







在之前写的一篇《HashSet、HashMap和Hashtable的区别》中,大致分析了一下实现方式和区别,但是HashMap的工作是怎样的?如果遇到hashCode相等怎么办?如果超过了负载因子又怎么办?这些问题,依然值得我们去深思和理解。
HashMap的特性
几乎所有人都知道HashMap的一些特性,譬如说:
1、HashMap可以接受key-value为null,Hashtable不可以;
2、HashMap是非synchronized;
3、HashMap速度很快;
4、HashMap储存键值对等等。
这是它的一些基础性的东西,相信我们不看源码也能够了解。
HashMap的实现原理
在JDK1.6,JDK1.7中,HashMap用链表数组实现(桶+链表),用链表来处理冲突。同一hash值的链表都存储在一个链表里面,但是当位于一个桶中的元素较多,即hash值相等的元素太多的话,通过key依次查找的效率就比较低。而JDK1.8中,HashMap采用桶+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树。针对上述情况,将大大减少查找时间。
HashMap实现原理:
首先有一个每个元素都是链表的数组,当添加一个元素(key-value)时,就首先计算元素key的hash值,以此确定插入数组中的位置。但是可能存在同一hash值的元素已经被放在数组的同一个位置了,这时候就需要添加在hash值的元素的后面,由于它们都在数组的同一个位置,所以就形成了链表。同一个链表上的hash值是相同的,所以说数组存放的是链表,当链表长度过大时(超过阈值8),则转换为红黑树,大大提升查找效率。
HashMap原理图:
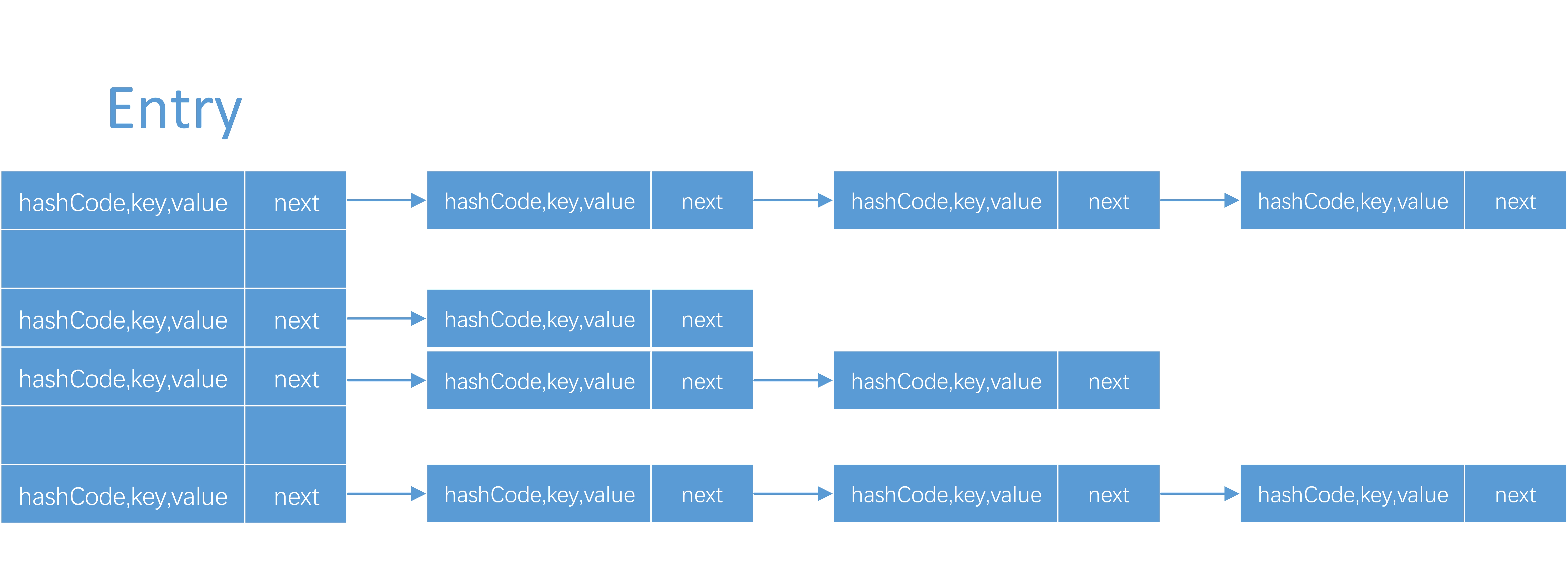
一、HashMap中使用的数据结构(JDK1.8)
1、位桶数组。在以前的源码或者查找到的资料中,我发现都是Entry,但是在1.8的源码中却是用Node来命名的。
transient Node<K,V>[] table; //存储数组<K, V>2、数组元素Node实现了Map.Entry接口
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
//Node实际上是一个单向链表,实现了Map.Entry接口
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
//构造函数 通过hashCode,键,值,构造,并指向下一个节点
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
//判断两个Node是否相等,若key和value都相等,返回true。
//若和自身比较,直接返回true。
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}3、红黑树
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links 父节点
TreeNode<K,V> left; //左子树
TreeNode<K,V> right; //右子树
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; //颜色属性
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}二、源码中的数据域
加载因子(默认0.75)、初始大小(默认16个Node):为什么需要使用加载因子和扩容呢?如果填充比过大,利用空间很多,一直不扩容,链表就会越来越长,导致查找效率的降低(当然转化为红黑树过后会好很多)。扩容过后,将原来链表数组的每一个链表分成奇偶两个小链表分别挂在新桶的散列位置,减少了链表长度,提升效率和速度。
HashMap本就是空间换时间,所以填充比不可能太大。但是填充比太小又会导致空间浪费,如果关注内存,填充比可以大一些;如果关注效率,填充比可以小一点。
public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable {
private static final long serialVersionUID = 362498820763181265L;
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 初始默认大小16
static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量
static final float DEFAULT_LOAD_FACTOR = 0.75f;//填充比
//当add一个元素到某个位桶,其链表长度达到8时将链表转换为红黑树
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
transient Node<k,v>[] table;//存储元素的数组
transient Set<map.entry<k,v>> entrySet;
transient int size;//存放元素的个数
transient int modCount;//被修改的次数fast-fail机制
int threshold;//临界值 当实际大小(容量*填充比)超过临界值时,会进行扩容
final float loadFactor;//填充比三、HashMap的构造函数
HashMap一共有四种构造函数,参数都有:容量、填充因子、其他的Map
//构造函数1 通过指定容量和指定填充因子来构造
public HashMap(int initialCapacity, float loadFactor) {
//指定容量非负,否则抛出异常
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
//指定容量如果大于最大容量(1<<30),使用默认的最大容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
//填充比大于0,否则抛出异常
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
//扩容临界值
this.threshold = tableSizeFor(initialCapacity);
}
//构造函数2 指定容量,其他的使用default,填充因子0.75
public HashMap(int initialCapacity) {
this(initialCapacity, DEFAULT_LOAD_FACTOR);
}
//构造函数3 全部使用default生成
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
}
//构造函数4 通过已有的Map构造当前HashMap
public HashMap(Map<? extends K, ? extends V> m) {
this.loadFactor = DEFAULT_LOAD_FACTOR;
putMapEntries(m, false);
}四、HashMap的存取机制
1、如何getVaule
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
//找到插入的第一个Node,方法是hash值和n-1相与,tab[(n-1) & hash]
//也就是说在这个Node后面的链表上的hash值都是一样的
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; //Entrt对象数组
Node<K,V> first, e; //在tab中经过散列表的第一个位置
int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
//检查该数组位置上的第一个Node是否为要找的
//从源码也可以看到这里写着always check first node
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
//检查first后面的node
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
//遍历后面的链表,找打key和hash都相同的Node,并返回
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}get()方法去获取key的值时,先计算(n-1) & hash得到在链表数组中first的位置为:first = tab[(n-1) & hash];接着先判断first的key和传入参数的key是否相等,如果不相等,就以此遍历后面的链表找到key和hash都相同的Node返回。
2、put(key, value)方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
/**
* Implements Map.put and related methods
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//如果tab在(n - 1) & hash的值为空,新建节点插入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
//否则说明有冲突,开始处理冲突
else {
Node<K,V> e; K k;
//检查第一个Node,看是否可以放入
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
//next为空,就挂在后面
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//如果冲突节点超过8个,判断是否需要改变储存结构
//treeifyBin判断当前HashMap长度,如果不足64,resize
//如果超过64,更改为红黑树存储
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
//如果有相同的key就结束遍历
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue; //返回存在的Value的值
}
}
++modCount;
if (++size > threshold)
resize(); //扩容两倍
afterNodeInsertion(evict);
return null;
}get()方法添加键值对的过程:
1、判断键值对是否为null,否则以默认大小resize;
2、根据key计算hash值,获得数组的索引 i, 如果tab[i] == null,直接添加,否则,进行冲突处理;
3、判断冲突方式是以链表还是红黑树处理。
PS:由于在上述代码的最后,有return oldVaule;这句话,所以,可以看出,如果当put一个新的key-value进去,返回null;但是如果put一个已有的key,就会返回当前位置存在的元素的hash值。
五、问题小结
1、HashMap的get()方法的工作原理
关键点在于HashMap是在bucket(桶,就是Entry数组)中存储key和value的,作为Map.Entry。不仅仅是只存储了一个值那么简单。
2、当两个对象的hashCode相同会发生什么?
hashCode相等,并不代表对象相等。因为在使用前,我们是需要重写equals()和hashCode()方法的,即使hashCode相等,对象也可能是不等的。此时就发生了冲突,由于使用LinkedList储存对象,所以会在后面增加节点,继续存储。
3、如果两个键(key)的hashCode相同,你如何获取值对象(value)?
如果两个key存储在同一个bucket,将会遍历LinkedList去找到值对象。这里的关键就在于问题1,你要知道在LinkedList中存储的是key-value(键值对),在找到bucket位置之后,会调用keys.equals()方法去找到正确的节点。否则就是无法把这个问题回答得好。
4、如果HashMap的大小超过了填充因子(load factor)定义的容量,怎么办?
默认的填充因子是0.75,也就是说,当bucket已经占用了75%时,它就会reszie一个两倍大的新的bucket,来调整大小。并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。
5、重新调整HashMap的大小存在什么问题?
当重新调整HashMap大小的时候,存在条件竞争。因为如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在LinkedList中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在LinkedList的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。
不过问题在于,为什么非要在多线程的环境在用HashMap,这不是好的行为。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









