









这两天看到了sparkstreaming连接上kafka作为数据源在idea中进行测试,一路颠沛流离,特此记录。
首先虚拟机上要有zookeeper和kafka(我这里只用了一台虚拟机进行测试)。
安装完zookeeper和kafka之后,再对IDEA进行配置。
我用的spark,Scala,streaming以及streaming-kafka都是2.11版本的。
关键配置文件如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-yarn_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.3.0</version>
</dependency>
测试代码块如下:
package Streaming
import java.util.Random
import org.apache.kafka.clients.consumer.{ConsumerConfig, ConsumerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.{InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.receiver.Receiver
import org.apache.spark.streaming.{Seconds, StreamingContext}
object Spark_Streaming_04_kafka {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("kafka").setMaster("local[*]")
val ssc: StreamingContext = new StreamingContext(conf, Seconds(3))
val kafkaPara: Map[String, Object] = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "master:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "dgp",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer"
)
val kafkaDataDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(
ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Set("lxh"), kafkaPara)
)
kafkaDataDS.map(_.value()).print()
ssc.start()
ssc.awaitTermination()
}
}
其中dpg与lxh都在虚拟机中创建完成。

当然也可以凭着个人的喜好自行创建一个

这里特别注意本地的C:\Windows\System32\drivers\etc下的hosts配置文件一定要提前配置完成,不然会报这个错。
No resolvable bootstrap urls given in bootstrap servers
如果报错为:消费者创建不成功,错误为版本的问题,将所有版本修改一致,以及
这个地方的版本也修改一致即可。
完成这些即可运行程序。
程序中有.print(),即在打印时间戳
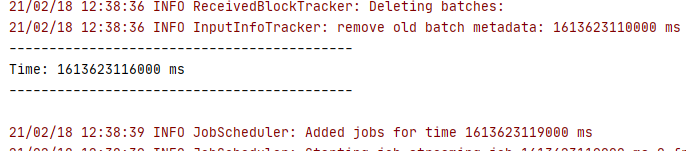
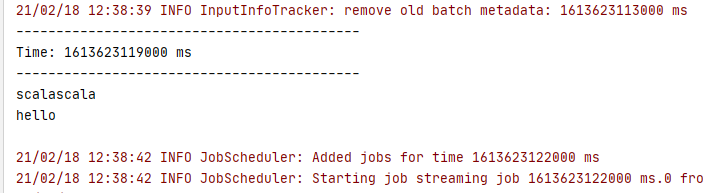
往kafka中输入一些数据

运行出结果。
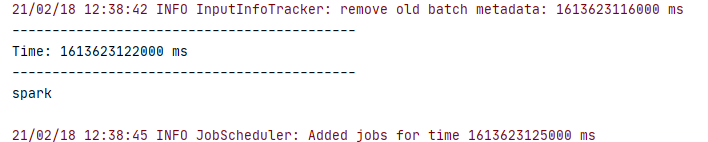
感谢阅读,我是啊帅和和,一位大数据专业大三学生,祝你快乐。
















 2136
2136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











