







端模式(Endian)这个词可以追溯到1726年的Jonathan Swift的《格列佛游记》,其中一篇讲到有两个国家因为吃鸡蛋究竟是先打破较大的一端还是先打破较小的一端而争执不休,甚至爆发了战争。
1981年10月,Danny Cohen的文章《论圣战以及对和平的祈祷》(On holy wars and a plea for peace)将这一对词语引入了计算机界。这么看来,所谓大端和小端,也就是big-endian和little-endian,其实是从描述鸡蛋的部位而引申到计算机地址的描述,也可以说,是从一个俚语衍化来的计算机术语。——Cyberspace_TechNode_五岳的博客
1、大端和小端的含义
1)大端(Big-Endian)就是高位字节排放在内存的低地址端。
2)小端(Little-Endian)就是低位字节排放在内存的低地址端。
在裘宗燕翻译的《程序设计实践》里,将之翻译“高尾端”和“低尾端”。那么根据这个解释,我们就可以很容易理解。假如把一个32位的整数0x12345678存放到一个整形变量(int)中,我们把0x12345678看作一个字符串“12345678”,那么在内存中的放法就如图所示:
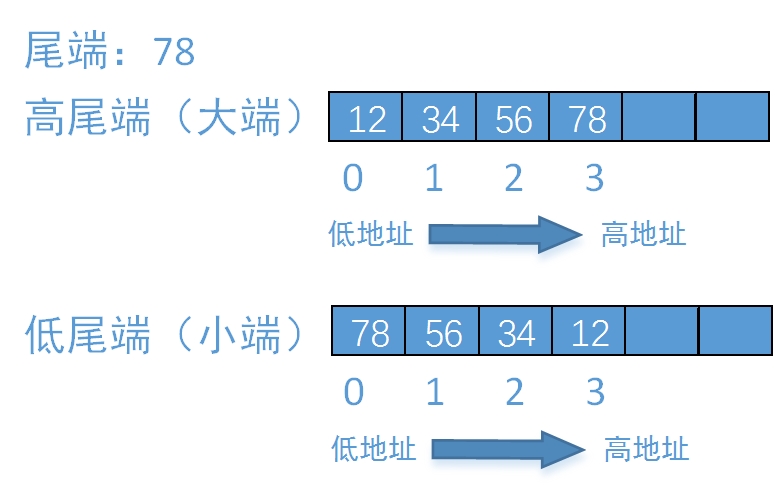
相对于“ 大/小“端,”高/低“尾端可能更好理解,但是很凑巧的是,“高”对应“大”,“低”对应“小”;这样就很好记忆了。
(数据看作字符串) 大端——高尾端,小端——低尾端
2、大小端相关
1.为什么会有大小端之分?
在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short,32bit的long(和编译器也有关),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如何将多个字节安排的问题。因此就导致了大端储存模式和小端储存模式。
2.如何判断机器是大端还是小端
#include<stdio.h>
int main(){
int a = 0x1234;
char b = *(char*)&a; //强制转换为char单字节,通过判断起始位置,即b为a的低地址部分
if (b == 0x12)
printf("Big-Endian\n");
else
printf("Little-Endian\n");
return 0;
}以上就是我搜索资料后,对大端小端的一点粗浅的看法,以后可能会有更详细的理解。















 191
191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









