









Yarn简介
Yarn(Yet Another Resource Negotiator)是hadoop2中引入的一个集群资源管理系统。
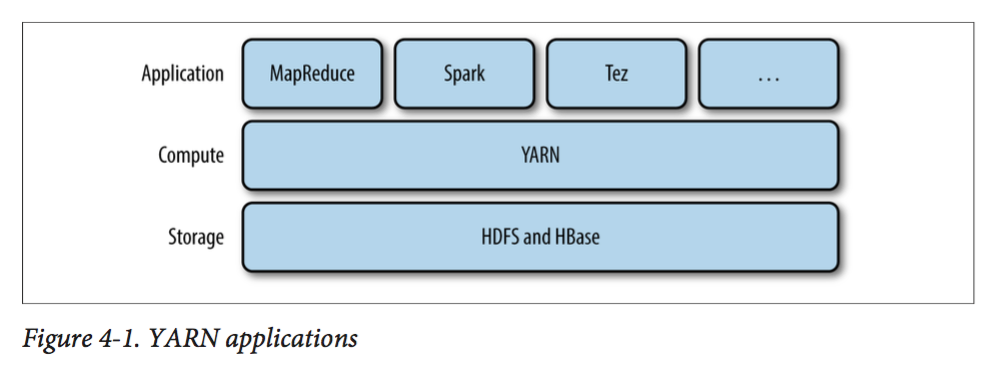
在YARN中,有两种核心服务:一个是ResourceManager,一个是NodeManager。前者每个集群有一个,用来管理集群上资源的使用;后者则是每个节点拥有一个,用来负责启动和监控Container。其中Container是一个拥有一定资源(cpu, mem, network等)的特殊进程。
下图则表明了YARN如何运行一个应用:
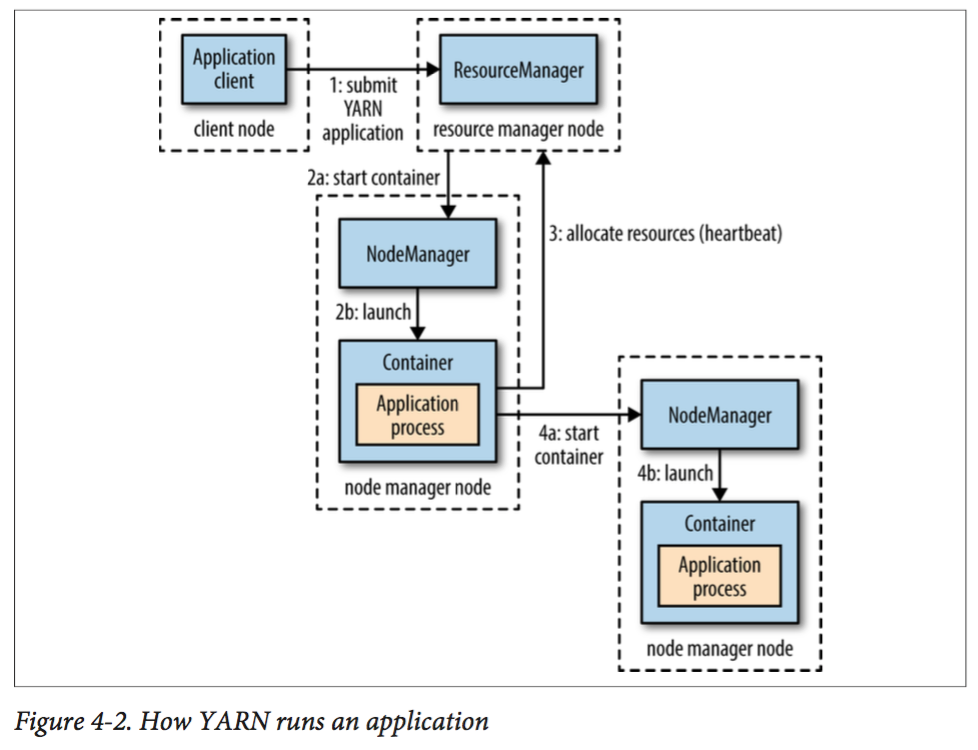
这里我们拿YARN和mapreduce1做对比:

在mapreduce1中application的调度和监控都由jobtracker负责,但在YARN中,则由多个模块负责:resource manager负责整个系统的资源分配;而Application Master(每一个application有一个)负责和rm协商获取资源(即container),同时也负责监控job的运行并在失败时尝试重启任务。
由此可见,新的YARN比mapreduce1有如下优点:
- 扩展性
- 高可用性
- 利用效率高:在mr1中, 每一个mr的application被分配给定数目且大小固定的slots;而在yarn中,application可以随时动态申请资源。
- 多租户(multi-tenacy):使得集群可以运行多种分布式应用,甚至是mapreduce的不同版本。
YARN中的调度
在YARN中,提供了三种调度器(Scheduler):FIFO, Capacity, Fari。调度效果如下图:

这里我们主要介绍后两种调度器,但在介绍之前,我们需要先介绍一下Yarn中的队列(queue)机制。在yarn中,有层级队列组织方法,它们构成一个树结构,且根队列叫做root。所有的应用都运行在叶子队列中(即树结构中的非叶子节点只是逻辑概念,本身并不能运行应用)。对于任何一个应用,我们都可以显式地指定它属于的队列,也可以不指定从而使用username或者default队列。下图就是一个队列的结构:

Capacity Scheduler
下面是以上图中的队列为例子给出的一个调度器配置文件:
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>prod,dev</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.queues</name>
<value>eng,science</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.prod.capacity</name>
<value>40</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.capacity</name>
<value>60</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.maximum-capacity</name>
<value>75</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.eng.capacity</name>
<value>50</value>
</property>
<property>
<name>yarn.scheduler.capacity.root.dev.science.capacity</name>
<value>50</value>
</property>
</configuration>正如你所见的,prod和dev分别默认分配root(也就是总资源)中40%和60%的资源,而dev的两个子队列则分配当前dev分配到的资源的50%和50%的资源。
上面说默认分配,是因为YARN为了合理利用资源,有一个叫做queue elasticity的功能:即在大多时候,一个队列中的application是不能使用超过队列容量的资源的。但是如果队列中应用个数超过一个并且其他队列拥有空闲资源时,Capacity Scheduler会分配给它这些空闲的资源,哪怕使得总资源超过该队列的容量。
同时在Capacity Scheduler中,没有抢占资源这一说。因此当某个队列需要更多的资源时(比如本身属于它的资源被其他队列暂时借走),则必须等到其他队列自己还回资源。为了避免某个队列占用了全部资源从而导致其他队列完全无法运行应用的情况出现,我们可以在配置文件中设置maximum-capacity的值,例如上面的列子,dev对应的值是75,这就意味着dev队列最多使用75%的root资源,从而最少给prod留下25%的资源,从而避免刚刚所说的情况出现。
最后再提一句,由于yarn中队列只有叶子那一级才是真正能运行应用的队列。因此在Capacity Scheduler中指定应用队列时,只需要制定最后一个队列名字(如prod, eng)即可,不需要前面的路径(如root.prod或者dev.eng)。
Fair Scheduler
Fair Scheduler的目的是让所有运行的应用都能分到平等的资源(同一个队列内),如下图所示:
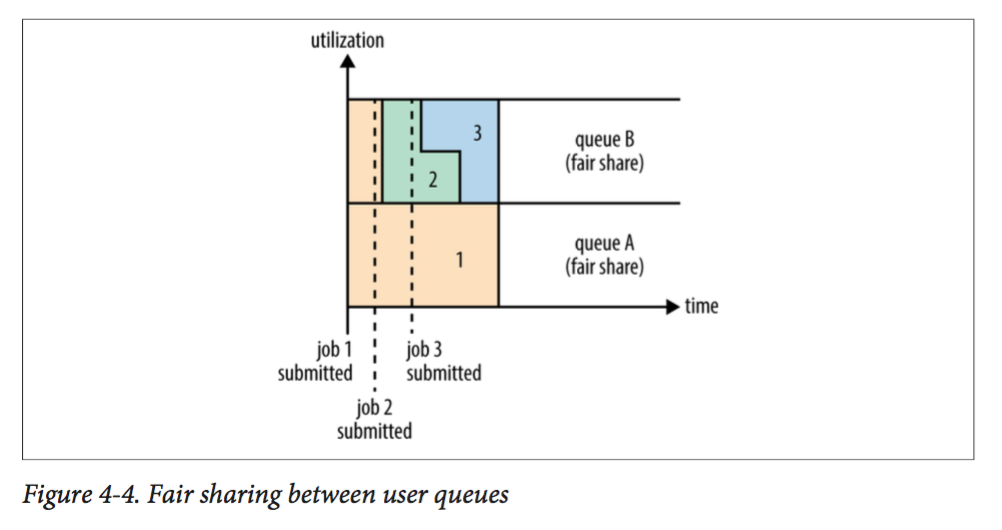
Fair Scheluder用一个叫做fair-scheduler.xml的文件定义。当然如果没有这个文件,则调度器采用默认的调度方式:每个application都被安排在以它的user为名字的队列中。我们还是以前面的队列为例写一个配置文件:
<?xml version="1.0"?>
<allocations>
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<queue name="prod">
<weight>40</weight>
<schedulingPolicy>fifo</schedulingPolicy>
</queue>
<queue name="dev">
<weight>60</weight>
<queue name="eng" />
<queue name="science" />
</queue>
<queuePlacementPolicy>
<rule name="specified" create="false" />
<rule name="primaryGroup" create="false" />
<rule name="default" queue="dev.eng" />
</queuePlacementPolicy>
</allocations>这里仍然是树状队列的结构,其中有一个key叫做weight,是指该队列和它的兄弟队列对资源分配的比值。例如prod和dev以40:60分配root的资源,注意和Capacity Scheduler不同,这里是比值因此并不需要加和为100,因此换成2和3也是同样的效果。注意到我们设定weight时,需要把default和动态生成的队列也考虑进去,他们的权重分别为1,尽管我们不会在配置文件中显示地配置他们。
此外队列还可以指定调度方式,分别有Fair Scheduler(默认), RDF和FIFO这些方式。我们可以用schedulingPolicy这个字段来指定当前队列内部的调度方式,如果没有则采用全局的defaultQueueSchedulingPolicy中的方式,如果还是没有则使用刚刚提到的Fair Scheduler。
当然我们还可以配置最小和最大资源,最大应用数目等。但是注意到,最小资源并不是硬性规定,实际上是用来优先获得资源分配的。例如两个队列都没有达到它们的需求,则当前更低于它的最小需求的队列会被优先分配资源。此外我们还可以用queuePlacementPolicy来指定每个application被分配到哪个队列。
Fair Scheduler是支持抢占的(preemption)。我们将yarn.scheduler.fair.preemption设置为ture即可让调度器支持优先级抢占,但还需要设置两个超时选项,一个是有关最小共享的,还有一个是和公平共享的,单位都是秒。默认两个是没有设定,因此需要我们自己手动设定其中至少一个。
如果一个队列在低于它最小分配资源的时间超过最小共享时间,则调度器会让它抢占其他队列的资源。我们可以用defaultMinSharePreemptionTimeout和minSharePreemptionTimeout来设置超时时间。
类似地,如果一个队列得到的资源低于它的公平资源的某个比例,且时间超过一定时间,调度器也会让它抢占其他队列资源。我们可以用defaultFairSharePreemptionThreshold和fairSharePreemptionThres来设定这个比例,默认是0.5;同时也可以用defaultFairSharePreemptionTimeout和fairSharePreemptionTimeout来设定超时时间。
延迟调度和RDF
在前面的介绍中,我们了解到我们调度都遵循按locality调度的原则,即优先考虑本节点,然后是同一个机架上的,最后才是不同机架上的节点。但是由于系统在繁忙时很难恰好调度到某个特定节点,只好退而求次找同一个机架上的节点。但是在实际中,人们发现如果能等待较短时间(秒级别),则有很大的机会在这个特定节点上获得容器,从而提高了效率。这个特性叫做延迟调度(delay scheduling),它同时被Capacity和Fair Scheduler支持。
在YARN中,node manager会定期向resource manager发送心跳请求来报告自己的情况(默认每秒一次)。而这些心跳请求对于应用来说就是潜在的调度机会。
在Capacity Scheduler中,通过设定一个整数给yarn.scheduler.capacity.node-locality-delay,则在收到的调度机会没超过这个数目前都不会放松locality要求。
而在Fair Scheduler中,设定一个小数给yarn.scheduler.fair.locality.threshold.node,则在集群上汇报了调度机会的节点数目没有超过这个比例之前都不会考虑机架上其他的节点。类似地还可以设定yarn.scheduler.fair.locality.threshold.rack来延迟考虑其他机架。
最后再提一下DRF(Dominant Resource Fairness)。我们之前说的资源,都是单一标准,例如只考虑内存(也是yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:假设集群有10TB mem和100 CPU,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB)。则两种应用分别需要系统(2%, 3%)和(6%, 1%)的资源,这就意味着A是mem主导的, B是CPU主导的,并且它俩的比例是3% : 6% = 1:2。这样两者就按照1:2的比例去分配资源。
而我们的两种调度器都支持这个调度方式。 Capacity Scheduler在xml文件中将yarn.scheduler.capacity.resource-calculator设定为 org.apache.hadoop.yarn .util.resource.DominantResourceCalculator。而Fair Scheduler则在前面已经提到过了。















 4000
4000

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









