







前言
大多测试场景中,我们执行登录之后,将始终使用登录的这个用户的身份信息,反复的执行某业务来进行压测。也就是说,登录这个动作,只执行一次。所以,将登录账号信息放在文本文件中,使用CSV Data Set Config读取,是常用的一种参数化手段。
但是在我之前分享的案例JMeter案例分享:修改密码-如何在测试中使某变量循环交替使用两个值?中,修改密码后系统会自动将该用户登出,想要再一次修改密码,就需要重新登录。
于是,就需要登录->修改密码->登录->修改密码这样的循环,直接使用CSV Data Set Config就不行了。
到底有什么问题呢?
乍一看,没什么问题啊,把他们放到一个线程组里:

恭喜你,跟我一样,掉坑里了。来,单线程执行2次,看看哪儿错了:
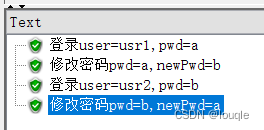
- 第一轮:usr1用pwd=a登录,然后修改密码为b;
- 第二轮:usr2用pwd=b登录,然后修改密码为a;(这里我用的Dummy Sampler,实际测试中,第二轮登录失败,因为usr2的密码根本没变,还是初始密码a呀)
然而,我想象中的场景应该是:
- 第一轮:usr1用pwd=a登录,然后修改密码为b;
- 第二轮:usr1用pwd=b登录,然后修改密码为a;
也就是:始终是usr1在操作。
所以,问题在于:使用CSV Data Set Config管理登录账户信息,每一次读取,它都将向下读一行。但是,在这个案例中,我希望线程1永远读取usr1,线程2永远操作usr2。。。它们永不相交。
解决方案:beanShell/JSR223 preProcessor
读过我这篇JMeter案例优化:不使用BeanShell,如何控制内置函数生成uuid在一次迭代中仅生成一次文章的人,想必还记得,我解决问题的方式曾经相当单一。用beanShell或者JSR223 前置处理器来读取数据文件获取账户信息:
1、禁用csv data set config,添加JSR223 preProcessor
为了执行时更容易看出来是哪个线程操作哪个用户,在Sampler名称中分别添加了${__threadNum}和${user}

2、JSR223 preProcessor中输入以下代码
import org.apache.jmeter.services.FileServer;
String jmxFileDir = FileServer.getFileServer().getBaseDir();
FileReader fileReader = new FileReader(new File(jmxFileDir,"csvDataFile.txt"));
BufferedReader br = new BufferedReader(fileReader);
String temp = null;
int count = 0;
String account;
//第几个线程,取第几行数据,固定不变
while((temp = br.readLine()) != null){
count ++;
if(count == ${__threadNum}){
account = temp;
break;
}
}
vars.put("user",account);
temp=null;
account=null;
br.close();
fileReader.close();3、2个线程,循环两次
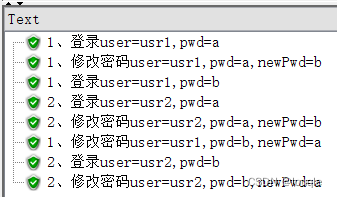
线程1:
- 第一轮:usr1用pwd=a登录,然后修改密码为b;
- 第二轮:usr1用新密码pwd=b登录,然后修改密码为初始值a;
线程2:
- 第一轮:usr2用pwd=a登录,然后修改密码为b;
- 第二轮:usr2用新密码pwd=b登录,然后修改密码为初始值a;
后记
以前用的时候不觉得,现在再来看,这样实在不太好:每个线程都要打开一次数据文件,然后从第一行开始向下读取,读到跟当前线程号对应的行数时,便是自己要的数据了,取数,结束循环,关闭文件。大并发时,很可能导致资源紧张(比如文件太大,那么多全都读取到内存中,会不会导致OOM;Linux上执行的时候,会不会导致too many open files?)
不过,我还没有想到太好的替代方案,希望有想法的同学不吝赐教。
注:这里没有处理异常情况:就是数据文件中的数据量,或者说行数,一定要大于并发数,否则,大概会死掉吧(写测试脚本的后遗症,不处理异常,因为在我的概念里,测试中的任何异常都是要停下来分析一下的)















 4923
4923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









