







目录
上篇文章思考题
答案:
can not use nums(type [6]int) as type[5]int
注意:一个数组类型,包含元素类型和长度,不同长度,同样的元素也是不一样的类型。因此,今天的切片就很有意义。
简介
- 切片是引用类型
- 长度可以变化,容量随长度变化
- 是结构体-->可查看源代码
切片即动态数组,底层在当前数组不够用时,开辟更大的数组,拷贝后再增加元素。
声明
var 变量名 []type
func make(Type, size ...IntegerType[,capacity]) Type
内建函数make分配并初始化一个类型为切片、映射、或通道的对象。其第一个实参为类型,而非值。make的返回类型与其参数相同,而非指向它的指针。其具体结果取决于具体的类型:
切片:size指定了其长度。该切片的容量等于其长度。切片支持第二个整数实参可用来指定不同的容量;它必须不小于其长度,因此 make([]int, 0, 10) 会分配一个长度为0,容量为10的切片。
capacity可选,默认为指定的长度,make底层也有数组,不可见
源代码查看
src->runtime->slice.go
func makeslice(et *_type, len, cap int) unsafe.Pointer {
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
return mallocgc(mem, et, true)
}切片声明代码
var slice []int
slice1 := make([]int,5)
fmt.Println("slice slice1:",slice,slice1)声明并初始化
一般形式
类似数组,直接写后面花括号里面,代码:
slice2 := []int{1,2,3,4}引用数组
给出数组数据
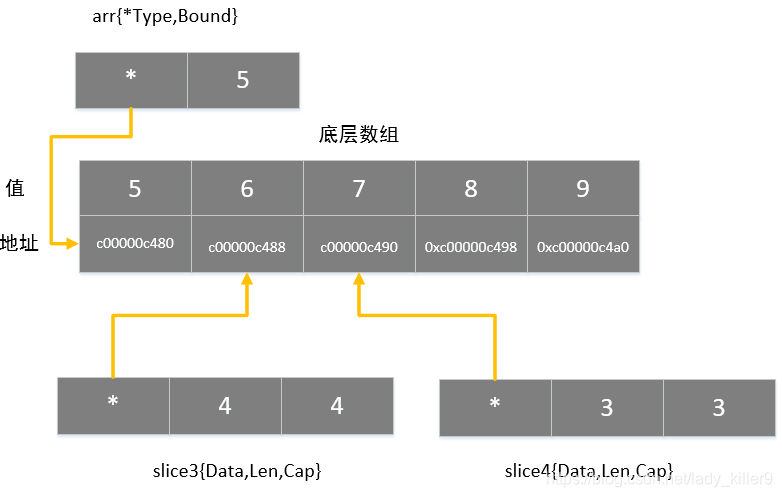
arr := [5]int{5,6,7,8,9}slice[start:end],默认:start=0,end =len(arr)
代码
slice3 := arr[1:]引用切片
和引用数组类似
slice4 := slice3[1:]切片及数组在内存的情况,请查看后序内存一节。
遍历
for
for i:=0;i<len(slice3);i++{
fmt.Print(slice3[i]," ")
}for range
for _,v := range slice3{
fmt.Print(v," ")
}内存
查看结构体的具体内容
src->reflect->type.go
type SliceHeader struct {
Data uintptr
Len int
Cap int
}编译时创建切片代码
src->cmd->compile->types
// NewSlice returns the slice Type with element type elem.
func NewSlice(elem *Type) *Type {
if t := elem.Cache.slice; t != nil {
if t.Elem() != elem {
Fatalf("elem mismatch")
}
return t
}
t := New(TSLICE)
t.Extra = Slice{Elem: elem}
elem.Cache.slice = t
return t
} fmt.Printf("&slice1:%p,&slice1[0]:%v\n", &slice1, &slice1[0])
fmt.Printf("&arr:%p &arr[1]:%v &slice3:%p &slice3[0]:%v\n",&arr,&arr[1],&slice3,&slice3[0])
fmt.Printf("&slice4:%p &slice4[0]:%v\n",&slice4,&slice4[0])
arr[2] = 99
fmt.Println("slice3[1] slice4[0]",slice3[1],slice4[0])

函数/方法
长度与容量
len、cap函数获取长度和容量
代码
fmt.Println("len(slice3) cap(slice3) len(slice4) cap(slice4):", len(slice3), cap(slice3), len(slice4), cap(slice4))追加与拷贝
append
func append(slice []Type, elems ...Type) []Type
内建函数append将元素追加到切片的末尾。若它有足够的容量,其目标就会重新切片以容纳新的元素。否则,就会分配一个新的基本数组。append返回更新后的切片,因此必须存储追加后的结果。
查看slice增长源代码
src->runtime->slice.go
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}![]()
代码
newSlice3 := append(slice3, 110,119)
newSlice4 := append(slice4,slice3...)拷贝
func copy(dst, src []Type) int
内建函数copy将元素从来源切片复制到目标切片中,也能将字节从字符串复制到字节切片中。copy返回被复制的元素数量,它会是 len(src) 和 len(dst) 中较小的那个。来源和目标的底层内存可以重叠。
注意:目标长度放不下时,后序的就不再拷贝了
代码
copy(slice3, slice1)排序
func Ints(a []int)
Ints函数将a排序为递增顺序。
代码
sort.Ints(newSlice3)插入与删除
没有,自己实现,见后面
函数传参
值传递
func byteInsert(b []byte,index int,data byte) []byte{
//-----索引越界------
if index<0 || index>len(b){
return []byte{}
}
//------前插-------
if index == 0{
return append([]byte{data}, b...)
}
//------尾插-------
if index == len(b){
return append(b, data)
}
//------中间插------
tmp := append(b[:index],data)
return append(tmp,b[index:]...)
}使用
//-----值传递------
hello := []byte("el")
hello = byteInsert(hello,0,'h')
fmt.Printf("hello:%c\n",hello)
hello = byteInsert(hello,2,'l')
fmt.Printf("hello:%c\n",hello)
hello = byteInsert(hello,4,'o')
fmt.Printf("hello:%c\n",hello)引用传递
func byteDelete(b *[]byte,index int){
//-----索引越界------
if index<0 || index>=len(*b){
return
}
//------前删-------
if index == 0{
*b = (*b)[1:]
return
}
//------尾删-------
if index == len(*b)-1{
*b = (*b)[:len(*b)-1]
return
}
//------中间删------
*b = append((*b)[0:index],(*b)[index+1:]...)
return
}使用
world := []byte("world")
byteDelete(&world,0)
fmt.Printf("world:%c\n",world)
byteDelete(&world,3)
fmt.Printf("world:%c\n",world)
byteDelete(&world,1)
fmt.Printf("world:%c\n",world)注意事项
- 引用数组,左闭右开
- append新的数组给切片,字符串可添加到[]byte切片
- copy不扩容,切片满了为止
全部代码
package main
import (
"fmt"
"sort"
)
func byteInsert(b []byte,index int,data byte) []byte{
//-----索引越界------
if index<0 || index>len(b){
return []byte{}
}
//------前插-------
if index == 0{
return append([]byte{data}, b...)
}
//------尾插-------
if index == len(b){
return append(b, data)
}
//------中间插------
tmp := append(b[:index],data)
return append(tmp,b[index:]...)
}
func byteDelete(b *[]byte,index int){
//-----索引越界------
if index<0 || index>=len(*b){
return
}
//------前删-------
if index == 0{
*b = (*b)[1:]
return
}
//------尾删-------
if index == len(*b)-1{
*b = (*b)[:len(*b)-1]
return
}
//------中间删------
*b = append((*b)[0:index],(*b)[index+1:]...)
return
}
func main() {
//-----------------------声明--------------------
var slice []int
slice1 := make([]int,5)
fmt.Println("slice slice1:",slice,slice1)
//--------------------声明并初始化-----------------
//---------一般形式---------
slice2 := []int{1,2,3,4}
//---------从数组切片--------
arr := [5]int{5,6,7,8,9}
slice3 := arr[1:]
//---------从切片切片-------
slice4 := slice3[1:]
fmt.Println("slice2 slice3 slice4:",slice2,slice3,slice4)
//--------------------遍历-----------------------
//-----for-----
fmt.Println("slice3:")
for i:=0;i<len(slice3);i++{
fmt.Print(slice3[i]," ")
}
fmt.Println()
//-----for range----
fmt.Println("slice3:")
for _,v := range slice3{
fmt.Print(v," ")
}
fmt.Println()
//----------------内存---------------------------
fmt.Printf("&slice1:%p,&slice1[0]:%v\n", &slice1, &slice1[0])
fmt.Printf("&arr:%p &arr[1]:%v &slice3:%p &slice3[0]:%v\n",&arr,&arr[1],&slice3,&slice3[0])
fmt.Printf("&slice4:%p &slice4[0]:%v\n",&slice4,&slice4[0])
arr[2] = 99
fmt.Println("slice3[1] slice4[0]",slice3[1],slice4[0])
//-----------------函数-------------------------
//-------长度和容量----------
fmt.Println("len(slice3) cap(slice3) len(slice4) cap(slice4):", len(slice3), cap(slice3), len(slice4), cap(slice4))
//-------添加和拷贝------------
newSlice3 := append(slice3, 110,119)
newSlice4 := append(slice4,slice3...)
copy(slice3, slice1)
fmt.Println("slice3追加后 slice4追加slice3后 slice3拷贝slice1后:",newSlice3,newSlice4,slice3)
//--------排序------------------
sort.Ints(newSlice3)
fmt.Println("升序newSlice3:",newSlice3)
//---------------插入和删除---------------------
//-----值传递------
hello := []byte("el")
hello = byteInsert(hello,0,'h')
fmt.Printf("hello:%c\n",hello)
hello = byteInsert(hello,2,'l')
fmt.Printf("hello:%c\n",hello)
hello = byteInsert(hello,4,'o')
fmt.Printf("hello:%c\n",hello)
//------引用传递---------
world := []byte("world")
byteDelete(&world,0)
fmt.Printf("world:%c\n",world)
byteDelete(&world,3)
fmt.Printf("world:%c\n",world)
byteDelete(&world,1)
fmt.Printf("world:%c\n",world)
}
结果截图

参考
更多Go相关内容:Go-Golang学习总结笔记
有问题请下方评论,转载请注明出处,并附有原文链接,谢谢!如有侵权,请及时联系。如果您感觉有所收获,自愿打赏,可选择支付宝18833895206(小于),您的支持是我不断更新的动力。
















 3377
3377

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











