









最近开始读<< Hadoop:the definitive guide>>,于是打算写点读书笔记,书电子版见网盘,密码v66s。
原书推荐的读书顺序如下图:
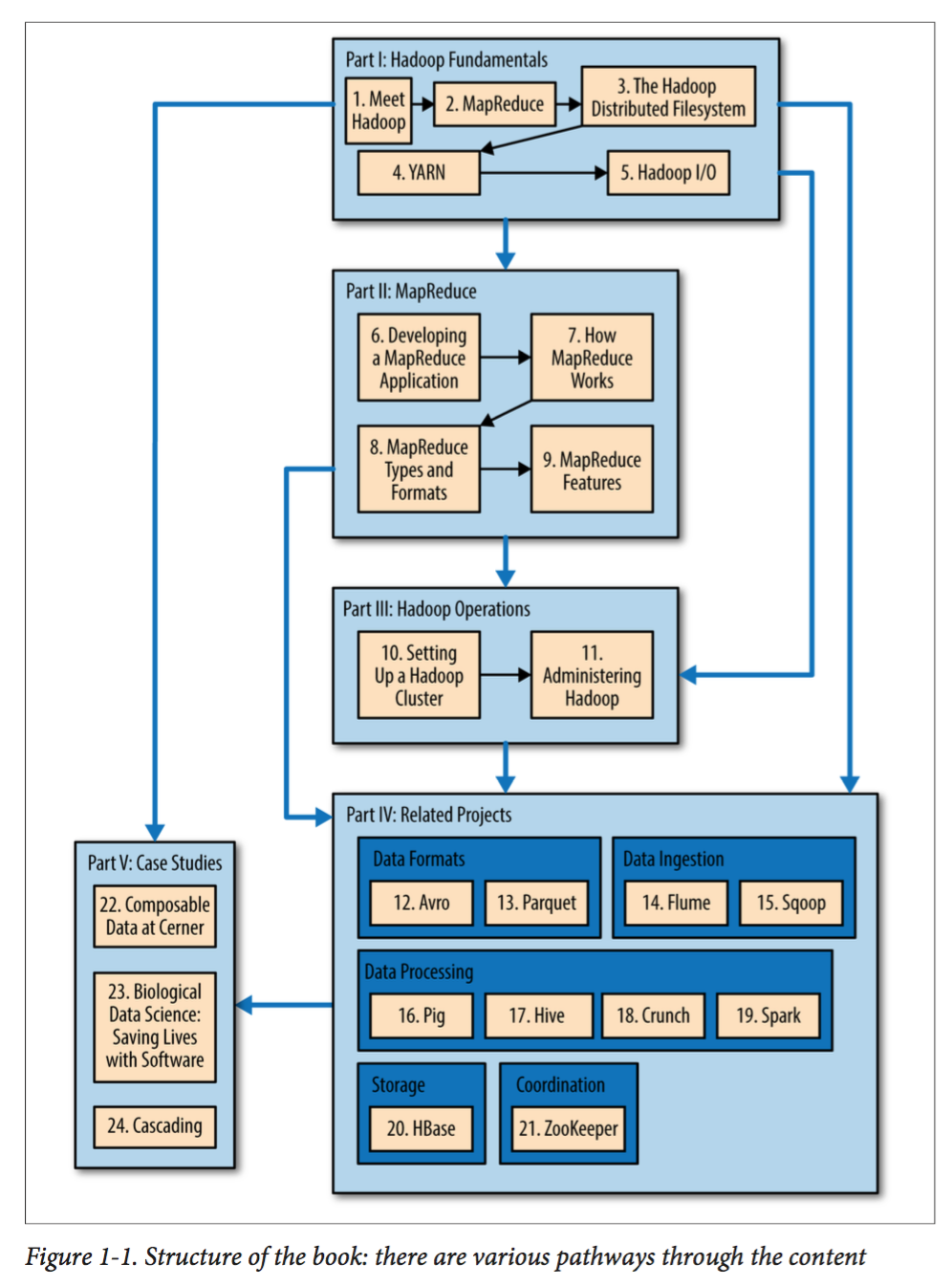
这里我们就按从第一章到最后一章的顺序读吧.
Chapter 2: MapReduce
mapreduce思想
MR的思想非常简单,如下图所示:
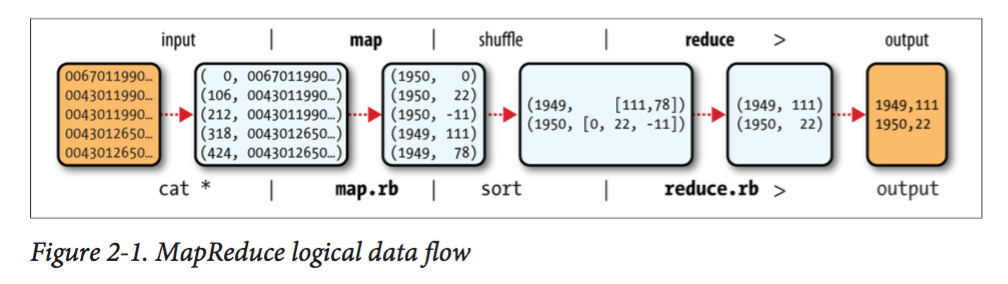
- Map将按照行读入输入文件,然后将它们parse为若干个< Key,Value>对
- 将map生成的KV对打乱并按照Key 排序
- Reduce将所有key相同的KV对聚集在一起,组成一个< K, List< Value>>对列,并获得List< Value>的Iterator,然后再进一步处理,最后输出新的KV对到文件中。
mapreduce程序的实现
MapReduce一般用Java实现,故我们需要注意以下的地方:
- Map输出的KV对的数据类型必须和reduce接受的输入类型一致。
- 输入可以用addInputPath定义,参数可以是一个文件,一个目录,或者一个文件匹配模式。
- 输出用setOutputPath定义,参数必须是一个不存在的目录。
- 我们需要用setOutputKey和setOutputValue来设定reduce的输出类型。如果map的输出类型和reduce输出类型一样,则不需要再设置,否则用setMapOutputKey等
- 最后waitForCompletion()返回job是否执行成功,并且接受一个boolean参数,如果为真则打印进程执行信息,否则不打印。
mapreduce的数据流
我们需要注意的以下几点:
- Hadoop将输入分割成若干个大小固定的块,称之为splits,每一个splits对应一个map task.
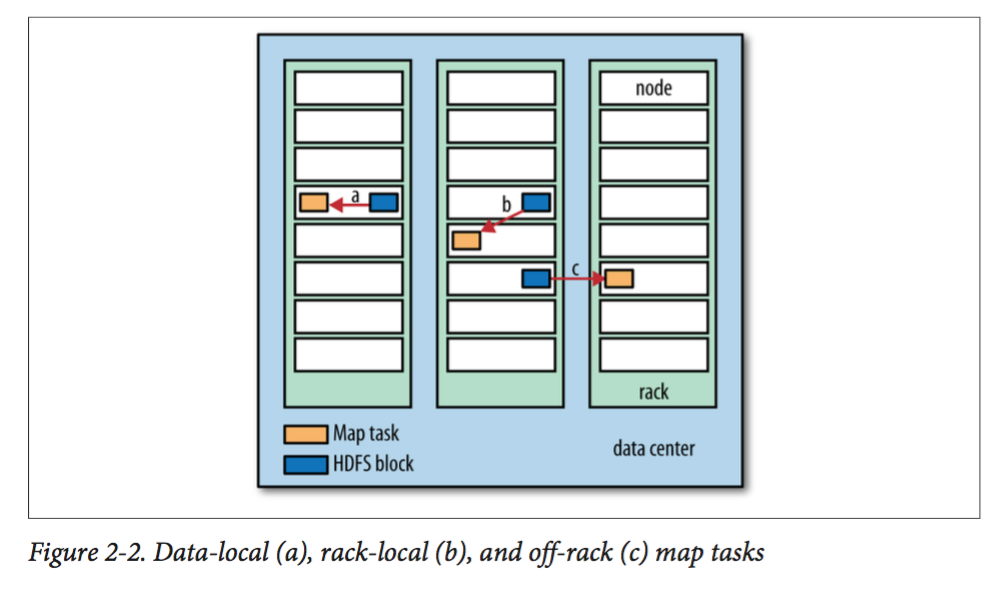
- 在创建map task时,hadoop会遵循data locality optimization。即优先考虑存储对应splits的机器,如果不行则考虑同一个机架上的机器,这两个都不满足,才会去考虑其他机架上的机器。如下图:
map task将它的输出写在本地磁盘,而不是HDFS,因为这些数据都是暂时的,只需要作为输入提供给reduce,并不是最终结果。
此外还需要说明一点,在一些情况下,我们可以实现一个combiner函数,这个函数工作在每一个map之后,将map函数的输出先聚合好,再将其输出到reduce中。这样可以将map输出的中间结果规模减小,减少和reduce通信的规模。
Chapter 3: The Hadoop Distributed Filesystem
HDFS的设计和基本概念
HDFS被设计用于下面三个目的:
- 大文件(very large files):几百M,G,T甚至更多。
- 流式数据访问(Streaming data access):由于大部分数据访问场景都是写入一次,读取多次,故读取整个数据的时间比读区第一条记录的延迟要重要得多。
- 廉价硬件(Commodity hardware):Hadoop集群往往运行在大量的廉价硬件上(例如机械硬盘),因此节点出错的几率非常高。HDFS要求在用户不察觉到出错的情况下完成工作。
综上所述,HDFS不适用于下面的情况:
- 低延迟访问(low-latency data access): Hbase更适合低延迟访问。
- 大量小文件(lots of small files): namenode把文件的元数据都存储在内存(每条文件,目录和块都占大约150bytes),大量的小文件会给namenode的内存带来巨大压力。
- 多个写入者和文件修改(Multiple writes and arbitrary file modifications): HDFS只支持append的修改操作。
块(Block)
磁盘有一个Block的概念,它是磁盘读/写数据的最小单位,一般为512bytes。HDFS也有Block的概念,但它的块是一个很大的单元,默认是64MB。像硬盘中的文件系统一样,在HDFS中的文件将会按块大小进行分解,并作为独立的单元进行存储。但和硬盘中的文件系统不一样的是,存储在块中的一个比块小的文件并不会占据一个块大小盘物理空间(HDFS中一个块只存储一个文件的内容)。
HDFS中块之所以这么大主要有两个原因:
- 较大的块可以在读取相同大小数据的前提下,寻道时间更小。是的数据传输总时间更少。
- 但块的大小也不宜过大,因为mapreduce的map一般每次处理一个块。太大的块会导致块数目变少,从而map个数变少,降低mapreduce性能。
HDFS中块的好处:
- 文件可以任意大:文件被拆分成块存储起来,而所有的块不需要在同一个节点上。
- 简化了系统的设计:快大小的固定使得每块硬盘可以存储多少个块变得非常容易计算。
- 更利于数据备份:每个块都可以单独做备份。
名字节点(namenode)和数据节点(datanode)
HDFS中的节点是master-slave的工作模式,因此分为两种: 一个namenode 和多个 datanode。
Namenode负责管理文件系统命名空间,例如维护文件系统的树结构,还有树中所有文件和目录的元数据。这些信息分为两个部分: fsimage和edit log,前者是一个对hdfs文件系统的快照而后者是文件系统的改动序列。此外它知道一个文件的全部块在哪些datanode上。
Datanode则负责存储和读取这些blocks。此外他们还要定期向namenode报告存储的blocks的情况。
由于没有namenode, hdfs就不知道文件的组织结构,因此hadoop1.0中对namenode提供了两个容错机制:
- 一个是namenode将自己的状态备份到多个文件系统中。这些备份过程是原子且异步的,而且一般被备份到本地磁盘。
- 还有一个是运行一个secondary namenode(之前那个namenode被称为primary namenode)。这个s-node并不能单纯看作p-node的备份节点。事实上s-node会定期访问p-node的fsimage和edit log并将其合并成新的fsimage,从而保证edit log不会太大。
但是这种primary-secondary的备份方式仍然不够好,实际上显然namenode仍然是单点失败的(single point of failure) ,因此如果它失败时从secondary恢复可能需要很久(如半个小时)。在hadoop2.0中提供了新的解决办法,即提供了对HA(high availability)的支持:active-standby namenodes。这种新的容错机制有和上面的相比如下特点:
- edit logs被存储在一个共享空间里面,这样active和standby的namenodes都可以访问它们。从而在两者的内存中都有最新的数据。
- datanodes必须定期向两个namenodes发送blocks报告。
- 原来secondary namenode的角色被standby namenode替换。
这里的共享空间除了用NFS储存,hadoop本身还提供了QJM(quorum journal manager),这也是它推荐的方法。QJM使用了paxos协议,因此只要保证过半的存储节点没有失败,就不会导致edit logs丢失。利用了上面新的设计后,standby namenode可以在很多时间内(例如几十秒)接管active namenode的工作,原因是edit logs仍然在内存中,并且standby namenode中有最新的block mapping。
最后,如果standby namenode失败了,则直接从hadoop 集群中冷启动即可。这不会比non-HA的效果更差。
命令行和API
这部分略过,因为网上有很多相关博客,只说一点:
副本的概念对目录是无效的,因为它们的信息都用元数据存储在namenode中。
数据流
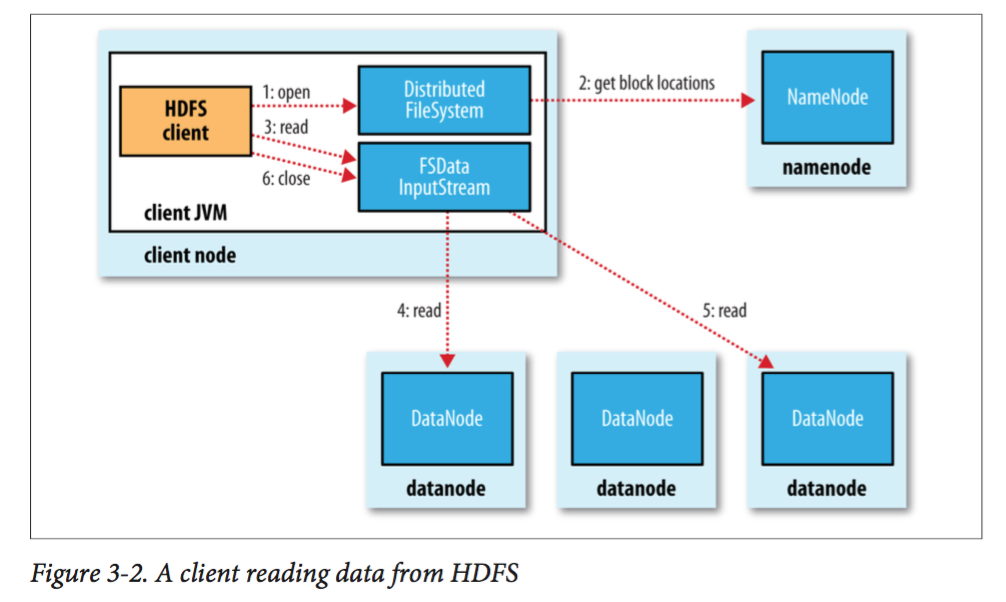
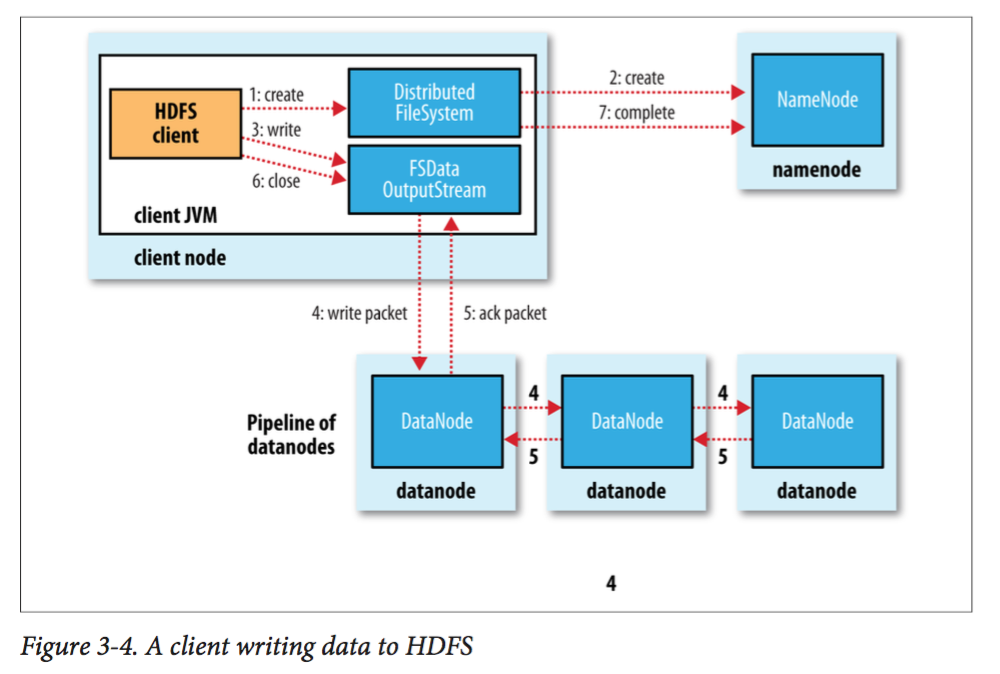
HDFS读写的过程见下面两张图,十分简单直接,这里不再赘述,有兴趣可以查阅其他博客。
这里简单展示一下hadoop的节点距离和3副本备份策略:
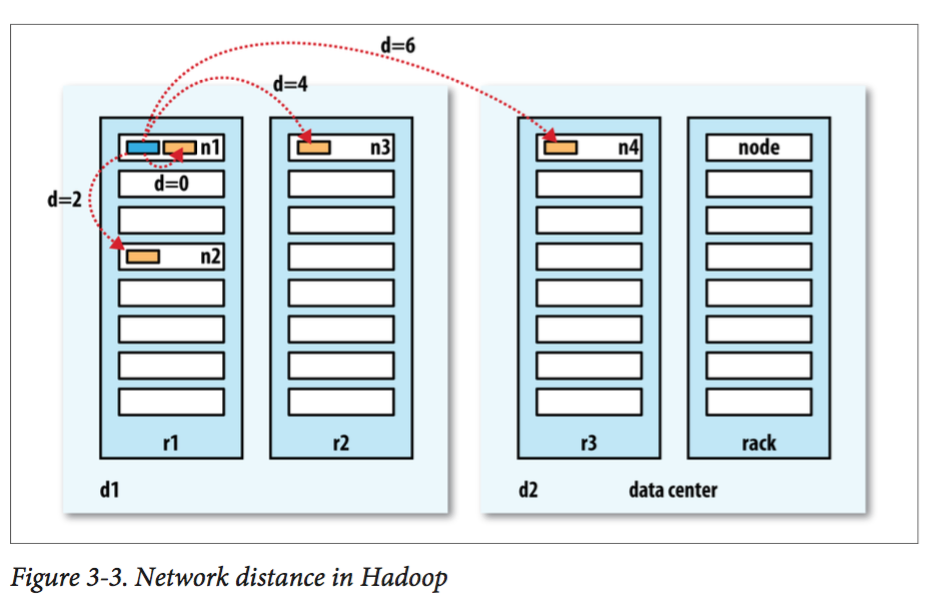

实际上hadoop先把第一个副本存在client所在的那个namenode(如果是外部的client则随机选取一个),然后把第二和第三个副本存在其他机架上的两个不同的node中。至于更多的副本则随机存储。
我们还需要介绍一下一致性模型(coherency model),即文件在读写时的数据可见性。HDFS中,所有block只有在写完后才对用户可见,如果它正在写则是用户不可见的。因此HDFS提供了两个函数来帮助用户:
- hflush(): 保证之前写入的数据都对用户可见。
- hsync(): 不仅仅保证可见,还将其写入持久性介质(如硬盘)。
最后我们在提一个hdfs指令:
hadoop distcp < dir1 > < dir2 >
这是hdsf并行地拷贝文件,往往在大规模数据迁移时很有用。















 385
385

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









