









#本文内容部分来自网络,只为自己学习以及分享供更多的人学习使用
1、Mini-batch
我们知道,当训练数据数量较大的时候,训练速度则显得至关重要。
前面我们介绍了向量化会大大加快训练的速度。但是如果把所有的特征输入x全部放入一个向量进行运算的时候,如果特征值太大,则会导致每次迭代的时间会比较久。所以,我们选取一个中间值,来均衡。
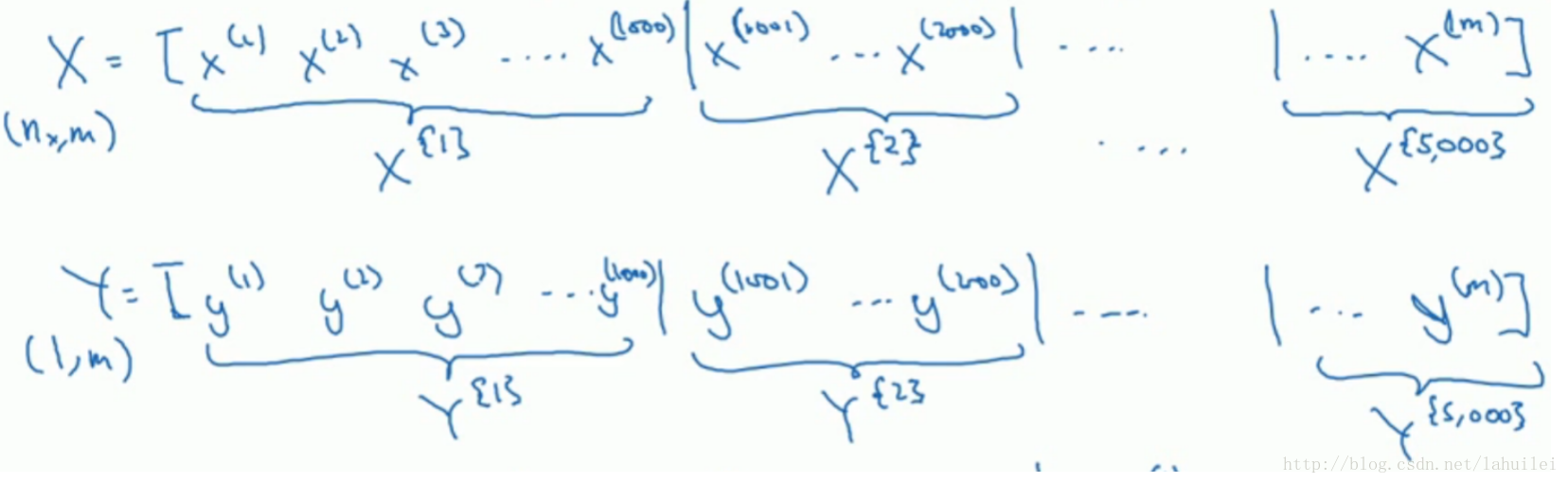
如图所示,我们以1000为单位,将数据进行划分,这就是所谓的mini-batch方法。
对于不同size:
1、batch梯度下降:
对所有m个训练样本执行一次梯度下降,每一次迭代时间较长;
Cost function 总是向减小的方向下降
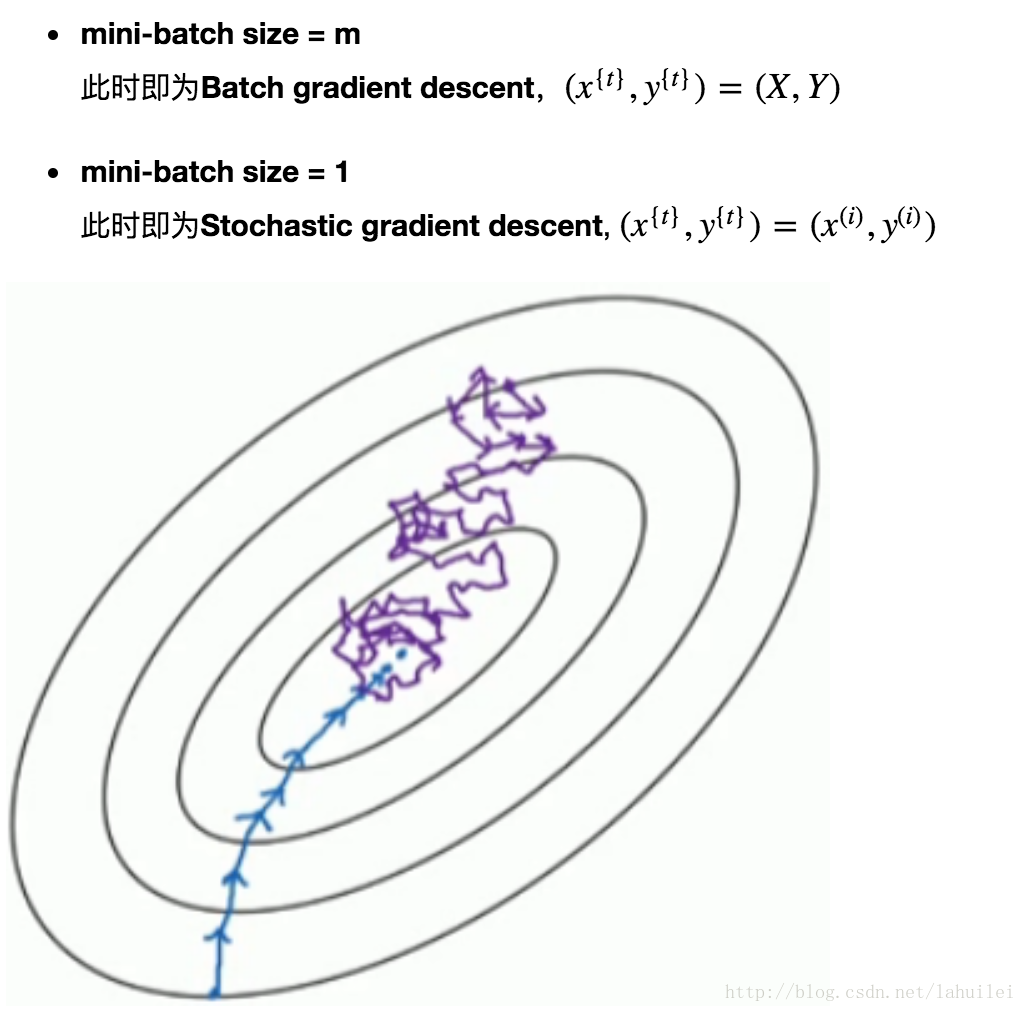
2、随机梯度下降:
对每一个训练样本执行一次梯度下降,但是丢失了向量化带来的计算加速;
Cost function总体的趋势向最小值的方向下降,但是无法到达全局最小值点,呈现波动的形式。
3、Mini-batch梯度下降:
选择一个合适的mini-batch size;
一般来说mini-batch size取2的次方比较好,例如64,128,256,512等,因为这样与计算机内存设置相似,运算起来会更快一些。
-
- 如下图所示,显示size = m和1的两种极端情况:
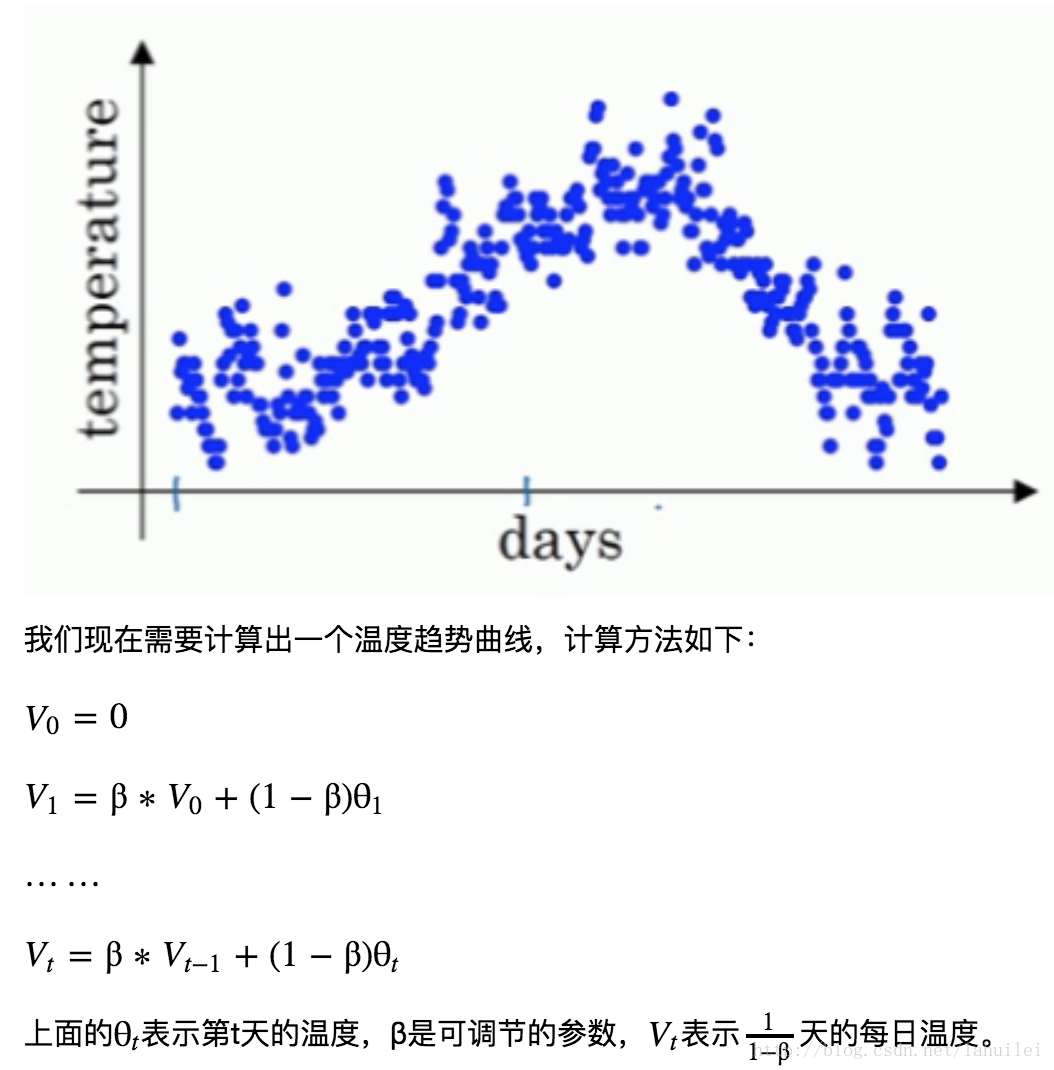
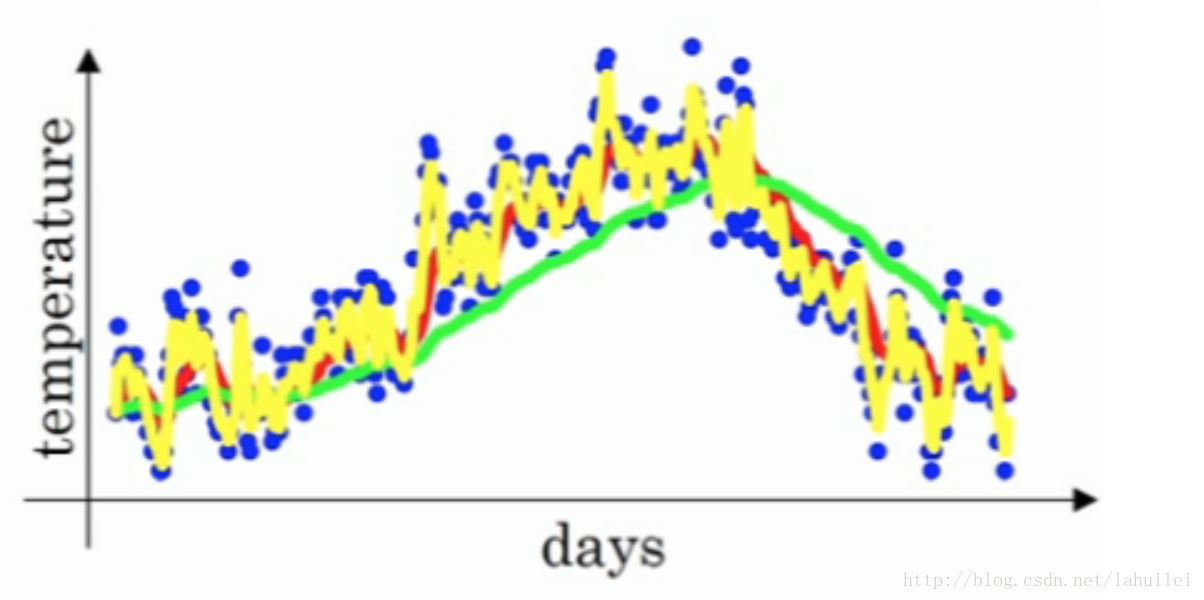
- 当 β=0.9 时,指数加权平均最后的结果如图中红色线所示;
- 当 β=0.98 时,指数加权平均最后的结果如图中绿色线所示;
- 当 β=0.5 时,指数加权平均最后的结果如下图中黄色线所示;
当
β=0.9
时:
展开:
上式中所有 θ 前面的系数相加起来为1或者接近于1,称之为偏差修正。
总体来说, (1−ε)1/ε=1e ,在我们的例子中, 1−ε=β=0.9 ,即 0.910≈0.35≈1e 。相当于大约10天后,系数的峰值(这里是0.1)下降到原来的 1e ,只关注了过去10天的天气。学习
课堂上还稍微提了下 前期均值偏差 的问题,感兴趣的同学可以去搜一下。
但是在实际过程中,一般会忽略前期均值偏差的影响。
3、动量梯度下降(Momentum)和RMSprop
Momentum:
基本思想就是计算梯度的指数加权平均数,并利用该梯度来更新权重。



Adam 优化算法:

之前提到的学习率α都是一个常数,这样有可能会一个问题,就是刚开始收敛速度刚刚好,可是在后面收敛过程中学习率偏大,导致不能完全收敛,而是在最低点来回波动。
学习率衰减的实现
- 常用:
α=11+decay_rate∗epoch_numα0
- 指数衰减:
α=0.95epoch_num α * 0
- 其他:
α=kepoch_num*α0
- 离散下降(不同阶段使用不同的学习速率)
5、局部最优问题

图左中有很多局部最优点。
图右用青色标记出来的点称为鞍点(saddle point),因为和马鞍相似,所以称为鞍点。
鞍点相比于局部最优点要更加棘手,因为从横向上看似乎是最低点,但是纵向上看却不是最低点,所以收敛过程有点缓慢
一般利用Adam算法来加速学习过程。
















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











