









由前文Python爬虫(一):环境配置的方案选取可知,项目的核心是使用scrapy抓取感兴趣的内容,使用PyQt实时显示结果,所爬取的条目数量为10W数量级,访问频率在被网站可容忍的情况下尽可能的快。很明显,这里存在多任务并行,例如,多个爬之间属于并行任务,爬虫与GUI显示属于并行任务。使用python多进程模型应该是最基本的实现方式,数据流如下:
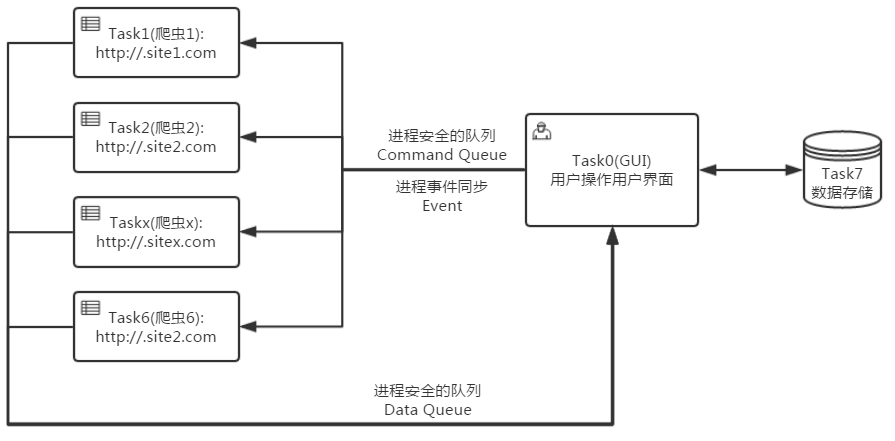
Task0为GUI进程,Task1~Task6为6个爬虫进程,每个进程负责下载和分析某个特定的网站,Task7为Task0的子线程,负责数据存储。各个进程间的数据通信采用进程安全的队列Queue,事件同步采用Event。
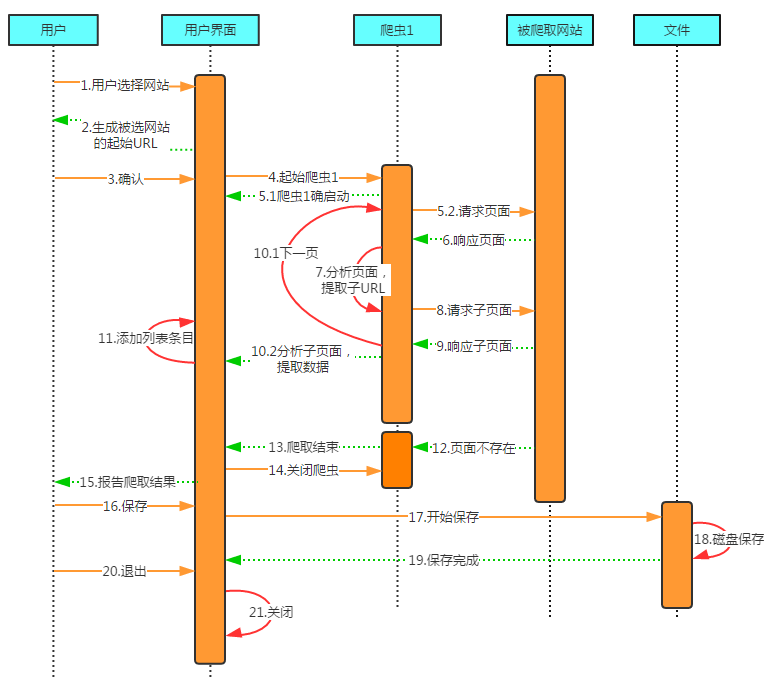
时序关系如下:















 1198
1198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









