









 本文深入探讨了字节序(Endianness)的概念,包括big-endian和little-endian的区别,以及如何通过联合体union和内存地址判断处理器的字节序模式。提供了实际代码示例,解释了不同处理器架构如X86、ARM、PowerPC和SPARC的字节序特性。
本文深入探讨了字节序(Endianness)的概念,包括big-endian和little-endian的区别,以及如何通过联合体union和内存地址判断处理器的字节序模式。提供了实际代码示例,解释了不同处理器架构如X86、ARM、PowerPC和SPARC的字节序特性。
字节序(Endianness)
在计算中,字节序是指数字的二进制表示形式中字节(或有时是位)的顺序。它也可以更一般地用于指代任何表示形式的内部排序,例如数字系统中的数字或日期的各个部分。
在最常见的用法中,字节顺序表示多字节数字中字节的顺序。big-endian顺序将最高有效字节排在最前面(优先入栈,在低地址),最低有效字节排在最后(在高地址),而little-endian的顺序则正好相反。例如,考虑无符号十六进制数0x1234,它需要至少两个字节来表示。在大端顺序中,它们将是12 34字节序;在小端顺序中,将对字节进行排列34 12(假设内存地址生长方向为 从左到右 由低到高)。
- 大端模式(Big_endian):字数据的高字节存储在低地址中,而字数据的低字节则存放在高地址中。
- 小端模式(Little_endian):字数据的高字节存储在高地址中,而字数据的低字节则存放在低地址中。
注意:字节序,字节序,是以字节为单位的,0x12表示一个字节是不会拆开,1与2不会又进行排序的。
举一个例子,如果我们将0x1234abcd(书写的字节从左到右由低到高)写入到以0x0000开始的内存中,则结果为 :
| addr | big-endian | little-endian |
|---|---|---|
| 0x0000 | 0x12 | 0xcd |
| 0x0001 | 0x34 | 0xab |
| 0x0002 | 0xab | 0x34 |
| 0x0003 | 0xcd | 0x12 |
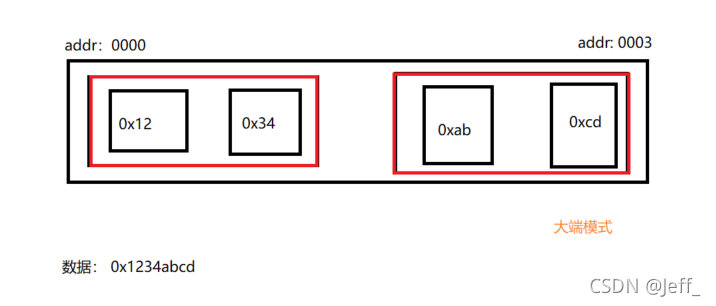
我们常用的X86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式(双向模式)。
注意,术语“双向”主要是指处理器如何处理数据访问。即使数据访问是完全双端的,给定处理器上的指令访问(获取指令字)仍可能采用固定的字节序,尽管并非总是如此,例如在基于Intel IA-64的Itanium CPU上,两者都允许。
还要注意,某些名义上的双端CPU需要主板帮助才能完全切换字节顺序。例如,从执行程序的角度来看,处于低位优先模式的32位面向桌面的PowerPC处理器起着低位优先的作用,但是它们要求母板在所有8个字节通道上执行64位交换,以达到确保事物的小端顺序视图将适用于I / O设备。在没有这种异常的主板硬件的情况下,设备驱动程序软件必须写入不同的地址以撤消不完整的转换,并且还必须执行正常的字节交换。
某些CPU(例如许多用于嵌入式的PowerPC处理器以及几乎所有的SPARC处理器)允许按页选择字节顺序。
自1990年代后期以来的SPARC处理器(兼容“ SPARC v9”的处理器)允许使用从存储器中加载或存储到存储器中的每个单独指令来选择数据字节序。
使用联合体union判断大小端
判断处理器是Big还是Little模式,一般有两种方法。利用在栈中指针指向的是最低地址的那个字节(PUSH入栈)
方法一:
如果小端方式(i占至少两个字节的长度)则i所分配的内存最小地址那个字节中就存着1,其他字节是0.大端的话则1在i的最高地址字节处存放,char是一个字节,所以强制将char型量p指向i则p指向的一定是i的最低地址,那么就可以判断p中的值是不是1来确定是不是小端。
int i=1;
char *p=(char *)&i;
if(*p==1)
printf("Little Endian");
else
printf("Big Endian");
方法二:
首先,我们要知道联合体union内可以定义多种不同的数据类型,这些数据共享同一段内存,也就是使用的覆盖技术,变量间互相覆盖,以达到节省空间的目的。
union的存放顺序是所有成员都从低地址开始存放。 Union的大小为其内部所有变量的最大值,并且按照类型最大值的整数倍进行内存对齐。
(ps:联合里面的东西共享内存,所以静态、引用都不能用,因为他们不可能共享内存。)
简单举两个例子:
typedef union
{
char c[10];
int i;
}u22;
typedef union
{
char c[10];
double d;
}u33;
按照char c[10]分配10个字节,然后按照int的4个字节对齐,最终sizeof(u22)=12,按照double的8个字节对齐,最终sizeof=16;

再来个例子,这是一道面试题,要求你说出正确输出:
#include <stdio.h>
typedef union un{
short i;
char ch[2];
} un;
int main()
{
un u;
u.ch[0] = 10;
u.ch[1] = 1;
printf("%d", u.i);
return 0;
}
解析:
- 10 相当于 0000 1010 低地址
- 1 相当于 0000 0001 高地址
如果是小端模式,低地址存放低位,高地址存放高位,那么该值按照正常顺序书写就是: 0000 0001 0000 1010,结果为266。
然后我们应该可以理解下面这段代码判断大小端的方式:
int isLittleEndian( )
{
{
union w
{
int a;
char b;
} c;
c.a = 1;
return(c.b ==1);
}
}
我们再来看看Linux 操作系统中相关的源代码是怎么做的:
static union {
char c[4];
unsigned long mylong;
} endian_test = {
{ 'l', '?', '?', 'b' }
};
#define ENDIANNESS ((char)endian_test.mylong)
Linux 的内核作者们仅仅用一个union 变量和一个简单的宏定义就实现了一大段代码同样的功能!由以上一段代码我们可以深刻领会到Linux 源代码的精妙之处!(如果ENDIANNESS=’l’表示系统为little endian,为’b’表示big endian )
最后再看一道关于位域以及栈生长方向的试题:
#include<iostream>
#include <string.h>
#include <malloc.h>
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
using namespace std;
typedef struct AA
{
int b1:5;
int b2:2;
}AA;
int main()
{
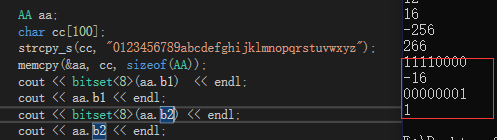
AA aa;
char cc[100];
strcpy_s(cc,"0123456789abcdefghijklmnopqrstuvwxyz");
memcpy(&aa,cc,sizeof(AA));
cout << aa.b1 <<endl;
cout << aa.b2 <<endl;
}
首先我们注意到传入的是字符,所以其使用ASCII码表示的,我们需要转换。
然后sizeof(AA)的大小为4,b1和b2分别占5bit和2bit.经过strcpy和memcpy后,aa的4个字节所存放的值是: 0,1,2,3的ASCII码,即 00110000,00110001,00110010,00110011.
最后一步,显示的是这4个字节的前5位,和 之后的2位分别为:10000,和01 。又因为位域扩展时,会以最高位作为符号位扩展,10000 扩展为 1111 0000 ,8位二进制符号位为1表示为负数,转化为十进制,结果为-16。01扩展为 0000 0001 ,符号位为0表示为正数,不变,就是01。
参考资料:
测试用到的代码:
#include <iostream>
#include <cstdio>
#include <bitset>
using namespace std;
union Test
{
char a[4];
short b;
};
int isLittleEndian()
{
{
union w
{
int a;
char b;
} c;
c.a = 1;
return(c.b == 1);
}
}
typedef union
{
char c[10];
int i;
}u22;
typedef union
{
char c[10];
double d;
}u33;
typedef union un {
short i;
char ch[2];
} un;
typedef struct AA
{
int b1 : 5;
int b2 : 2;
}AA;
int main() {
int i = 1;
char *p = (char *)&i;
if (*p == 1)
printf("Little Endian\n");
else
printf("Big Endian\n");
cout << sizeof(u22) << endl;
cout << sizeof(u33) << endl;
Test test;
test.a[0] = 256;
test.a[1] = 255;
test.a[2] = 254;
test.a[3] = 253;
printf("%d\n", test.b);
un u;
u.ch[0] = 10;
u.ch[1] = 1;
printf("%d\n", u.i);
AA aa;
char cc[100];
strcpy_s(cc, "0123456789abcdefghijklmnopqrstuvwxyz");
memcpy(&aa, cc, sizeof(AA));
cout << bitset<8>(aa.b1) << endl;
cout << aa.b1 << endl;
cout << bitset<8>(aa.b2) << endl;
cout << aa.b2 << endl;
}

















 758
758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









