentence的class 是什么。实际上在train的时候Linear Classifier的参数是随机初始化的,是从头开始训练的;BERT的参数和Linear Classifier的参数是一起学的,BERT只要Fine-tune(微调)就好。

(2)input一个句子,这个input句子里面的每一个词汇我们都要决定它属于哪个class。
在讲RNN时举例过Slot Filling的例子,input一个句子,你的machine要决定说input句子里面的每一个词汇是属于哪一个slot(class)。
现在input一个句子,每一个句子现在都会output一个embedding,把每一个embedding都丢到Linear Classifier里面,这个Linear Classifier就决定说这个embedding应该属于哪一个class。

(3)input两个句子,output一个class,比如Natural Language Inference,给机器一个前提,再给它一个假设,然后根据这个前提判断这个假设到底是对,还是错,还是不知道。
给你的model两个句子,那你的model的output就是现在这两个句子根据这个前提这个假设是对的还是错的,还是无法判断。(只有三个类别的分类问题)
把一个句子丢给BERT,然后再给它一个句子之间的分隔符号 [SEP],再把第二个句子丢给BERT,然后接下来在开头的地方放一个代表分类的符号[CLS],在开头的地方所输出的embedding丢给Linear Classifier,让它决定它属于哪个class(T/F/Unknown)。

(4)拿BERT解Extraction-baesd Question Answering(QA)(自动问答):给你的model读一篇文章,然后问它一个问题,希望它可以正确得到答案,并且这个答案一定会出现在文章里面。
文章和问题都是用一个token sequence来表示,有一个QA Model,这个model吃一篇文章,吃一个问题,output两个整数。这两个整数的意思是你的答案落在文章里面第s个token到第e个token。

怎么用BERT解:就把问题输进去然后给一个分隔符号[SEP],然后把文章输进去,现在文章里面的每个词汇都会有一个embedding,接下来你让machine去learn另外两个vector,一个红色的,一个蓝色的,这两个vector的dimension跟这些黄色的dimension是一样的,红色的vector跟文章里面每一个黄色的vector做dot product(点积),把得到的scalar通过softmax,每一个词汇都会得到一个分数,接下来看哪一个词汇得到的分数最高,比如下图第二个词汇的分数最高,那么s=2,即红色的vector决定s等于多少;

那么蓝色的vector决定e等于多少。把蓝色的vector去跟每一个文章里面的黄色vector做dot product(点积),把得到的scalar通过softmax,每一个词汇都会得到一个分数,接下来看哪一个词汇得到的分数最高,比如下图第三个词汇的分数最高,那么e=3。

假设s和e矛盾了怎么办?这个时候model就output此题无解。
以上的红色vector和蓝色的vector是学出来的,在训练时给机器很多资料,训练时这两个vector从头开始学,BERT微调就好。
Enhanced Representation through Knowledge Integration(ERNIE)(通过知识集成增强表示):特别为了中文而设计的。BERT的Masked ML方法每次盖掉一个字,但是这些字很容易被猜出来,所以应该盖掉词才对,因此产生了ERNIE方法。
BERT每一层学了什么:

Multilingual BERT:使用104种语言进行训练

(三)Generative Pre-Training(GPT)(生成性预训练)
一个很大的language model:

GPT实际就是Transformer的Decoder。给它一些词汇它要预测接下来应该要放哪个词汇。举例来说,你给它beginning sentence token [BOS] ,再给它输入“潮水”这个词汇,希望它可以output “退了”这个词汇。把“潮水”input进去一样产生query、key和value,把“潮水”的q拿出来做self-attention,要跟之前输入过的词汇的key跟自己算一个attention,然后把算出来的attention跟
v
1
v^1
v1和
v
2
v^2
v2做weighted sum得到
b
2
b^2
b2,通过很多层之后预测出“退了”这个词汇:

接下来把“退了”这个词汇一样输出q、k、v,把“退了”的q跟已经产生出来的词汇包括自己去做self-attention,再跟每一个已经产生出词汇的v做weighted sum,得到一个embedding,然后通过很多层得到“就”这个词汇:

GPT做了很多神奇的事情,举例来说它可以在完全没有训练资料的情况下自动做到Reading Comprehension、Summarization、Translation。它可以做到zero-shot learning(零样本学习)。

GPT-2的attention做的事情是什么?举例来说,如下图右边,在GPT-2里面左边的是下一层的结果右边是前一层要attention的对象,如下图,在“She”这个位置它会attend到“nurse”;在“He”这个位置会attend到“The doctor”。如下图左边,是对不同层的不同的head做一下分析,会发现一个神奇的现象–很多词汇都要attend到第一个词汇。

GPT-2的强大力量是可以自己写作,它可以predict下一个词汇,你给它几个词汇之后它可以帮你完成整篇文章。

本文是对blibli上李宏毅机器学习2020的总结,如有侵权会立马删除。














 1106
1106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









