







http://blog.csdn.net/book_mmicky/article/details/39288715
2014年9月11日,Spark1.1.0忽然之间发布。笔者立即下载、编译、部署了Spark1.1.0。关于Spark1.1的编译和部署,请参看笔者博客
Spark1.1.0 源码编译和部署包生成 。
Spark1.1.0中变化较大是sparkSQL和MLlib,sparkSQL1.1.0主要的变动有:
- 增加了JDBC/ODBC Server(ThriftServer),用户可以在应用程序中连接到SparkSQL并使用其中的表和缓存表。
- 增加了对JSON文件的支持
- 增加了对parquet文件的本地优化
- 增加了支持将python、scala、java的lambda函数注册成UDF,并能在SQL中直接引用
- 引入了动态字节码生成技术(bytecode generation,即CG),明显地提升了复杂表达式求值查询的速率。
- 统一API接口,如sql()、SchemaRDD生成等。
- ......
下面分十个小节来介绍sparkSQL1.1.0的架构和使用,希望各位读者joy it!
第二节:sparkSQL架构 介绍catalyst,然后介绍sqlContext、hiveContext的运行架构及区别
第三节:sparkSQL组件之解析 介绍sparkSQL运行架构中的各个组件的功能和实现
第四节:深入了解sparkSQL之运行 使用hive/console更深入了解各种计划是如何生成的
第五节:测试环境之搭建 介绍后面章节将使用的环境搭建和测试数据
第六节:sparkSQL之基础应用 介绍sqlContext的RDD、Json、parquet使用以及hiveContext使用
第七节:ThriftServer和CLI 介绍TriftServer和CLI的使用,以及如何使用JDBC访问sparkSQL数据
第八节:sparkSQL之综合应用 介绍sparkSQL和MLlib、sparkSQL和GraphX结合使用
第九节:sparkSQL之调优 介绍CG、压缩、序化器、缓存之使用
第十节:总结
至于与hive的兼容性、具体的SQL语法以后有机会再介绍。
一:为什么sparkSQL?
1:sparkSQL的发展历程。
A:hive and shark
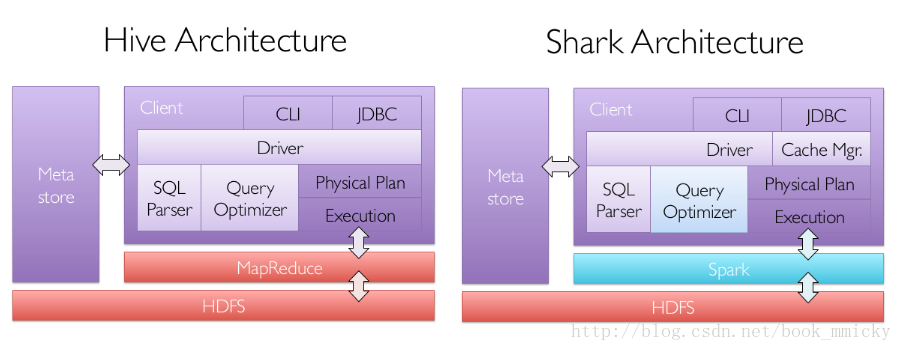
sparkSQL的前身是shark。在hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,是当时唯一运行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
- MapR的Drill
- Cloudera的Impala
- Shark
其中Shark是伯克利实验室spark生态环境的组件之一,它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于hive的太多依赖(如采用hive的语法解析器、查询优化器等等),制约了Spark的One Stack rule them all的既定方针,制约了spark各个组件的相互集成,所以提出了sparkSQL项目。SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码;由于摆脱了对hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便,真可谓“退一步, 海阔天空”。
- 数据兼容方面 不但兼容hive,还可以从RDD、parquet文件、JSON文件中获取数据,未来版本甚至支持获取RDBMS数据以及cassandra等NOSQL数据
- 性能优化方面 除了采取In-Memory Columnar Storage、byte-code generation等优化技术外、将会引进Cost Model对查询进行动态评估、获取最佳物理计划等等
- 组件扩展方面 无论是SQL的语法解析器、分析器还是优化器都可以重新定义,进行扩展
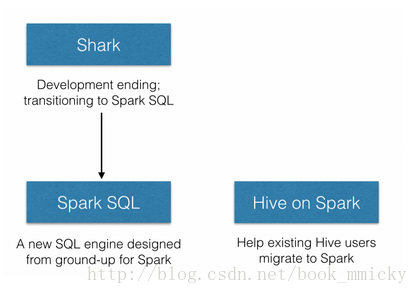
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放sparkSQL项目上,至此,Shark的发展画上了句话,但也因此发展出两个直线:SparkSQL和hive on spark。
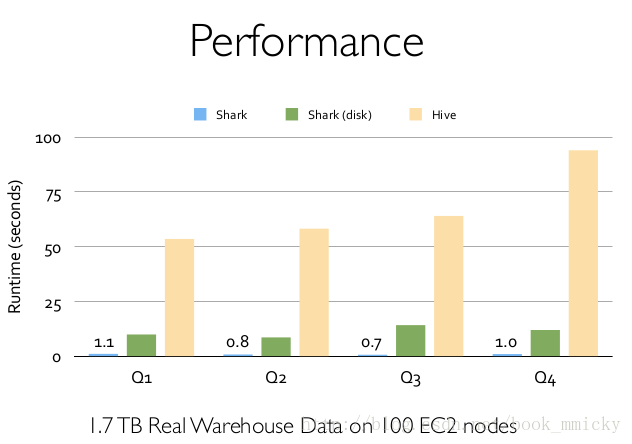
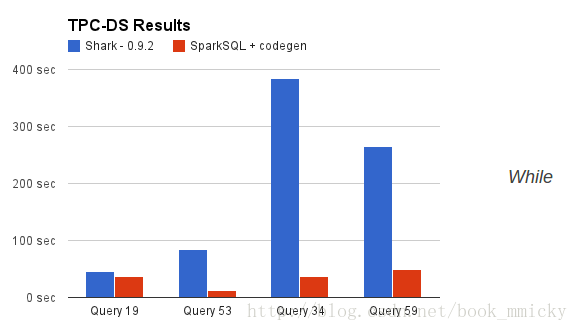
2:sparkSQL的性能
shark的出现,使得SQL-on-Hadoop的性能比hive有了10-100倍的提高:
A:内存列存储(In-Memory Columnar Storage)
sparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下图所示。

对于原生态的JVM对象存储方式,每个对象通常要增加12-16字节的额外开销,对于一个270MB的TPC-H lineitem table数据,使用这种方式读入内存,要使用970MB左右的内存空间(通常是2~5倍于原生数据空间);另外,使用这种方式,每个数据记录产生一个JVM对象,如果是大小为200B的数据记录,32G的堆栈将产生1.6亿个对象,这么多的对象,对于GC来说,可能要消耗几分钟的时间来处理(JVM的垃圾收集时间与堆栈中的对象数量呈线性相关)。显然这种内存存储方式对于基于内存计算的spark来说,很昂贵也负担不起。
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。这样,每个列创建一个JVM对象,从而导致可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。
B:字节码生成技术(bytecode generation,即CG)
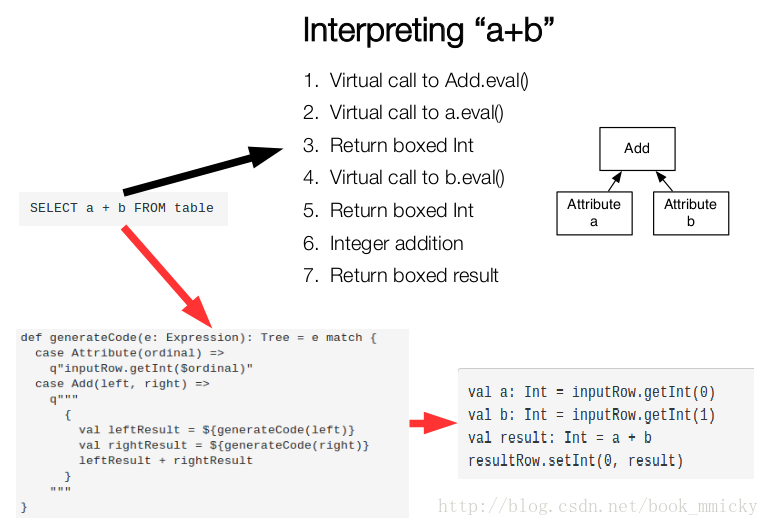
在数据库查询中有一个昂贵的操作是查询语句中的表达式,主要是由于JVM的内存模型引起的。比如如下一个查询:
- SELECT a + b FROM table
在这个查询里,如果采用通用的SQL语法途径去处理,会先生成一个表达式树(有两个节点的Add树,参考后面章节),在物理处理这个表达式树的时候,将会如图所示的7个步骤:
- 调用虚函数Add.eval(),需要确认Add两边的数据类型
- 调用虚函数a.eval(),需要确认a的数据类型
- 确定a的数据类型是Int,装箱
- 调用虚函数b.eval(),需要确认b的数据类型
- 确定b的数据类型是Int,装箱
- 调用Int类型的Add
- 返回装箱后的计算结果
其中多次涉及到虚函数的调用,虚函数的调用会打断CPU的正常流水线处理,减缓执行。
Spark1.1.0在catalyst模块的expressions增加了codegen模块,如果使用动态字节码生成技术(配置spark.sql.codegen参数),sparkSQL在执行物理计划的时候,对匹配的表达式采用特定的代码,动态编译,然后运行。如上例子,匹配到Add方法:

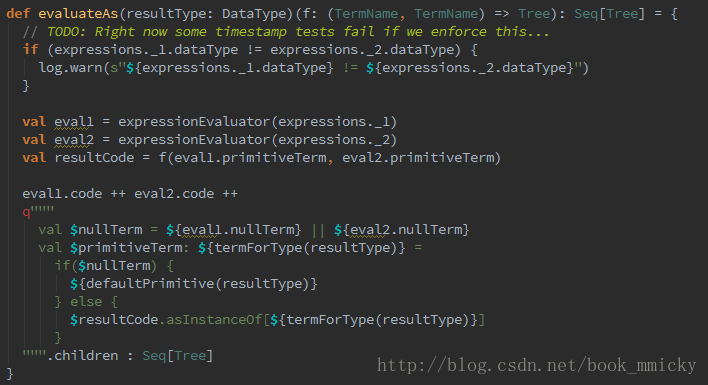
最终实现效果类似如下伪代码:
- val a: Int = inputRow.getInt(0)
- val b: Int = inputRow.getInt(1)
- val result: Int = a + b
- resultRow.setInt(0, result)
对于Spark1.1.0,对SQL表达式都作了CG优化,具体可以参看codegen模块。CG优化的实现主要还是依靠scala2.10的运行时放射机制(runtime reflection)。对于SQL查询的CG优化,可以简单地用下图来表示:
C:scala代码优化
另外,sparkSQL在使用Scala编写代码的时候,尽量避免低效的、容易GC的代码;尽管增加了编写代码的难度,但对于用户来说,还是使用统一的接口,没受到使用上的困难。下图是一个scala代码优化的示意图:

二:sparkSQL运行架构
在介绍sparkSQL之前,我们首先来看看,传统的关系型数据库是怎么运行的。当我们提交了一个很简单的查询:
- SELECT a1,a2,a3 FROM tableA Where condition
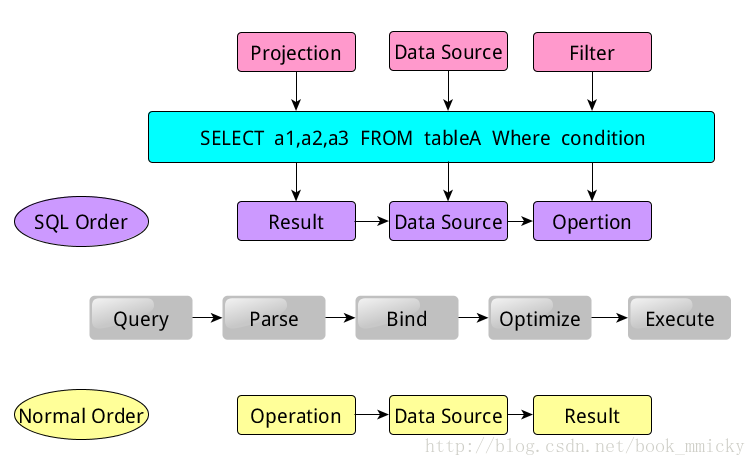
可以看得出来,该语句是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。那么,SQL语句在实际的运行过程中是怎么处理的呢?一般的数据库系统先将读入的SQL语句(Query)先进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等等。这一步就可以判断SQL语句是否规范,不规范就报错,规范就继续下一步过程绑定(Bind),这个过程将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定,如果相关的Projection、Data Source等等都是存在的话,就表示这个SQL语句是可以执行的;而在执行前,一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize),最终执行该计划(Execute),并返回结果。当然在实际的执行过程中,是按Operation-->Data Source-->Result的次序来进行的,和SQL语句的次序刚好相反;在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
以上过程看上去非常简单,但实际上会包含很多复杂的操作细节在里面。而这些操作细节都和Tree有关,在数据库解析(Parse)SQL语句的时候,会将SQL语句转换成一个树型结构来进行处理,如下面一个查询,会形成一个含有多个节点(TreeNode)的Tree,然后在后续的处理过程中对该Tree进行一系列的操作。
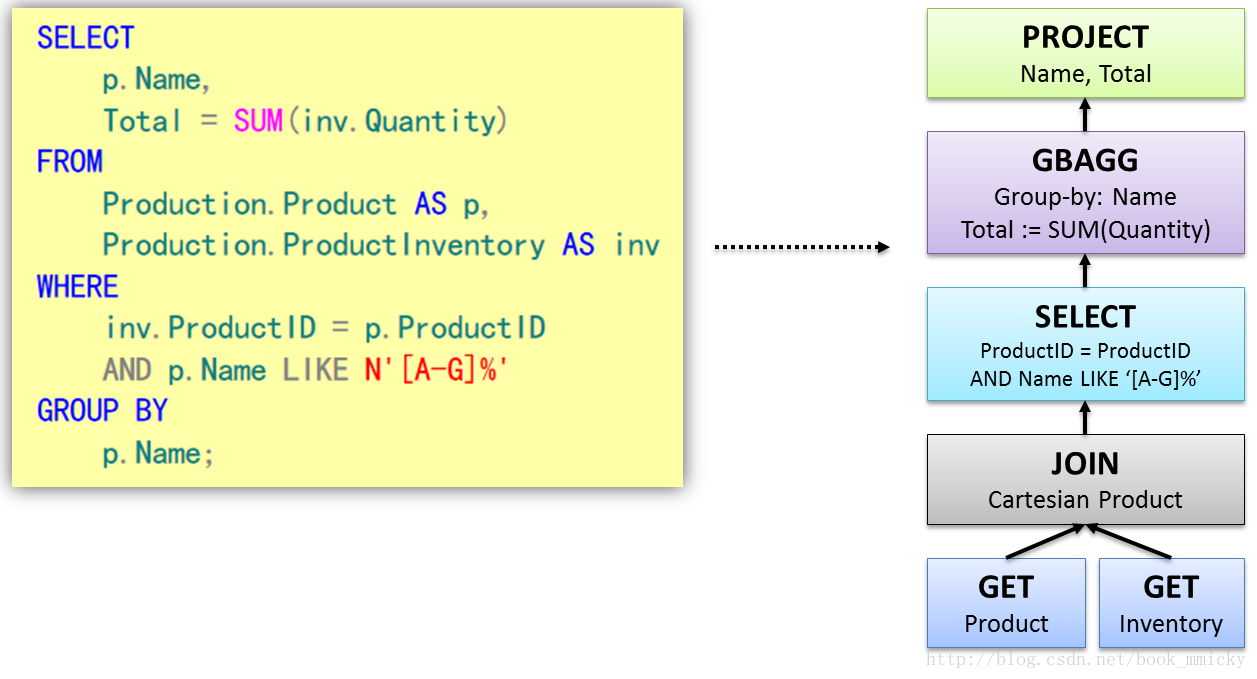
下图给出了对Tree的一些可能的操作细节,对于Tree的处理过程中所涉及更多的细节,可以查看相关的数据库论文。

1:Tree和Rule
sparkSQL对SQL语句的处理和关系型数据库对SQL语句的处理采用了类似的方法,首先会将SQL语句进行解析(Parse),然后形成一个Tree,在后续的如绑定、优化等处理过程都是对Tree的操作,而操作的方法是采用Rule,通过模式匹配,对不同类型的节点采用不同的操作。
A:Tree
- Tree的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/trees
- Logical Plans、Expressions、Physical Operators都可以使用Tree表示
- Tree的具体操作是通过TreeNode来实现的
- sparkSQL定义了catalyst.trees的日志,通过这个日志可以形象的表示出树的结构
- TreeNode可以使用scala的集合操作方法(如foreach, map, flatMap, collect等)进行操作
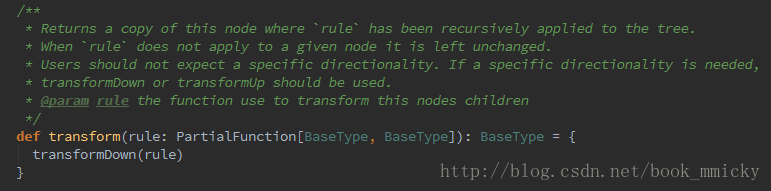
- 有了TreeNode,通过Tree中各个TreeNode之间的关系,可以对Tree进行遍历操作,如使用transformDown、transformUp将Rule应用到给定的树段,然后用结果替代旧的树段;也可以使用transformChildrenDown、transformChildrenUp对一个给定的节点进行操作,通过迭代将Rule应用到该节点以及子节点。
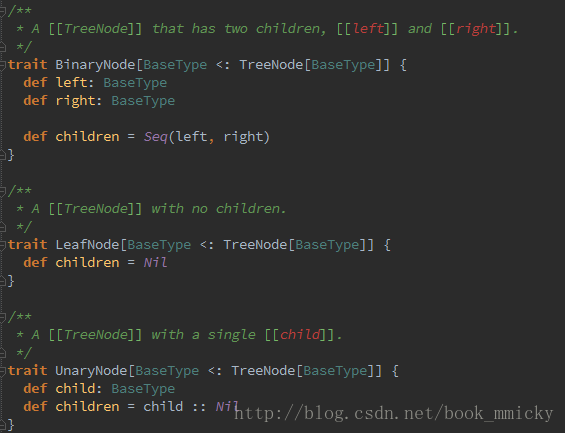
- TreeNode可以细分成三种类型的Node:
- UnaryNode 一元节点,即只有一个子节点。如Limit、Filter操作
- BinaryNode 二元节点,即有左右子节点的二叉节点。如Jion、Union操作
- LeafNode 叶子节点,没有子节点的节点。主要用户命令类操作,如SetCommand
B:Rule
- Rule的相关代码定义在sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/rules
- Rule在sparkSQL的Analyzer、Optimizer、SparkPlan等各个组件中都有应用到
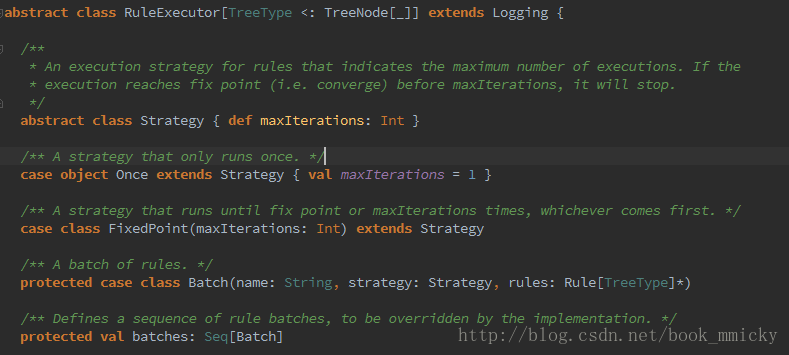
- Rule是一个抽象类,具体的Rule实现是通过RuleExecutor完成
- Rule通过定义batch和batchs,可以简便的、模块化地对Tree进行transform操作
- Rule通过定义Once和FixedPoint,可以对Tree进行一次操作或多次操作(如对某些Tree进行多次迭代操作的时候,达到FixedPoint次数迭代或达到前后两次的树结构没变化才停止操作,具体参看RuleExecutor.apply)
拿个简单的例子,在处理由解析器(SqlParse)生成的LogicPlan Tree的时候,在Analyzer中就定义了多种Rules应用到LogicPlan Tree上。
应用示意图:
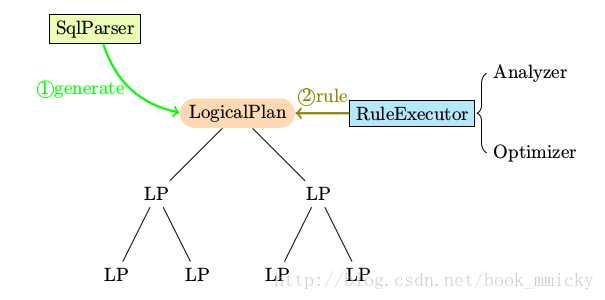
Analyzer中使用的Rules,定义了batches,由多个batch构成,如MultiInstanceRelations、Resolution、Check Analysis、AnalysisOperators等构成;每个batch又有不同的rule构成,如Resolution由ResolveReferences 、ResolveRelations、ResolveSortReferences 、NewRelationInstances等构成;每个rule又有自己相对应的处理函数,可以具体参看Analyzer中的ResolveReferences 、ResolveRelations、ResolveSortReferences 、NewRelationInstances函数;同时要注意的是,不同的rule应用次数是不同的:如CaseInsensitiveAttributeReferences这个batch中rule只应用了一次(Once),而Resolution这个batch中的rule应用了多次(fixedPoint = FixedPoint(100),也就是说最多应用100次,除非前后迭代结果一致退出)。
在整个sql语句的处理过程中,Tree和Rule相互配合,完成了解析、绑定(在sparkSQL中称为Analysis)、优化、物理计划等过程,最终生成可以执行的物理计划。
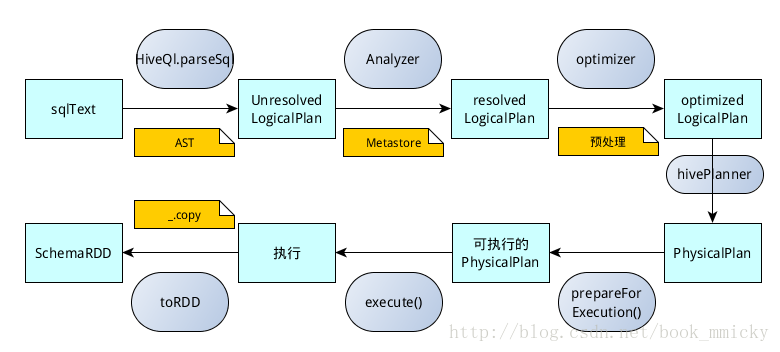
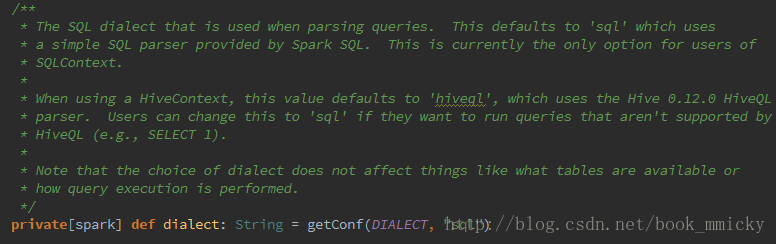
知道了sparkSQL的各个过程的基本处理方式,下面来看看sparkSQL的运行过程。sparkSQL有两个分支,sqlContext和hivecontext,sqlContext现在只支持sql语法解析器(SQL-92语法);hiveContext现在支持sql语法解析器和hivesql语法解析器,默认为hivesql语法解析器,用户可以通过配置切换成sql语法解析器,来运行hiveql不支持的语法,如select 1。关于sqlContext和hiveContext的具体应用请参看第六部分。
2:sqlContext的运行过程
sqlContext是使用sqlContext.sql(sqlText)来提交用户sql语句:
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
- def sql(sqlText: String): SchemaRDD = {
- if (dialect == "sql") {
- new SchemaRDD(this, parseSql(sqlText)) //parseSql(sqlText)对sql语句进行语法解析
- } else {
- sys.error(s"Unsupported SQL dialect: $dialect")
- }
- }
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
- protected[sql] val parser = new catalyst.SqlParser
- protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql)
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SchemaRDD.scala */
- class SchemaRDD(
- @transient val sqlContext: SQLContext,
- @transient val baseLogicalPlan: LogicalPlan)
- extends RDD[Row](sqlContext.sparkContext, Nil) with SchemaRDDLike
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SchemaRDDLike.scala */
- private[sql] trait SchemaRDDLike {
- @transient val sqlContext: SQLContext
- @transient val baseLogicalPlan: LogicalPlan
- private[sql] def baseSchemaRDD: SchemaRDD
- lazy val queryExecution = sqlContext.executePlan(baseLogicalPlan)
sqlContext.executePlan做了什么呢?它调用了
QueryExecution类
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
- protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
- new this.QueryExecution { val logical = plan }
QueryExecution类的定义:
- /**源自sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */
- protected abstract class QueryExecution {
- def logical: LogicalPlan
- //对Unresolved LogicalPlan进行analyzer,生成resolved LogicalPlan
- lazy val analyzed = ExtractPythonUdfs(analyzer(logical))
- //对resolved LogicalPlan进行optimizer,生成optimized LogicalPlan
- lazy val optimizedPlan = optimizer(analyzed)
- // 将optimized LogicalPlan转换成PhysicalPlan
- lazy val sparkPlan = {
- SparkPlan.currentContext.set(self)
- planner(optimizedPlan).next()
- }
- // PhysicalPlan执行前的准备工作,生成可执行的物理计划
- lazy val executedPlan: SparkPlan = prepareForExecution(sparkPlan)
- //执行可执行物理计划
- lazy val toRdd: RDD[Row] = executedPlan.execute()
- ......
- }
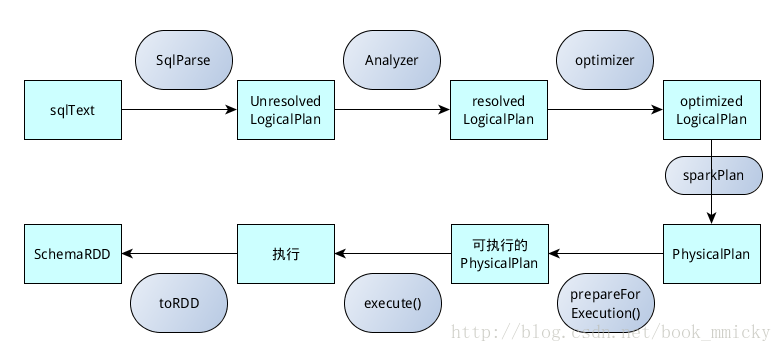
- SQL语句经过SqlParse解析成UnresolvedLogicalPlan;
- 使用analyzer结合数据数据字典(catalog)进行绑定,生成resolvedLogicalPlan;
- 使用optimizer对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan;
- 使用SparkPlan将LogicalPlan转换成PhysicalPlan;
- 使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
- 使用execute()执行可执行物理计划;
- 生成SchemaRDD。
在整个运行过程中涉及到多个sparkSQL的组件,如SqlParse、
analyzer、
optimizer、
SparkPlan等等,其功能和
实现在下一章节中详解。
3:hiveContext的运行过程
在分布式系统中,由于历史原因,很多数据已经定义了hive的元数据,通过这些hive元数据,sparkSQL使用hiveContext很容易实现对这些数据的访问。值得注意的是hiveContext继承自sqlContext,所以在hiveContext的的运行过程中除了override的函数和变量,可以使用和sqlContext一样的函数和变量。
从sparkSQL1.1开始,hiveContext使用hiveContext.sql(sqlText)来提交用户sql语句进行查询:
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- override def sql(sqlText: String): SchemaRDD = {
- // 使用spark.sql.dialect定义采用的语法解析器
- if (dialect == "sql") {
- super.sql(sqlText) //如果使用sql解析器,则使用sqlContext的sql方法
- } else if (dialect == "hiveql") { //如果使用和hiveql解析器,则使用HiveQl.parseSql
- new SchemaRDD(this, HiveQl.parseSql(sqlText))
- } else {
- sys.error(s"Unsupported SQL dialect: $dialect. Try 'sql' or 'hiveql'")
- }
- }
- /**源自src/main/scala/org/apache/spark/sql/hive/HiveQl.scala */
- /** Returns a LogicalPlan for a given HiveQL string. */
- def parseSql(sql: String): LogicalPlan = {
- try {
- if (条件) {
- //非hive命令的处理,如set、cache table、add jar等直接转化成command类型的LogicalPlan
- .....
- } else {
- val tree = getAst(sql)
- if (nativeCommands contains tree.getText) {
- NativeCommand(sql)
- } else {
- nodeToPlan(tree) match {
- case NativePlaceholder => NativeCommand(sql)
- case other => other
- }
- }
- }
- } catch {
- //异常处理
- ......
- }
- }
- 首先考虑一些非hive语句的处理,这些命令属于sparkSQL本身的命令语句,如设置sparkSQL运行参数的set命令、cache table、add jar等,将这些语句转换成command类型的LogicalPlan;
- 如果是hive语句,则调用getAst(sql)使用hive的ParseUtils将该语句先解析成AST树,然后根据AST树中的关键字进行转换:类似命令型的语句、DDL类型的语句转换成command类型的LogicalPlan;其他的转换通过nodeToPlan转换成LogicalPlan。
- /**源自src/main/scala/org/apache/spark/sql/hive/HiveQl.scala */
- /** * Returns the AST for the given SQL string. */
- def getAst(sql: String): ASTNode = ParseUtils.findRootNonNullToken((new ParseDriver).parse(sql))
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- override protected[sql] def executePlan(plan: LogicalPlan): this.QueryExecution =
- new this.QueryExecution { val logical = plan }
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- protected[sql] abstract class QueryExecution extends super.QueryExecution {
- // TODO: Create mixin for the analyzer instead of overriding things here.
- override lazy val optimizedPlan =
- optimizer(ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed))))
- override lazy val toRdd: RDD[Row] = executedPlan.execute().map(_.copy())
- ......
- }
所以在hiveContext的运行过程基本和sqlContext一致,除了override的catalog、functionRegistry、analyzer、planner、optimizedPlan、toRdd。
hiveContext的catalog,是指向 Hive Metastore:
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- /* A catalyst metadata catalog that points to the Hive Metastore. */
- @transient
- override protected[sql] lazy val catalog = new HiveMetastoreCatalog(this) with OverrideCatalog {
- override def lookupRelation(
- databaseName: Option[String],
- tableName: String,
- alias: Option[String] = None): LogicalPlan = {
- LowerCaseSchema(super.lookupRelation(databaseName, tableName, alias))
- }
- }
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- /* An analyzer that uses the Hive metastore. */
- @transient
- override protected[sql] lazy val analyzer =
- new Analyzer(catalog, functionRegistry, caseSensitive = false)
hiveContext的planner,使用新定义的hivePlanner:
- /**源自sql/hive/src/main/scala/org/apache/spark/sql/hive/HiveContext.scala */
- @transient
- override protected[sql] val planner = hivePlanner
所以hiveContext总的一个过程如下图所示:
- SQL语句经过HiveQl.parseSql解析成Unresolved LogicalPlan,在这个解析过程中对hiveql语句使用getAst()获取AST树,然后再进行解析;
- 使用analyzer结合数据hive源数据Metastore(新的catalog)进行绑定,生成resolved LogicalPlan;
- 使用optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan,优化前使用了ExtractPythonUdfs(catalog.PreInsertionCasts(catalog.CreateTables(analyzed)))进行预处理;
- 使用hivePlanner将LogicalPlan转换成PhysicalPlan;
- 使用prepareForExecution()将PhysicalPlan转换成可执行物理计划;
- 使用execute()执行可执行物理计划;
- 执行后,使用map(_.copy)将结果导入SchemaRDD。
4:catalyst优化器
sparkSQL1.1总体上由四个模块组成:core、catalyst、hive、hive-Thriftserver:
- core处理数据的输入输出,从不同的数据源获取数据(RDD、Parquet、json等),将查询结果输出成schemaRDD;
- catalyst处理查询语句的整个处理过程,包括解析、绑定、优化、物理计划等,说其是优化器,还不如说是查询引擎;
- hive对hive数据的处理
- hive-ThriftServer提供CLI和JDBC/ODBC接口
在这四个模块中,catalyst处于最核心的部分,其性能优劣将影响整体的性能。由于发展时间尚短,还有很多不足的地方,但其插件式的设计,为未来的发展留下了很大的空间。下面是catalyst的一个设计图:
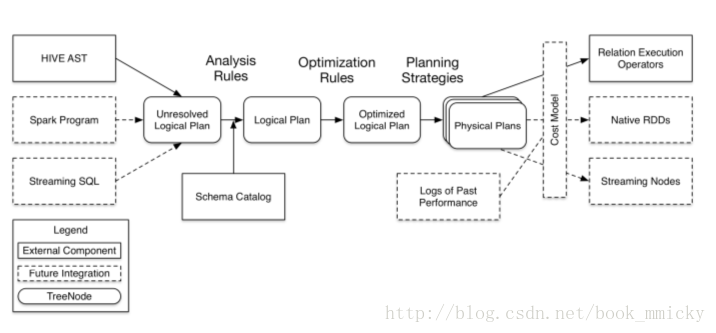
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
- sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
- Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和数据元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
- optimizer对resolved LogicalPlan进行优化,生成optimized LogicalPlan;
- Planner将LogicalPlan转换成PhysicalPlan;
- CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划
这些组件的基本实现方法:
- 先将sql语句通过解析生成Tree,然后在不同阶段使用不同的Rule应用到Tree上,通过转换完成各个组件的功能。
- Analyzer使用Analysis Rules,配合数据元数据(如hive metastore、Schema catalog),完善Unresolved LogicalPlan的属性而转换成resolved LogicalPlan;
- optimizer使用Optimization Rules,对resolved LogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan;
- Planner使用Planning Strategies,对optimized LogicalPlan
关于本篇中涉及到的相关概念和组件在下篇再详细介绍。
三:sparkSQL组件之解析
上篇在总体上介绍了sparkSQL的运行架构及其基本实现方法(Tree和Rule的配合),也大致介绍了sparkSQL中涉及到的各个概念和组件。本篇将详细地介绍一下关键的一些概念和组件,由于hiveContext继承自sqlContext,关键的概念和组件类似,只不过后者针对hive的特性做了一些修正和重写,所以本篇就只介绍sqlContext的- 概念:
- LogicalPlan
- 组件:
- SqlParser
- Analyzer
- Optimizer
- Planner
1:LogicalPlan
在sparkSQL的运行架构中,LogicalPlan贯穿了大部分的过程,其中catalyst中的SqlParser、Analyzer、Optimizer都要对LogicalPlan进行操作。LogicalPlan的定义如下:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">abstract class LogicalPlan extends QueryPlan[LogicalPlan] {
self: Product =>
case class Statistics(
sizeInBytes: BigInt
)
lazy val statistics: Statistics = {
if (children.size == 0) {
throw new UnsupportedOperationException(s"LeafNode $nodeName must implement statistics.")
}
Statistics(
sizeInBytes = children.map(_.statistics).map(_.sizeInBytes).product)
}
/**
* Returns the set of attributes that this node takes as
* input from its children.
*/
lazy val inputSet: AttributeSet = AttributeSet(children.flatMap(_.output))
/**
* Returns true if this expression and all its children have been resolved to a specific schema
* and false if it is still contains any unresolved placeholders. Implementations of LogicalPlan
* can override this (e.g.
* [[org.apache.spark.sql.catalyst.analysis.UnresolvedRelation UnresolvedRelation]]
* should return `false`).
*/
lazy val resolved: Boolean = !expressions.exists(!_.resolved) && childrenResolved
/**
* Returns true if all its children of this query plan have been resolved.
*/
def childrenResolved: Boolean = !children.exists(!_.resolved)
/**
* Optionally resolves the given string to a [[NamedExpression]] using the input from all child
* nodes of this LogicalPlan. The attribute is expressed as
* as string in the following form: `[scope].AttributeName.[nested].[fields]...`.
*/
def resolveChildren(name: String): Option[NamedExpression] =
resolve(name, children.flatMap(_.output))
/**
* Optionally resolves the given string to a [[NamedExpression]] based on the output of this
* LogicalPlan. The attribute is expressed as string in the following form:
* `[scope].AttributeName.[nested].[fields]...`.
*/
def resolve(name: String): Option[NamedExpression] =
resolve(name, output)
/** Performs attribute resolution given a name and a sequence of possible attributes. */
protected def resolve(name: String, input: Seq[Attribute]): Option[NamedExpression] = {
val parts = name.split("\\.")
val options = input.flatMap { option =>
val remainingParts =
if (option.qualifiers.contains(parts.head) && parts.size > 1) parts.drop(1) else parts
if (option.name == remainingParts.head) (option, remainingParts.tail.toList) :: Nil else Nil
}
options.distinct match {
case Seq((a, Nil)) => Some(a) // One match, no nested fields, use it.
// One match, but we also need to extract the requested nested field.
case Seq((a, nestedFields)) =>
a.dataType match {
case StructType(fields) =>
Some(Alias(nestedFields.foldLeft(a: Expression)(GetField), nestedFields.last)())
case _ => None // Don't know how to resolve these field references
}
case Seq() => None // No matches.
case ambiguousReferences =>
throw new TreeNodeException(
this, s"Ambiguous references to $name: ${ambiguousReferences.mkString(",")}")
}
}
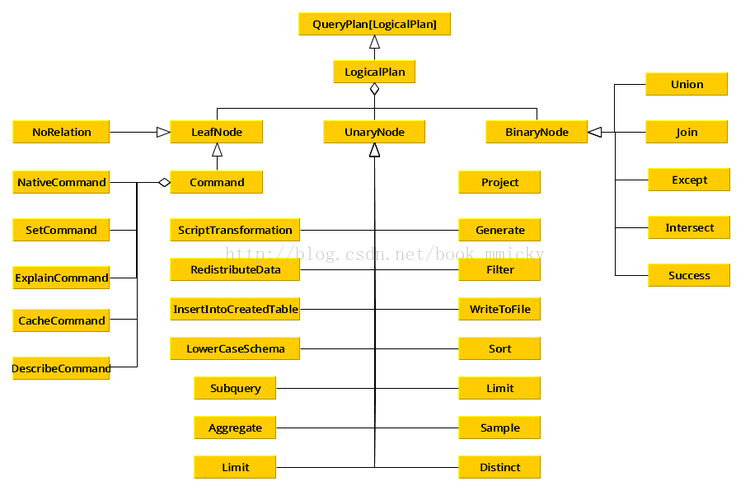
}</p>在LogicalPlan里维护者一套统计数据和属性数据,也提供了解析方法。同时延伸了三种类型的LogicalPlan:
- LeafNode:对应于trees.LeafNode的LogicalPlan
- UnaryNode:对应于trees.UnaryNode的LogicalPlan
- BinaryNode:对应于trees.BinaryNode的LogicalPlan
而对于SQL语句解析时,会调用和SQL匹配的操作方法来进行解析;这些操作分四大类,最终生成LeafNode、UnaryNode、BinaryNode中的一种:
- basicOperators:一些数据基本操作,如Ioin、Union、Filter、Project、Sort
- commands:一些命令操作,如SetCommand、CacheCommand
- partitioning:一些分区操作,如RedistributeData
- ScriptTransformation:对脚本的处理,如ScriptTransformation
- LogicalPlan类的总体架构如下所示
2:SqlParser
SqlParser的功能就是将SQL语句解析成Unresolved LogicalPlan。现阶段的SqlParser语法解析功能比较简单,支持的语法比较有限。其解析过程中有两个关键组件和一个关键函数:
- 词法读入器SqlLexical,其作用就是将输入的SQL语句进行扫描、去空、去注释、校验、分词等动作。
- SQL语法表达式query,其作用定义SQL语法表达式,同时也定义了SQL语法表达式的具体实现,即将不同的表达式生成不同sparkSQL的Unresolved LogicalPlan。
- 函数phrase(),上面个两个组件通过调用phrase(query)(new lexical.Scanner(input)),完成对SQL语句的解析;在解析过程中,SqlLexical一边读入,一边解析,如果碰上生成符合SQL语法的表达式时,就调用相应SQL语法表达式的具体实现函数,将SQL语句解析成Unresolved LogicalPlan。
下面看看sparkSQL的整个解析过程和相关组件:
A:解析过程
首先,在sqlContext中使用下面代码调用catalyst.SqlParser:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"><span style="white-space: normal;">/*源自 sql/core/src/main/scala/org/apache/spark/sql/SQLContext.scala */</span></span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"><span style="white-space: normal;"> protected[sql] val parser = new catalyst.SqlParser</span></span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"><span style="white-space: normal;"> protected[sql] def parseSql(sql: String): LogicalPlan = parser(sql)</span></span></p>然后,直接在SqlParser的apply方法中对输入的SQL语句进行解析,解析功能的核心代码就是:
phrase(query)(new lexical.Scanner(input))
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">class SqlParser extends StandardTokenParsers with PackratParsers {
def apply(input: String): LogicalPlan = {
if (input.trim.toLowerCase.startsWith("set")) {
//set设置项的处理</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> ......
} else {
<span style="color: rgb(255, 0, 0);">phrase(query)(new lexical.Scanner(input))</span> match {
case Success(r, x) => r
case x => sys.error(x.toString)
}
}
}</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">......</p>
可以看得出来,该语句就是调用
phrase()函数,使用SQL语法表达式query,对词法读入器lexical读入的SQL语句进行解析,其中词法读入器lexical通过重写语句:override val lexical = new SqlLexical(reservedWords) 调用扩展了功能的SqlLexical。其定义:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</span> </p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">// Use reflection to find the reserved words defined in this class.
protected val reservedWords =
this.getClass
.getMethods
.filter(_.getReturnType == classOf[Keyword])
.map(_.invoke(this).asInstanceOf[Keyword].str)
override val lexical = new SqlLexical(reservedWords)</p>
为了加深对SQL语句解析过程的理解,让我们看看下面这个简单数字表达式解析过程来说明:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">import scala.util.parsing.combinator.PackratParsers
import scala.util.parsing.combinator.syntactical._
object mylexical extends StandardTokenParsers with PackratParsers {
//定义分割符
lexical.delimiters ++= List(".", ";", "+", "-", "*")
//定义表达式,支持加,减,乘
lazy val expr: PackratParser[Int] = plus | minus | multi
//加法表示式的实现
lazy val plus: PackratParser[Int] = num ~ "+" ~ num ^^ { case n1 ~ "+" ~ n2 => n1.toInt + n2.toInt}
//减法表达式的实现
lazy val minus: PackratParser[Int] = num ~ "-" ~ num ^^ { case n1 ~ "-" ~ n2 => n1.toInt - n2.toInt}
//乘法表达式的实现
lazy val multi: PackratParser[Int] = num ~ "*" ~ num ^^ { case n1 ~ "*" ~ n2 => n1.toInt * n2.toInt}
lazy val num = numericLit
def parse(input: String) = {</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> //定义词法读入器myread,并将扫描头放置在input的首位</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> val myread = new PackratReader(new lexical.Scanner(input))
print("处理表达式 " + input)
phrase(expr)(myread) match {
case Success(result, _) => println(" Success!"); println(result); Some(result)
case n => println(n); println("Err!"); None
}
}
def main(args: Array[String]) {
val prg = "6 * 3" :: "24-/*aaa*/4" :: "a+5" :: "21/3" :: Nil
prg.map(parse)
}
}</p>运行结果:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">处理表达式 6 * 3 Success! //lexical对空格进行了处理,得到6*3
18 //6*3符合乘法表达式,调用n1.toInt * n2.toInt,得到结果并返回</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">处理表达式 24-/*aaa*/4 Success! //lexical对注释进行了处理,得到20-4
20 //20-4符合减法表达式,调用n1.toInt - n2.toInt,得到结果并返回
处理表达式 a+5[1.1] failure: number expected
//lexical在解析到a,发现不是整数型,故报错误位置和内容
a+5
^
Err!
处理表达式 21/3[1.3] failure: ``*'' expected but ErrorToken(illegal character) found
//lexical在解析到/,发现不是分割符,故报错误位置和内容
21/3
^
Err!</p>
在运行的时候,首先对表达式 6 * 3 进行解析,词法读入器myread将扫描头置于6的位置;当phrase()函数使用定义好的数字表达式expr处理6 * 3的时候,6 * 3每读入一个词法,就和expr进行匹配,如读入6*和expr进行匹配,先匹配表达式plus,*和+匹配不上;就继续匹配表达式minus,*和-匹配不上;就继续匹配表达式multi,这次匹配上了,等读入3的时候,因为3是num类型,就调用调用n1.toInt * n2.toInt进行计算。
注意,这里的expr、plus、minus、multi、num都是表达式,|、~、^^是复合因子,表达式和复合因子可以组成一个新的表达式,如plus(num ~ "+" ~ num ^^ { case n1 ~ "+" ~ n2 => n1.toInt + n2.toInt})就是一个由num、+、num、函数构成的复合表达式;而expr(plus | minus | multi)是由plus、minus、multi构成的复合表达式;复合因子的含义定义在类scala/util/parsing/combinator/Parsers.scala,下面是几个常用的复合因子:
- p ~ q p成功,才会q;放回p,q的结果
- p ~> q p成功,才会q,返回q的结果
- p <~ q p成功,才会q,返回p的结果
- p | q p失败则q,返回第一个成功的结果
- p ^^ f 如果p成功,将函数f应用到p的结果上
- p ^? f 如果p成功,如果函数f可以应用到p的结果上的话,就将p的结果用f进行转换
针对上面的6 * 3使用的是multi表达式(num ~ "*" ~ num ^^ { case n1 ~ "*" ~ n2 => n1.toInt * n2.toInt}),其含义就是:num后跟*再跟num,如果满足就将使用函数n1.toInt * n2.toInt。
到这里为止,大家应该明白整个解析过程了吧,
 。SqlParser的原理和这个表达式解析器使用了一样的原理,只不过是定义的SQL语法表达式query复杂一些,使用的词法读入器更丰富一些而已。下面分别介绍一下相关组件SqlParser、SqlLexical、query。
。SqlParser的原理和这个表达式解析器使用了一样的原理,只不过是定义的SQL语法表达式query复杂一些,使用的词法读入器更丰富一些而已。下面分别介绍一下相关组件SqlParser、SqlLexical、query。
。SqlParser的原理和这个表达式解析器使用了一样的原理,只不过是定义的SQL语法表达式query复杂一些,使用的词法读入器更丰富一些而已。下面分别介绍一下相关组件SqlParser、SqlLexical、query。
B:SqlParser
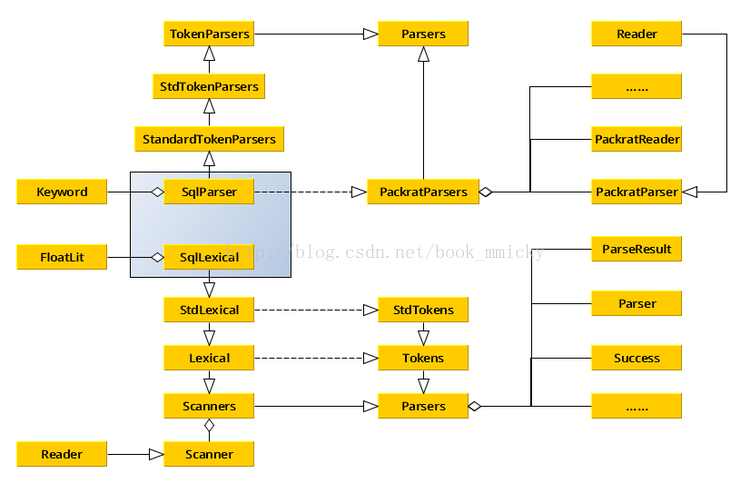
首先,看看SqlParser的UML图:
其次,看看SqlParser的定义,SqlParser继承自类StandardTokenParsers和特质PackratParsers:
其中,PackratParsers:
- 扩展了scala.util.parsing.combinator.Parsers所提供的parser,做了内存化处理;
- Packrat解析器实现了回溯解析和递归下降解析,具有无限先行和线性分析时的优势。同时,也支持左递归词法解析。
- 从Parsers中继承出来的class或trait都可以使用PackratParsers,如:object MyGrammar extends StandardTokenParsers with PackratParsers;
- PackratParsers将分析结果进行缓存,因此,PackratsParsers需要PackratReader(内存化处理的Reader)作为输入,程序员可以手工创建PackratReader,如production(new PackratReader(new lexical.Scanner(input))),更多的细节参见scala库中/scala/util/parsing/combinator/PackratParsers.scala文件。
StandardTokenParsers是最终继承自Parsers
- 增加了词法的处理能力(Parsers是字符处理),在StdTokenParsers中定义了四种基本词法:
- keyword tokens
- numeric literal tokens
- string literal tokens
- identifier tokens
- 定义了一个词法读入器lexical,可以进行词法读入
SqlParser在进行解析SQL语句的时候是调用了PackratParsers中phrase():
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 scala/util/parsing/combinator/PackratParsers.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> /**
* A parser generator delimiting whole phrases (i.e. programs).
*
* Overridden to make sure any input passed to the argument parser
* is wrapped in a `PackratReader`.
*/
override def phrase[T](p: Parser[T]) = {
val q = super.phrase(p)
new PackratParser[T] {
def apply(in: Input) = in match {
case in: PackratReader[_] => q(in)
case in => q(new PackratReader(in))
}
}
}</p>在解析过程中,一般会定义多个表达式,如上面例子中的plus | minus | multi,一旦前一个表达式不能解析的话,就会调用下一个表达式进行解析:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/</span>*源自 scala/util/parsing/combinator/Parsers.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> def append[U >: T](p0: => Parser[U]): Parser[U] = { lazy val p = p0 // lazy argument
Parser{ in => this(in) append p(in)}
}</p>表达式解析正确后,具体的实现函数是在
PackratParsers中完成:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 scala/util/parsing/combinator/PackratParsers.scala */</span> </p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> def memo[T](p: super.Parser[T]): PackratParser[T] = {
new PackratParser[T] {
def apply(in: Input) = {
val inMem = in.asInstanceOf[PackratReader[Elem]]
//look in the global cache if in a recursion
val m = recall(p, inMem)
m match {
//nothing has been done due to recall
case None =>
val base = LR(Failure("Base Failure",in), p, None)
inMem.lrStack = base::inMem.lrStack
//cache base result
inMem.updateCacheAndGet(p,MemoEntry(Left(base)))
//parse the input
val tempRes = p(in)
//the base variable has passed equality tests with the cache
inMem.lrStack = inMem.lrStack.tail
//check whether base has changed, if yes, we will have a head
base.head match {
case None =>
/*simple result*/
inMem.updateCacheAndGet(p,MemoEntry(Right(tempRes)))
tempRes
case s@Some(_) =>
/*non simple result*/
base.seed = tempRes
//the base variable has passed equality tests with the cache
val res = lrAnswer(p, inMem, base)
res
}
case Some(mEntry) => {
//entry found in cache
mEntry match {
case MemoEntry(Left(recDetect)) => {
setupLR(p, inMem, recDetect)
//all setupLR does is change the heads of the recursions, so the seed will stay the same
recDetect match {case LR(seed, _, _) => seed.asInstanceOf[ParseResult[T]]}
}
case MemoEntry(Right(res: ParseResult[_])) => res.asInstanceOf[ParseResult[T]]
}
}
}
}
}
}</p>StandardTokenParsers增加了词法处理能力,SqlParers定义了大量的关键字,重写了词法读入器,将这些关键字应用于词法读入器。
C:SqlLexical
词法读入器SqlLexical扩展了StdLexical的功能,首先增加了大量的关键字:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"> </span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> protected val ALL = Keyword("ALL")
protected val AND = Keyword("AND")
protected val AS = Keyword("AS")
protected val ASC = Keyword("ASC")
......
protected val SUBSTR = Keyword("SUBSTR")
protected val SUBSTRING = Keyword("SUBSTRING")</p>其次丰富了分隔符、词法处理、空格注释处理:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"> </span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">delimiters += (
"@", "*", "+", "-", "<", "=", "<>", "!=", "<=", ">=", ">", "/", "(", ")",
",", ";", "%", "{", "}", ":", "[", "]"
)
override lazy val token: Parser[Token] = (
identChar ~ rep( identChar | digit ) ^^
{ case first ~ rest => processIdent(first :: rest mkString "") }
| rep1(digit) ~ opt('.' ~> rep(digit)) ^^ {
case i ~ None => NumericLit(i mkString "")
case i ~ Some(d) => FloatLit(i.mkString("") + "." + d.mkString(""))
}
| '\'' ~ rep( chrExcept('\'', '\n', EofCh) ) ~ '\'' ^^
{ case '\'' ~ chars ~ '\'' => StringLit(chars mkString "") }
| '\"' ~ rep( chrExcept('\"', '\n', EofCh) ) ~ '\"' ^^
{ case '\"' ~ chars ~ '\"' => StringLit(chars mkString "") }
| EofCh ^^^ EOF
| '\'' ~> failure("unclosed string literal")
| '\"' ~> failure("unclosed string literal")
| delim
| failure("illegal character")
)
override def identChar = letter | elem('_') | elem('.')
override def whitespace: Parser[Any] = rep(
whitespaceChar
| '/' ~ '*' ~ comment
| '/' ~ '/' ~ rep( chrExcept(EofCh, '\n') )
| '#' ~ rep( chrExcept(EofCh, '\n') )
| '-' ~ '-' ~ rep( chrExcept(EofCh, '\n') )
| '/' ~ '*' ~ failure("unclosed comment")
)</p>最后看看SQL语法表达式query。
D:query
SQL语法表达式支持3种操作:select、insert、cache
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"> </span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">protected lazy val query: Parser[LogicalPlan] = (
select * (
UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) } |
INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) } |
EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)} |
UNION ~ opt(DISTINCT) ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
| insert | cache
)</p>
而这些操作还有具体的定义,如select,这里开始定义了具体的函数,将SQL语句转换成构成
Unresolved LogicalPlan的一些Node:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">/*源自 src/main/scala/org/apache/spark/sql/catalyst/SqlParser.scala */</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;"> </span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> protected lazy val select: Parser[LogicalPlan] =
SELECT ~> opt(DISTINCT) ~ projections ~
opt(from) ~ opt(filter) ~
opt(grouping) ~
opt(having) ~
opt(orderBy) ~
opt(limit) <~ opt(";") ^^ {
case d ~ p ~ r ~ f ~ g ~ h ~ o ~ l =>
val base = r.getOrElse(NoRelation)
val withFilter = f.map(f => Filter(f, base)).getOrElse(base)
val withProjection =
g.map {g =>
Aggregate(assignAliases(g), assignAliases(p), withFilter)
}.getOrElse(Project(assignAliases(p), withFilter))
val withDistinct = d.map(_ => Distinct(withProjection)).getOrElse(withProjection)
val withHaving = h.map(h => Filter(h, withDistinct)).getOrElse(withDistinct)
val withOrder = o.map(o => Sort(o, withHaving)).getOrElse(withHaving)
val withLimit = l.map { l => Limit(l, withOrder) }.getOrElse(withOrder)
withLimit
}
</p><div>
</div>
3:Analyzer
Analyzer的功能就是对来自SqlParser的Unresolved LogicalPlan中的UnresolvedAttribute项和UnresolvedRelation项,对照catalog和FunctionRegistry生成Analyzed LogicalPlan
。Analyzer定义了5大类14小类的rule:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 <span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/src/main/scala/org/apache/spark/</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/analysis/Analyzer.scala */</span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> val batches: Seq[Batch] = Seq(
Batch("MultiInstanceRelations", Once,
NewRelationInstances),
Batch("CaseInsensitiveAttributeReferences", Once,
(if (caseSensitive) Nil else LowercaseAttributeReferences :: Nil) : _*),
Batch("Resolution", fixedPoint,
ResolveReferences ::
ResolveRelations ::
ResolveSortReferences ::
NewRelationInstances ::
ImplicitGenerate ::
StarExpansion ::
ResolveFunctions ::
GlobalAggregates ::
UnresolvedHavingClauseAttributes ::
typeCoercionRules :_*),
Batch("Check Analysis", Once,
CheckResolution),
Batch("AnalysisOperators", fixedPoint,
EliminateAnalysisOperators)
)</p>
- MultiInstanceRelations
- NewRelationInstances
- CaseInsensitiveAttributeReferences
- LowercaseAttributeReferences
- Resolution
- ResolveReferences
- ResolveRelations
- ResolveSortReferences
- NewRelationInstances
- ImplicitGenerate
- StarExpansion
- ResolveFunctions
- GlobalAggregates
- UnresolvedHavingClauseAttributes
- typeCoercionRules
- Check Analysis
- CheckResolution
- AnalysisOperators
- EliminateAnalysisOperators
这些rule
都是使用transform对
Unresolved
LogicalPlan进行操作,其中
typeCoercionRules是对HiveQL语义进行处理,在其下面又定义了多个rule:PropagateTypes、ConvertNaNs、WidenTypes、PromoteStrings、BooleanComparisons、BooleanCasts、StringToIntegralCasts、FunctionArgumentConversion、CaseWhenCoercion、Division,同样了这些rule也是使用
transform对
Unresolved
LogicalPlan进行操作。这些rule操作后,使得LogicalPlan的信息变得丰满和易懂。下面拿其中的两个rule来简单介绍一下:
比如rule之
ResolveReferences,最终调用LogicalPlan的resolveChildren对列名给一名字和序号,如name#67之列的,这样保持列的唯一性:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 <span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/src/main/scala/org/apache/spark/</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/analysis/Analyzer.scala */</span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> object ResolveReferences extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transformUp {
case q: LogicalPlan if q.childrenResolved =>
logTrace(s"Attempting to resolve ${q.simpleString}")
q transformExpressions {
case u @ UnresolvedAttribute(name) =>
// Leave unchanged if resolution fails. Hopefully will be resolved next round.
val result = q.resolveChildren(name).getOrElse(u)
logDebug(s"Resolving $u to $result")
result
}
}
}</p> 又比如rule之StarExpansion,其作用就是将Select * Fom tbl中的*展开,赋予列名:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 <span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/src/main/scala/org/apache/spark/</span><span style="font-family: 'Hiragino Sans GB W3', 'Hiragino Sans GB', Arial, Helvetica, simsun, 宋体;">sql/catalyst/analysis/Analyzer.scala */</span></p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;"> object StarExpansion extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
// Wait until children are resolved
case p: LogicalPlan if !p.childrenResolved => p
// If the projection list contains Stars, expand it.
case p @ Project(projectList, child) if containsStar(projectList) =>
Project(
projectList.flatMap {
case s: Star => s.expand(child.output)
case o => o :: Nil
},
child)
case t: ScriptTransformation if containsStar(t.input) =>
t.copy(
input = t.input.flatMap {
case s: Star => s.expand(t.child.output)
case o => o :: Nil
}
)
// If the aggregate function argument contains Stars, expand it.
case a: Aggregate if containsStar(a.aggregateExpressions) =>
a.copy(
aggregateExpressions = a.aggregateExpressions.flatMap {
case s: Star => s.expand(a.child.output)
case o => o :: Nil
}
)
}
/**
* Returns true if `exprs` contains a [[Star]].
*/
protected def containsStar(exprs: Seq[Expression]): Boolean =
exprs.collect { case _: Star => true }.nonEmpty
}
}</p>
4:Optimizer
Optimizer的功能就是将来自Analyzer的Analyzed LogicalPlan进行多种rule优化,生成Optimized LogicalPlan。Optimizer定义了3大类12个小类的优化rule:
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">object Optimizer extends RuleExecutor[LogicalPlan] {
val batches =
Batch("Combine Limits", FixedPoint(100),
CombineLimits) ::
Batch("ConstantFolding", FixedPoint(100),
NullPropagation,
ConstantFolding,
LikeSimplification,
BooleanSimplification,
SimplifyFilters,
SimplifyCasts,
SimplifyCaseConversionExpressions) ::
Batch("Filter Pushdown", FixedPoint(100),
CombineFilters,
PushPredicateThroughProject,
PushPredicateThroughJoin,
ColumnPruning) :: Nil
}</p>
- Combine Limits 合并Limit
- CombineLimits:将两个相邻的limit合为一个
- ConstantFolding 常量叠加
- NullPropagation 空格处理
- ConstantFolding:常量叠加
- LikeSimplification:like表达式简化
- BooleanSimplification:布尔表达式简化
- SimplifyFilters:Filter简化
- SimplifyCasts:Cast简化
- SimplifyCaseConversionExpressions:CASE大小写转化表达式简化
- Filter Pushdown Filter下推
- CombineFilters Filter合并
- PushPredicateThroughProject 通过Project谓词下推
- PushPredicateThroughJoin 通过Join谓词下推
- ColumnPruning 列剪枝
这些优化rule都是使用transform对LogicalPlan进行操作,如合并、删除冗余、简化、剪枝等,是整个LogicalPlan变得更简洁更高效。
比如将两个相邻的limit进行合并,可以使用
CombineLimits。
象sql("select * from (select * from src limit 5)a limit 3 ") 这样一个SQL语句,会将limit 5和limit 3进行合并,只剩一个一个limit 3。
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">object CombineLimits extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case ll @ Limit(le, nl @ Limit(ne, grandChild)) =>
Limit(If(LessThan(ne, le), ne, le), grandChild)
}
}</p>
又比如Null值的处理,可以使用NullPropagation处理。象sql("select count(null) from src where key is not null")这样一个SQL语句会转换成sql("select count(0) from src where key is not null")来处理。
<p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">/*源自 sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/optimizer/Optimizer.scala */</p><p style="margin-top: 0px; margin-bottom: 0px; padding-top: 0px; padding-bottom: 0px;">object NullPropagation extends Rule[LogicalPlan] {
def apply(plan: LogicalPlan): LogicalPlan = plan transform {
case q: LogicalPlan => q transformExpressionsUp {
case e @ Count(Literal(null, _)) => Cast(Literal(0L), e.dataType)
case e @ Sum(Literal(c, _)) if c == 0 => Cast(Literal(0L), e.dataType)
case e @ Average(Literal(c, _)) if c == 0 => Literal(0.0, e.dataType)
case e @ IsNull(c) if !c.nullable => Literal(false, BooleanType)
case e @ IsNotNull(c) if !c.nullable => Literal(true, BooleanType)
case e @ GetItem(Literal(null, _), _) => Literal(null, e.dataType)
case e @ GetItem(_, Literal(null, _)) => Literal(null, e.dataType)
case e @ GetField(Literal(null, _), _) => Literal(null, e.dataType)
case e @ EqualNullSafe(Literal(null, _), r) => IsNull(r)
case e @ EqualNullSafe(l, Literal(null, _)) => IsNull(l)
......
}
}
}</p> 对于具体的优化方法可以使用下一章所介绍的hive/console调试方法进行调试,用户可以使用自定义的优化函数,也可以使用sparkSQL提供的优化函数。使用前先定义一个要优化查询,然后查看一下该查询的Analyzed LogicalPlan,再使用优化函数去优化,将生成的Optimized LogicalPlan和Analyzed LogicalPlan进行比较,就可以看到优化的效果。
四:深入了解sparkSQL运行计划
前面两章花了不少篇幅介绍了SparkSQL的运行过程,很多读者还是觉得其中的概念很抽象,比如Unresolved LogicPlan、LogicPlan、PhysicalPlan是长得什么样子,没点印象,只知道名词,感觉很缥缈。本章就着重介绍一个工具hive/console,来加深读者对sparkSQL的运行计划的理解。
D:启动
在控制台的scala提示符下,输入:help可以获取帮助,输入Tab键会陈列出当前可用的方法、函数、及变量。下图为按Tab键时显示的方法和函数,随着用户不断使用该控制态,用户定义或使用过的变量也会陈列出来。
因为要使用hive0.12的测试数据,所以需要定义两个环境变量:HIVE_HOME和HIVE_DEV_HOME,如果使用hive0.13的话,用户需要更改到相应目录:
2:常用操作
2.5 查看优化后的LogicalPlan
去空格和换行符后保存为/home/mmicky/data/nestjson.json,使用jsonFile读入并注册成表jsonPerson,然后定义一个查询jsonQuery:
从上面可以看出,来自jsonFile、parquetFile、hive数据的物理计划还有有很大区别的。
上面的查询,在Optimized的过程中,将age>=19和age<30这两个Filter合并了,合并成((age>=19) && (age<30))。其实上面还做了一个其他的优化,就是project的下推,子查询使用了表的所有列,而主查询使用了列name,在查询数据的时候子查询优化成只查列name。
在Optimized的过程中,将常量表达式直接累加在一起,用新的列名来表示。

最后,使用自定义优化函数进行优化:

然后,直接用transform将自定义的rule:

该transform在LogicPlan的主查询和子查询的project相同时合并project。
1:hive/console安装
sparkSQL从1.0.0开始提供了一个sparkSQL的调试工具hive/console。该工具是给开发者使用,在编译生成的安装部署包中并没有;该工具需要使用sbt编译运行。要使用该工具,需要具备以下条件:
- spark1.1.0源码
- hive0.12源码并编译
- 配置环境变量
1.1:安装hive/cosole
下面是笔者安装过程:
A:下载spark1.1.0源码,安装在/app/hadoop/spark110_sql目录
B:下载hive0.12源码,安装在/app/hadoop/hive012目录,进入src目录后,使用下面命令进行编译:
- ant clean package -Dhadoop.version=2.2.0 -Dhadoop-0.23.version=2.2.0 -Dhadoop.mr.rev=23
C:配置环境变量文件~/.bashrc后,source ~/.bashrc使环境变量生效。
- export HIVE_HOME=/app/hadoop/hive012/src/build/dist
- export HIVE_DEV_HOME=/app/hadoop/hive012/src
- export HADOOP_HOME=/app/hadoop/hadoop220
切换到spark安装目录/app/hadoop/spark110_sql,运行命令:
- sbt/sbt hive/console
经过一段漫长的sbt编译过程,最后出现如下界面:
1.2:hive/console原理
hive/console的调试原理很简单,就是在scala控制台装载了catalyst中几个关键的class,其中的TestHive预定义了表结构并装载命令,这些数据是hive0.12源码中带有的测试数据,装载这些数据是按需执行的;这些数据位于/app/hadoop/hive012/src/data中,也就是$HIVE_DEV_HOME/data中。
- /*源自 sql/hive/src/main/scala/org/apache/spark/sql/hive/TestHive.scala */
- // The test tables that are defined in the Hive QTestUtil.
- // /itests/util/src/main/java/org/apache/hadoop/hive/ql/QTestUtil.java
- val hiveQTestUtilTables = Seq(
- TestTable("src",
- "CREATE TABLE src (key INT, value STRING)".cmd,
- s"LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv1.txt")}' INTO TABLE src".cmd),
- TestTable("src1",
- "CREATE TABLE src1 (key INT, value STRING)".cmd,
- s"LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv3.txt")}' INTO TABLE src1".cmd),
- TestTable("srcpart", () => {
- runSqlHive(
- "CREATE TABLE srcpart (key INT, value STRING) PARTITIONED BY (ds STRING, hr STRING)")
- for (ds <- Seq("2008-04-08", "2008-04-09"); hr <- Seq("11", "12")) {
- runSqlHive(
- s"""LOAD DATA LOCAL INPATH '${getHiveFile("data/files/kv1.txt")}'
- |OVERWRITE INTO TABLE srcpart PARTITION (ds='$ds',hr='$hr')
- """.stripMargin)
- }
- }),
- ......
- )
- /*源自 sql/hive/src/main/scala/org/apache/spark/sql/hive/TestHive.scala */
- /** The location of the compiled hive distribution */
- lazy val hiveHome = envVarToFile("HIVE_HOME")
- /** The location of the hive source code. */
- lazy val hiveDevHome = envVarToFile("HIVE_DEV_HOME")
另外,如果用户想在hive/console启动的时候,预载更多的class,可以修改spark源码下的 project/SparkBuild.scala文件
- /* 源自 project/SparkBuild.scala */
- object Hive {
- lazy val settings = Seq(
- javaOptions += "-XX:MaxPermSize=1g",
- // Multiple queries rely on the TestHive singleton. See comments there for more details.
- parallelExecution in Test := false,
- // Supporting all SerDes requires us to depend on deprecated APIs, so we turn off the warnings
- // only for this subproject.
- scalacOptions <<= scalacOptions map { currentOpts: Seq[String] =>
- currentOpts.filterNot(_ == "-deprecation")
- },
- initialCommands in console :=
- """
- |import org.apache.spark.sql.catalyst.analysis._
- |import org.apache.spark.sql.catalyst.dsl._
- |import org.apache.spark.sql.catalyst.errors._
- |import org.apache.spark.sql.catalyst.expressions._
- |import org.apache.spark.sql.catalyst.plans.logical._
- |import org.apache.spark.sql.catalyst.rules._
- |import org.apache.spark.sql.catalyst.types._
- |import org.apache.spark.sql.catalyst.util._
- |import org.apache.spark.sql.execution
- |import org.apache.spark.sql.hive._
- |import org.apache.spark.sql.hive.test.TestHive._
- |import org.apache.spark.sql.parquet.ParquetTestData""".stripMargin
- )
- }
下面介绍一下hive/console的常用操作,主要是和运行计划相关的常用操作。在操作前,首先定义一个表people和查询query:
- //在控制台逐行运行
- case class Person(name:String, age:Int, state:String)
- sparkContext.parallelize(Person("Michael",29,"CA")::Person("Andy",30,"NY")::Person("Justin",19,"CA")::Person("Justin",25,"CA")::Nil).registerTempTable("people")
- val query= sql("select * from people")
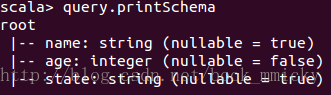
2.1 查看查询的schema
2.2 查看查询的整个运行计划
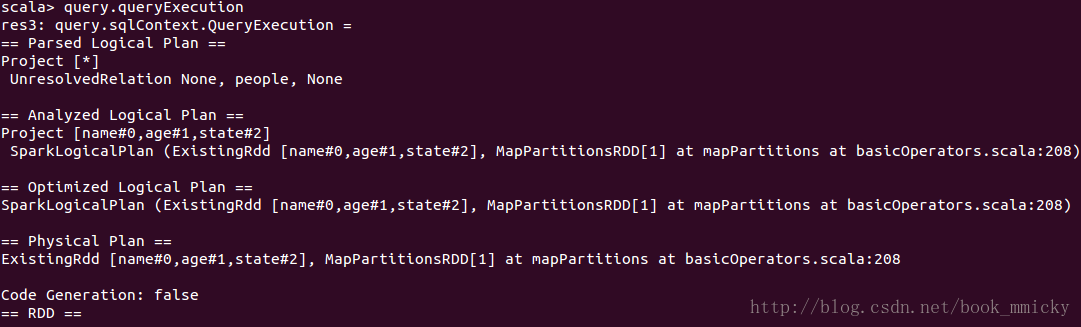
2.3 查看查询的Unresolved LogicalPlan

2.4 查看查询的analyzed LogicalPlan

2.5 查看优化后的LogicalPlan

2.6 查看物理计划

2.7 查看RDD的转换过程

2.8 更多的操作
更多的操作可以通过Tab键陈列出来,也可以参开sparkSQL的API,也可以参看源代码中的方法和函数。
3:不同数据源的运行计划
上面常用操作里介绍了源自RDD的数据,我们都知道,sparkSQL可以源自多个数据源:jsonFile、parquetFile、hive。下面看看这些数据源的schema:
3.1 json文件
json文件支持嵌套表,sparkSQL也可以读入嵌套表,如下面形式的json数据,经修整(去空格和换行符)保存后,可以使用jsonFile读入sparkSQL。
- {
- "fullname": "Sean Kelly",
- "org": "SK Consulting",
- "emailaddrs": [
- {"type": "work", "value": "kelly@seankelly.biz"},
- {"type": "home", "pref": 1, "value": "kelly@seankelly.tv"}
- ],
- "telephones": [
- {"type": "work", "pref": 1, "value": "+1 214 555 1212"},
- {"type": "fax", "value": "+1 214 555 1213"},
- {"type": "mobile", "value": "+1 214 555 1214"}
- ],
- "addresses": [
- {"type": "work", "format": "us",
- "value": "1234 Main StnSpringfield, TX 78080-1216"},
- {"type": "home", "format": "us",
- "value": "5678 Main StnSpringfield, TX 78080-1316"}
- ],
- "urls": [
- {"type": "work", "value": "http://seankelly.biz/"},
- {"type": "home", "value": "http://seankelly.tv/"}
- ]
- }
- jsonFile("/home/mmicky/data/nestjson.json").registerTempTable("jsonPerson")
- val jsonQuery = sql("select * from jsonPerson")
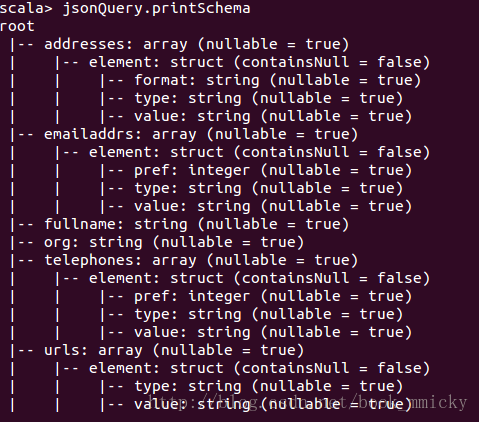
查看jsonQuery的schema:
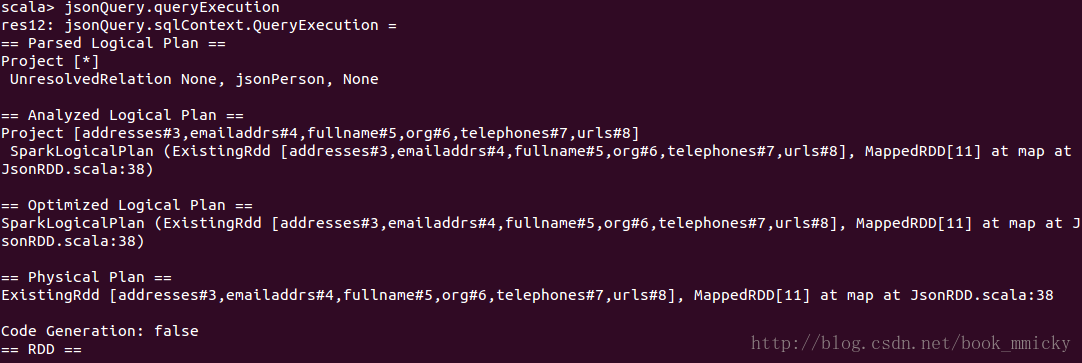
查看jsonQuery的整个运行计划:
3.2 parquet文件
parquet文件读入并注册成表parquetWiki,然后定义一个查询parquetQuery:
- parquetFile("/home/mmicky/data/spark/wiki_parquet").registerTempTable("parquetWiki")
- val parquetQuery = sql("select * from parquetWiki")
查询parquetQuery的schema:
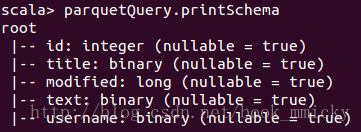
3.3 hive数据
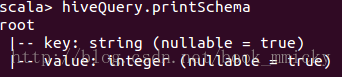
之前说了,TestHive类中已经定义了大量的hive0.12的测试数据的表格式,如src、sales等等,在hive/console里可以直接使用;第一次使用的时候,hive/console会装载一次。下面我们使用sales表看看其schema和整个运行计划。首先定义一个查询hiveQuery:
- val hiveQuery = sql("select * from sales")
查看hiveQuery的schema:
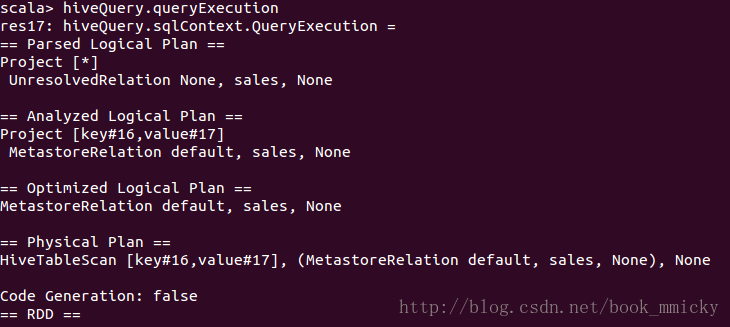
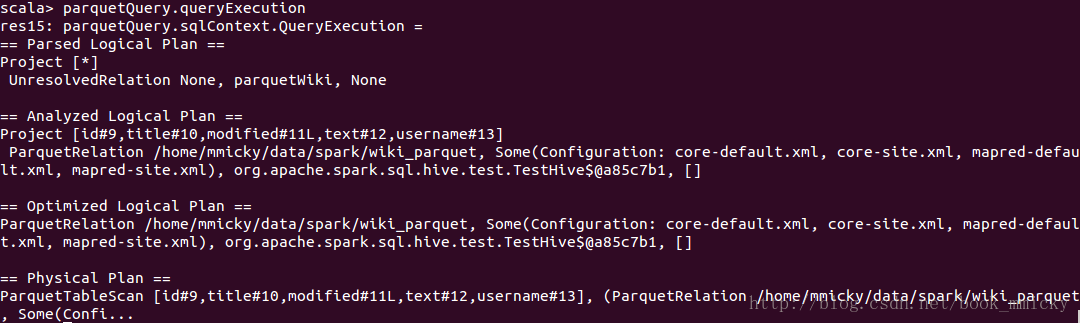
- hiveQuery.queryExecution
从上面可以看出,来自jsonFile、parquetFile、hive数据的物理计划还有有很大区别的。
4:不同查询的运行计划
为了加深理解,我们列几个常用查询的运行计划和RDD转换过程。
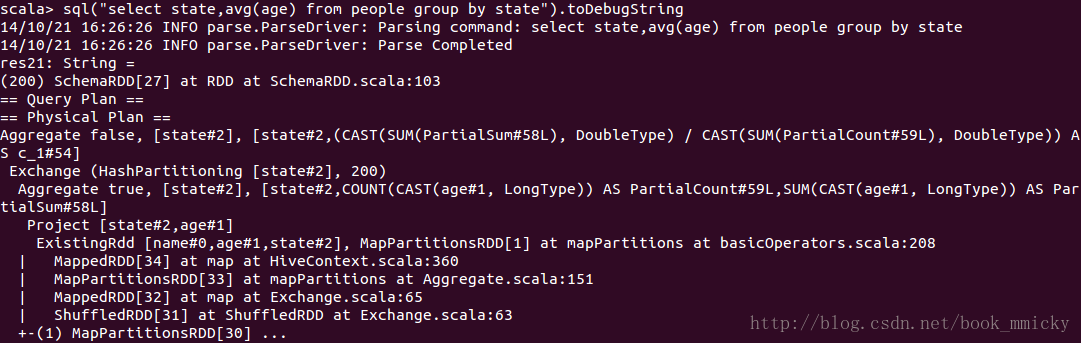
4.1 聚合查询
- sql("select state,avg(age) from people group by state").queryExecution
- sql("select state,avg(age) from people group by state").toDebugString
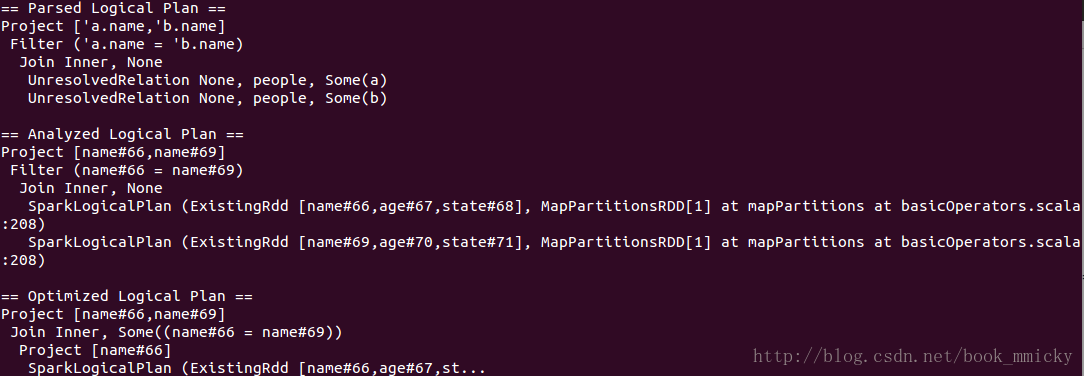
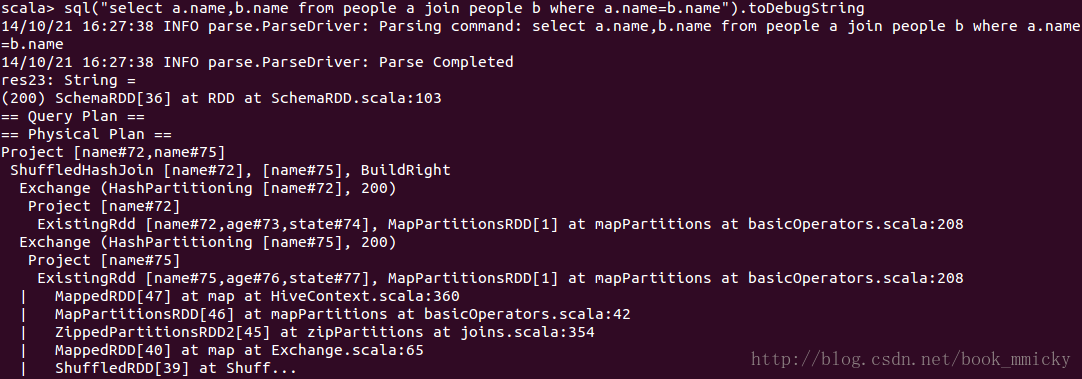
4.2 join操作
- sql("select a.name,b.name from people a join people b where a.name=b.name").queryExecution
- sql("select a.name,b.name from people a join people b where a.name=b.name").toDebugString
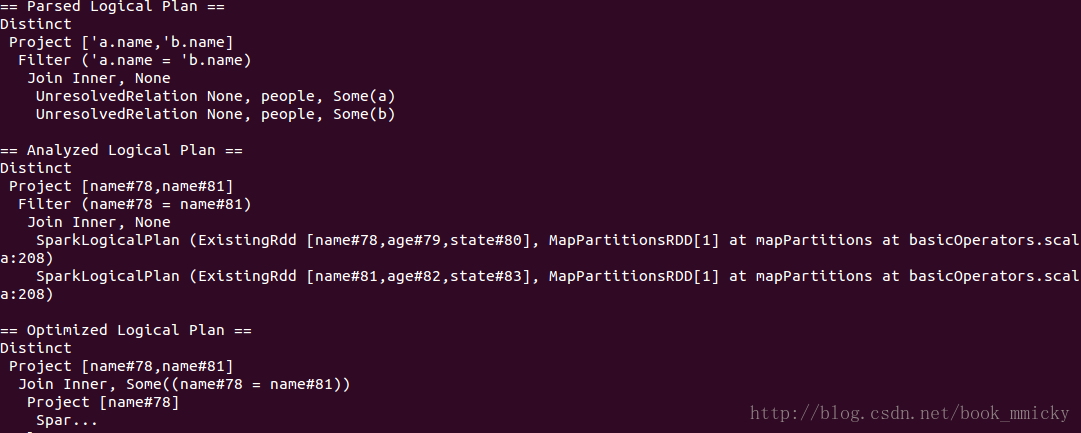
4.3 Distinct操作
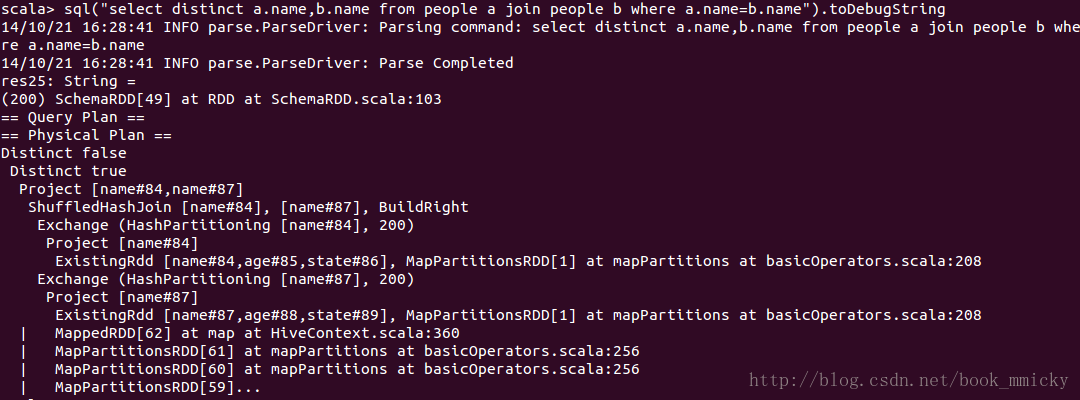
- sql("select distinct a.name,b.name from people a join people b where a.name=b.name").queryExecution
- sql("select distinct a.name,b.name from people a join people b where a.name=b.name").toDebugString
5:查询的优化
上面的查询比较简单,看不出优化的过程,下面看几个例子,可以理解sparkSQL的优化过程。
5.1 CombineFilters
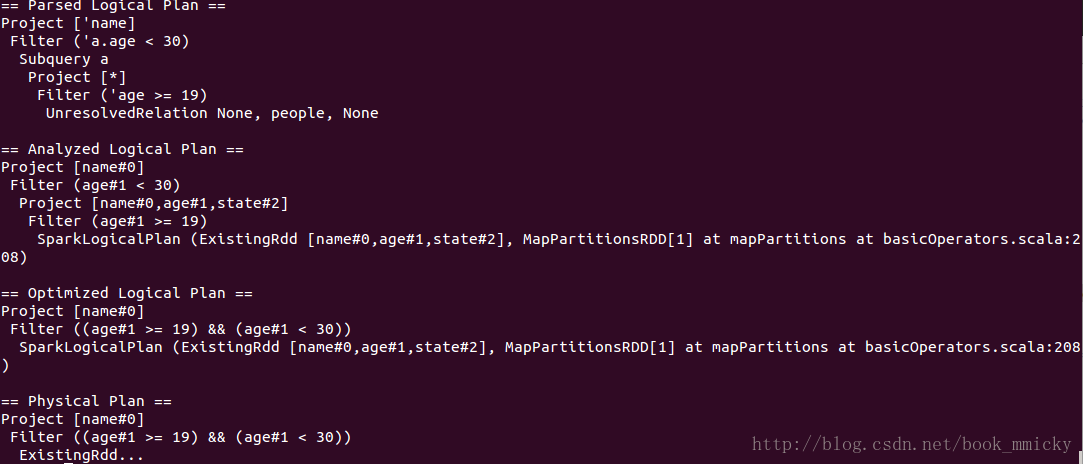
CombineFilters就是合并Filter,在含有多个Filter时发生,如下查询:
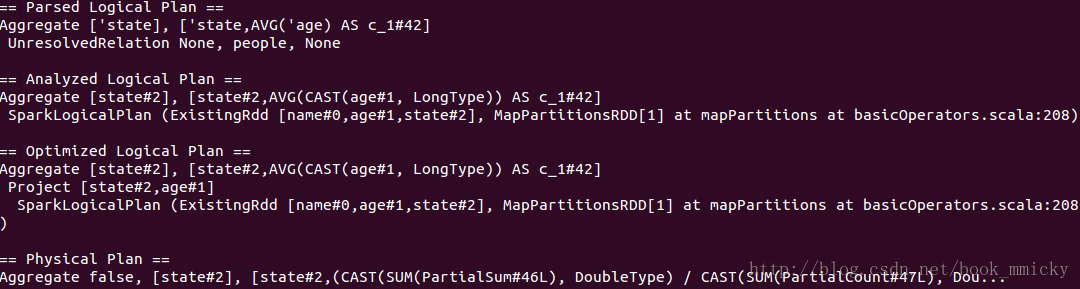
- sql("select name from (select * from people where age >=19) a where a.age <30").queryExecution
上面的查询,在Optimized的过程中,将age>=19和age<30这两个Filter合并了,合并成((age>=19) && (age<30))。其实上面还做了一个其他的优化,就是project的下推,子查询使用了表的所有列,而主查询使用了列name,在查询数据的时候子查询优化成只查列name。
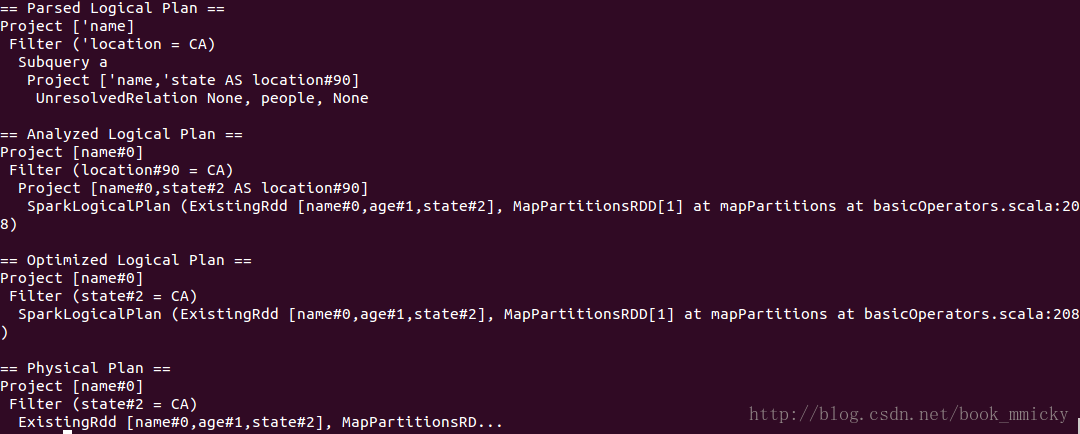
5.2 PushPredicateThroughProject
PushPredicateThroughProject就是project下推,和上面例子中的project一样。
- sql("select name from (select name,state as location from people) a where location='CA'").queryExecution
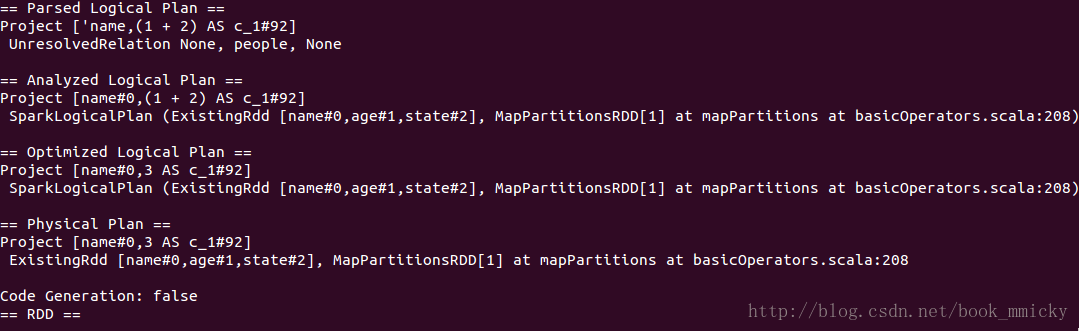
5.3 ConstantFolding
ConstantFolding是常量叠加,用于表达式。如下面的例子:
- sql("select name,1+2 from people").queryExecution
在Optimized的过程中,将常量表达式直接累加在一起,用新的列名来表示。
5.4 自定义优化
在sparkSQL中的Optimizer中定义了3类12中优化方法,这里不再一一陈列。对于用于自定义的优化,在hive/console也可以很方便的调试。只要先定义一个LogicalPlan,然后使用自定义的优化函数进行测试就可以了。下面就举个和CombineFilters一样的例子,首先定义一个函数:
- object CombineFilters extends Rule[LogicalPlan] {
- def apply(plan: LogicalPlan): LogicalPlan = plan transform {
- case Filter(c1, Filter(c2, grandChild)) =>
- Filter(And(c1,c2),grandChild)
- }
- }
然后定义一个query,并使用query.queryExecution.analyzed查看优化前的LogicPlan:
- val query= sql("select * from people").where('age >=19).where('age <30)
- query.queryExecution.analyzed
最后,使用自定义优化函数进行优化:

甚至,在hive/console里直接使用transform对LogicPlan应用定义好的rule,下面定义了一个query,并使用query.queryExecution.analyzed查看应用rule前的LogicPlan:
- val hiveQuery = sql("SELECT * FROM (SELECT * FROM src) a")
- hiveQuery.queryExecution.analyzed
然后,直接用transform将自定义的rule:
- hiveQuery.queryExecution.analyzed transform {
- case Project(projectList, child) if projectList == child.output => child
- }
该transform在LogicPlan的主查询和子查询的project相同时合并project。
经过上面的例子,加上自己的理解,相信大部分的读者对sparkSQL中的运行计划应该有了比较明确的了解。
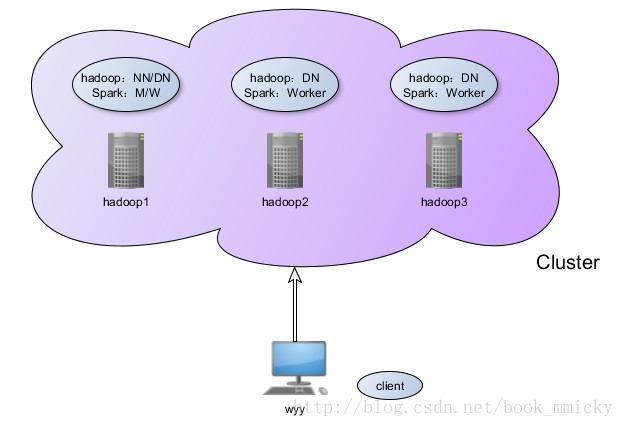
五:测试环境之搭建
前面介绍了sparkSQL的运行架构,后面将介绍sparkSQL的使用。在介绍sparkSQL的使用之前,我们需要搭建一个sparkSQL的测试环境。本次测试环境涉及到hadoop之HDFS、hive、spark以及相关的数据文件,相关的信息如下:
参数的含义:
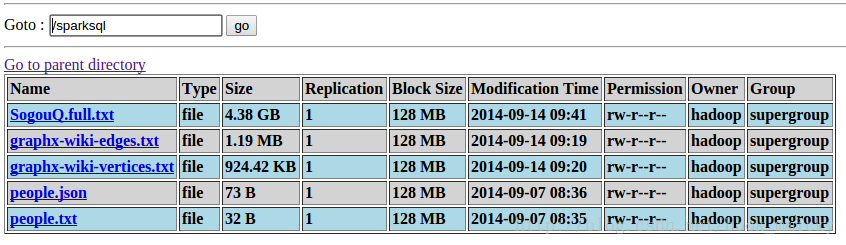
最终在HDFS可以看到相关的数据:
- hadoop版本为2.2.0
- hive版本为0.13
- spark版本为1.1.0
- MySQL版本为5.6.12
- 测试数据下载地点:http://pan.baidu.com/s/1eQCbT30#path=%252Fblog 中的sparkSQL_data.zip
测试环境示意图:
本测试环境是在一台物理机上搭建的,物理机的配置是16G内存,4核8线程CPU。hadoop1、hadoop2、hadoop3是vitual box虚拟机,构建hadoop集群和spark集群;物理机wyy作为客户端,编写代码和提交计算任务。总的测试环境配置如下:
| 机器名 | 配置 | 角色 | 软件安装 |
| hadoop1 | 4G内存,1核 | hadoop:NN/DN Spark:Master/worker | /app/hadoop/hadoop220
/app/hadoop/spark110
/app/scala2104
/usr/java/jdk1.7.0_21
|
| hadoop2 | 4G内存,1核 | hadoop:DN Spark:worker hive0.13客户端 | /app/hadoop/hadoop220
/app/hadoop/spark110
/app/hadoop/hive013
/app/scala2104
/usr/java/jdk1.7.0_21
|
| hadoop3 | 4G内存,1核 | hadoop:DN Spark:worker hive0.13 metaserver service mysql server | /app/hadoop/hadoop220
/app/hadoop/spark100
/app/hadoop/hive013
/app/scala2104
/usr/java/jdk1.7.0_21
MySQL5.6.12
|
| wyy | 16G内存,4核 | client hive0.13客户端 | /app/hadoop/hadoop220 /app/hadoop/spark110 /app/hadoop/hive013 |
以上hadoop220、spark、hive安装目录的用户属性都是hadoop(组别为hadoop),其他安装目录的用户属性是root:root。
测试环境搭建顺序
1:虚拟集群的搭建(hadoop1、hadoop2、hadoop3)
A:hadoop2.2.0集群搭建
参照博客
hadoop2.2.0测试环境搭建
或者参看视频
http://pan.baidu.com/s/1qWqFY4c 提取密码:xv4i
B:MySQL的安装
C:hive的安装
参照博客
Hive 0.11.0 远程模式搭建
本测试中使用的hive0.13,和hive0.11的安装一样。
hive安装在hadoop3、hadoop2、wyy。其中hadoop3启动metastore serive;hadoop2、wyy配置uris后作为hive的客户端。
D:Spark1.1.0 Standalone集群搭建
这里需要注意的是,本测试中使用的是spark1.1.0,部署包生成命令make-distribution.sh的参数发生了变化,spark1.1.0的make-distribution.sh使用格式:
- ./make-distribution.sh [--name] [--tgz] [--with-tachyon] <maven build options>
--with-tachyon:是否支持内存文件系统Tachyon,不加此参数时为不支持。
--tgz:在根目录下生成 spark-$VERSION-bin.tar.gz,不加此参数是不生成tgz文件,只生成/dist目录。
--name NAME :和— tgz 结合可以生成 spark-$VERSION-bin-$NAME.tgz 的部署包,不加此参数时 NAME 为 hadoop 的版本号。
maven build options:使用maven编译时可以使用的配置选项,如使用-P、-D的选项
本次要生成基于hadoop2.2.0和yarn并集成hive、ganglia、asl的spark1.1.0部署包,可以使用命令:
- ./make-distribution.sh --tgz --name 2.2.0 -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive
最后生成部署包spark-1.1.0-bin-2.2.0.tgz,按照测试环境的规划进行安装。
2:客户端的搭建
客户端wyy采用的Ubuntu操作系统,而Spark虚拟集群采用的是CentOS,默认的java安装目录两个操作系统是不一样的,所以在Ubuntu下安装java的时候特意将java的安装路径改成和CentOS一样。不然的话,每次scp了虚拟集群的配置文件之后,要修改hadoop、spark运行配置文件中的JAVA_HOME。
客户端hadoop2.2.0、Spark1.1.0、hive0.13是直接从虚拟集群中scp出来的,放置在相同的目录下,拥有相同的用户属性。开发工具使用的IntelliJ IDEA,程序编译打包后复制到spark1.1.0的根目录/app/hadoop/spark110下,使用spark-submit提交虚拟机集群运行。
3:文件数据准备工作
启动hadoop2.2.0(只需要HDFS启动就可以了),然后将数据文件上传到对应的目录:
- people.txt和people.json作为第六节sparkSQL之基础应用实验数据;
- graphx-wiki-vertices.txt和graphx-wiki-edges.txt作为第八节sparkSQL之综合应用中图处理数据;
- SogouQ.full.txt来源于Sogou实验室,下载地址:http://download.labs.sogou.com/dl/q.html 完整版(2GB):gz格式,作为第九节sparkSQL之调优的测试数据
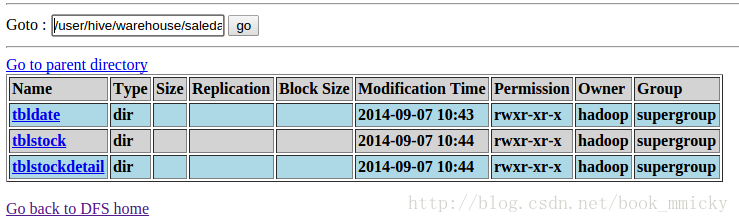
4:hive数据准备工作
在hive里定义一个数据库saledata,和三个表tblDate、tblStock、tblStockDetail,并装载数据,具体命令:
- CREATE DATABASE SALEDATA;
- use SALEDATA;
- //Date.txt文件定义了日期的分类,将每天分别赋予所属的月份、星期、季度等属性
- //日期,年月,年,月,日,周几,第几周,季度,旬、半月
- CREATE TABLE tblDate(dateID string,theyearmonth string,theyear string,themonth string,thedate string,theweek string,theweeks string,thequot string,thetenday string,thehalfmonth string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ;
- //Stock.txt文件定义了订单表头
- //订单号,交易位置,交易日期
- CREATE TABLE tblStock(ordernumber string,locationid string,dateID string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ;
- //StockDetail.txt文件定义了订单明细
- //订单号,行号,货品,数量,金额
- CREATE TABLE tblStockDetail(ordernumber STRING,rownum int,itemid string,qty int,price int,amount int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ;
- //装载数据
- LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/Date.txt' INTO TABLE tblDate;
- LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/Stock.txt' INTO TABLE tblStock;
- LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/StockDetail.txt' INTO TABLE tblStockDetail;
SparkSQL引入了一种新的RDD——SchemaRDD,SchemaRDD由行对象(row)以及描述行对象中每列数据类型的schema组成;SchemaRDD很象传统数据库中的表。SchemaRDD可以通过RDD、Parquet文件、JSON文件、或者通过使用hiveql查询hive数据来建立。SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
值得注意的是:
- Spark1.1使用registerTempTable代替1.0版本的registerAsTable
- Spark1.1在hiveContext中,hql()将被弃用,sql()将代替hql()来提交查询语句,统一了接口。
- 使用registerTempTable注册表是一个临时表,生命周期只在所定义的sqlContext或hiveContext实例之中。换而言之,在一个sqlontext(或hiveContext)中registerTempTable的表不能在另一个sqlContext(或hiveContext)中使用。
- sqlContext现在只支持sql语法解析器(SQL-92语法)
- hiveContext现在支持sql语法解析器和hivesql语法解析器,默认为hivesql语法解析器,用户可以通过配置切换成sql语法解析器,来运行hiveql不支持的语法,如select 1。
切换可以通过下列方式完成:
- 在sqlContexet中使用setconf配置spark.sql.dialect
- 在hiveContexet中使用setconf配置spark.sql.dialect
- 在sql命令中使用 set spark.sql.dialect=value
sparkSQL1.1对数据的查询分成了2个分支:sqlContext 和 hiveContext。至于两者之间的关系,hiveSQL继承了sqlContext,所以拥有sqlontext的特性之外,还拥有自身的特性(最大的特性就是支持hive,
运行下列代码:

运行结果:

然后,将people.parquet读入,注册成表parquetTable,查询年纪大于25岁的人名:
运行结果:


然后就可以对hive数据进行操作了,下面我们将使用hive中的销售数据(第五小结中的hive数据),首先切换数据库到saledata并查看有几个表:

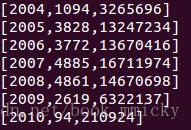
现在查询一下所有订单中每年的销售单数、销售总额:
运行结果:
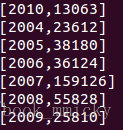
再做一个稍微复杂点的查询,求出所有订单每年最大金额订单的销售额:
运行结果:
最后做一个更复杂的查询,求出所有订单中每年最畅销货品:
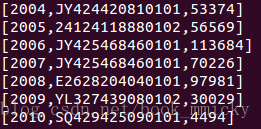
运行结果:

运行结果:

在默认的情况下,内存列存储的压缩功能是关闭的,要使用压缩功能需要配置变量COMPRESS_CACHED。

在sqlContext里可以如下使用cache:
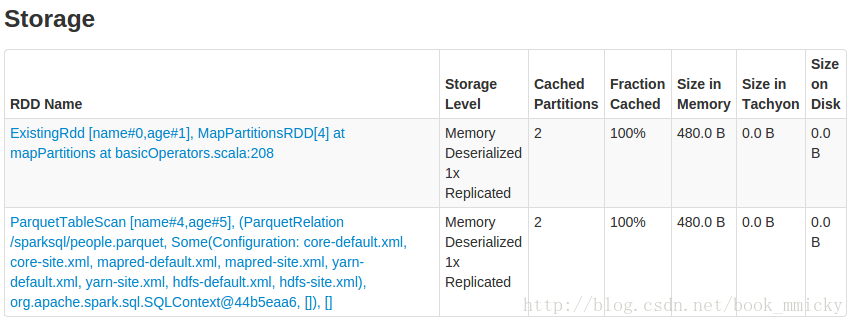
观察webUI,可以看到cache的信息。(注意cache是lazy的,要有action才会实现;uncache是eager的,可以立即实现)
使用如下命令可以取消cache:
)。
下面就sparkSQL的一些基本操作做一演示:
- sqlContext基础应用
- RDD
- parquet文件
- json文件
- hiveContext基础应用
- 混合使用
- 缓存之使用
- DSL之使用
为了方便演示,我们在spark-shell里面进行下列演示,并加以说明。首先,启动spark集群,然后在客户端wyy上启动spark-shell:
- bin/spark-shell --master spark://hadoop1:7077 --executor-memory 3g
1:sqlContext基础应用
首先创建sqlContext,并引入
sqlContext.createSchemaRDD以完成RDD隐式转换成SchemaRDD:
- val sqlContext= new org.apache.spark.sql.SQLContext(sc)
- import sqlContext.createSchemaRDD
1.1:RDD
Spark1.1.0开始提供了两种方式将RDD转换成SchemaRDD:
- 通过定义case class,使用反射推断Schema(case class方式)
- 通过可编程接口,定义Schema,并应用到RDD上(applySchema 方式)
前者使用简单、代码简洁,适用于已知Schema的源数据上;后者使用较为复杂,但可以在程序运行过程中实行,适用于未知Schema的RDD上。
1.1.1 case class方式
对于case class方式,首先要定义case class,在RDD的transform过程中使用case class可以隐式转化成SchemaRDD,然后再使用registerTempTable注册成表。注册成表后就可以在sqlContext对表进行操作,如select 、insert、join等。注意,case class可以是嵌套的,也可以使用类似Sequences 或 Arrays之类复杂的数据类型。
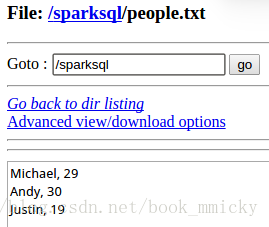
下面的例子是定义一个符合数据文件/sparksql/people.txt类型的case clase(Person),然后将数据文件读入后隐式转换成SchemaRDD:people,并将people在sqlContext中注册成表rddTable,最后对表进行查询,找出年纪在13-19岁之间的人名。
/sparksql/people.txt的内容有3行:
- //RDD1演示
- case class Person(name:String,age:Int)
- val rddpeople=sc.textFile("/sparksql/people.txt").map(_.split(",")).map(p=>Person(p(0),p(1).trim.toInt))
- rddpeople.registerTempTable("rddTable")
- sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
运行结果:
1.1.2 applySchema 方式
applySchema 方式比较复杂,通常有3步过程:
applySchema 方式比较复杂,通常有3步过程:
- 从源RDD创建rowRDD
- 创建与rowRDD匹配的Schema
- 将Schema通过applySchema应用到rowRDD
上面的例子通过applySchema 方式实现的代码如下:
- //RDD2演示
- //导入SparkSQL的数据类型和Row
- import org.apache.spark.sql._
- //创建于数据结构匹配的schema
- val schemaString = "name age"
- val schema =
- StructType(
- schemaString.split(" ").map(fieldName => StructField(fieldName, StringType, true)))
- //创建rowRDD
- val rowRDD = sc.textFile("/sparksql/people.txt").map(_.split(",")).map(p => Row(p(0), p(1).trim))
- //用applySchema将schema应用到rowRDD
- val rddpeople2 = sqlContext.applySchema(rowRDD, schema)
- rddpeople2.registerTempTable("rddTable2")
- sqlContext.sql("SELECT name FROM rddTable2 WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
1.2:parquet文件
同样得,sqlContext可以读取parquet文件,由于parquet文件中保留了schema的信息,所以不需要使用case class来隐式转换。sqlContext读入parquet文件后直接转换成SchemaRDD,也可以将SchemaRDD保存成parquet文件格式。
我们先将上面建立的SchemaRDD:people保存成parquet文件:
- rddpeople.saveAsParquetFile("/sparksql/people.parquet")
运行后/sparksql/目录下就多出了一个名称为people.parquet的目录:
- //parquet演示
- val parquetpeople = sqlContext.parquetFile("/sparksql/people.parquet")
- parquetpeople.registerTempTable("parquetTable")
- sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)
1.3:json文件
sparkSQL1.1.0开始提供对json文件格式的支持,这意味着开发者可以使用更多的数据源,如鼎鼎大名的NOSQL数据库MongDB等。sqlContext可以从jsonFile或jsonRDD获取schema信息,来构建SchemaRDD,注册成表后就可以使用。
- jsonFile - 加载JSON文件目录中的数据,文件的每一行是一个JSON对象。
- jsonRdd - 从现有的RDD加载数据,其中RDD的每个元素包含一个JSON对象的字符串。
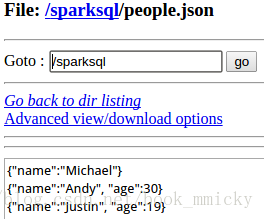
下面的例子读入一个json文件/sparksql/people.json,注册成jsonTable,并查询年纪大于25岁的人名。
/sparksql/people.json的内容:
运行下面代码:
- //json演示
- val jsonpeople = sqlContext.jsonFile("/sparksql/people.json")
- jsonpeople.registerTempTable("jsonTable")
- sqlContext.sql("SELECT name FROM jsonTable WHERE age >= 25").map(t => "Name: " + t(0)).collect().foreach(println)
运行结果:
2:hiveContext基础应用
使用hiveContext之前首先要确认以下两点:
- 使用的Spark是支持hive
- hive的配置文件hive-site.xml已经存在conf目录中
要使用hiveContext,需要先构建hiveContext:
- val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
- hiveContext.sql("use saledata")
- hiveContext.sql("show tables").collect().foreach(println)
可以看到有在第五小节定义的3个表:
- //所有订单中每年的销售单数、销售总额
- //三个表连接后以count(distinct a.ordernumber)计销售单数,sum(b.amount)计销售总额
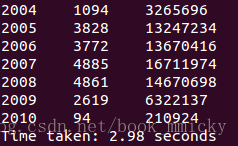
- hiveContext.sql("select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear order by c.theyear").collect().foreach(println)
- /************************
- 所有订单每年最大金额订单的销售额:
- 第一步,先求出每份订单的销售额以其发生时间
- select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber
- 第二步,以第一步的查询作为子表,和表tblDate连接,求出每年最大金额订单的销售额
- select c.theyear,max(d.sumofamount) from tbldate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear
- *************************/
- hiveContext.sql("select c.theyear,max(d.sumofamount) from tbldate c join (select a.dateid,a.ordernumber,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber group by a.dateid,a.ordernumber ) d on c.dateid=d.dateid group by c.theyear sort by c.theyear").collect().foreach(println)
- /************************
- 所有订单中每年最畅销货品:
- 第一步:求出每年每个货品的销售金额
- select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid
- 第二步:求出每年单品销售的最大金额
- select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear
- 第三步:求出每年与销售额最大相符的货品就是最畅销货品
- select distinct e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear
- *************************/
- hiveContext.sql("select distinct e.theyear,e.itemid,f.maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid) e join (select d.theyear,max(d.sumofamount) as maxofamount from (select c.theyear,b.itemid,sum(b.amount) as sumofamount from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear,b.itemid) d group by d.theyear) f on (e.theyear=f.theyear and e.sumofamount=f.maxofamount) order by e.theyear").collect().foreach(println)
运行结果:
3:混合使用
在sqlContext或hiveContext中,来源于不同数据源的表在各自生命周期中可以混用,但是不同实例之间的表不能混合使用。
3.1 sqlContext中混合使用:
- //sqlContext中混合使用
- //sqlContext中来自rdd的表rddTable和来自parquet文件的表parquetTable混合使用
- sqlContext.sql("select a.name,a.age,b.age from rddTable a join parquetTable b on a.name=b.name").collect().foreach(println)
3.2 hiveContext中混合使用:
- //hiveContext中混合使用
- //创建一个hiveTable,并将数据加载,注意people.txt第二列有空格,所以age取string类型
- hiveContext.sql("CREATE TABLE hiveTable(name string,age string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' LINES TERMINATED BY '\n' ")
- hiveContext.sql("LOAD DATA LOCAL INPATH '/home/mmicky/mboo/MyClass/doc/sparkSQL/data/people.txt' INTO TABLE hiveTable")
- //创建一个源自parquet文件的表parquetTable2,然后和hiveTable混合使用
- hiveContext.parquetFile("/sparksql/people.parquet").registerAsTable("parquetTable2")
- hiveContext.sql("select a.name,a.age,b.age from hiveTable a join parquetTable2 b on a.name=b.name").collect().foreach(println)
4:缓存之使用
sparkSQL的cache可以使用两种方法来实现:
- cacheTable()方法
- CACHE TABLE命令
- //sqlContext的cache使用
- sqlContext.cacheTable("rddTable")
- sqlContext.sql("SELECT name FROM rddTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
- sqlContext.sql("CACHE TABLE parquetTable")
- sqlContext.sql("SELECT name FROM parquetTable WHERE age >= 13 AND age <= 19").map(t => "Name: " + t(0)).collect().foreach(println)
- sqlContext.uncacheTable("rddTable")
- sqlContext.sql("UNCACHE TABLE parquetTable")
同样的,在hiveContext也可以使用上面的方法cache或uncache(hiveContext继承于sqlContext)。
5:DSL之使用
sparkSQL除了支持HiveQL和SQL-92语法外,还支持DSL(Domain Specific Language)。在DSL中,使用scala符号'+标示符表示基础表中的列,spark的execution engine会将这些标示符隐式转换成表达式。另外可以在API中找到很多DSL相关的方法,如where()、select()、limit()等等,详细资料可以查看catalyst模块中的dsl子模块,下面为其中定义几种常用方法:
关于DSL的使用,随便举个例子,结合DSL方法,很容易上手:
- //DSL演示
- val teenagers_dsl = rddpeople.where('age >= 10).where('age <= 19).select('name)
- teenagers_dsl.map(t => "Name: " + t(0)).collect().foreach(println)
6:Tips
上面介绍了sparkSQL的基础应用,sparkSQL还在高速发展中,存在者不少缺陷,如:
- scala2.10.4本身对case class有22列的限制,在使用RDD数据源的时候就会造成不方便;
- sqlContext中3个表不能同时join,需要两两join后再join一次;
- sqlContext中不能直接使用values插入数据;
- 。。。
七:ThriftServer和CLI
spark1.1相较于spark1.0,最大的差别就在于spark1.1增加了万人期待的CLI和ThriftServer。使得hive用户还有用惯了命令行的RDBMS数据库管理员很容易地上手sparkSQL,在真正意义上进入了SQL时代。下面先简单介绍其使用,限于时间关系,以后再附上源码分析。
顺便地测试了一下hive0.13的语法(测试系统中使用的是hive0.13,spark1.1编译的时候是hive0.12,毫无意外地,在CLI里是不能使用hive0.13的语法,必须使用和spark匹配的hive版本的hive语法)。
1:令人惊讶的CLI
刚部署好spark1.1就迫不及待地先测试CLI(bin/spark-sql),对于习惯了sql命令行的本人,失去了shark后,对于sparkSQL1.0一度很是抵触(其实对于开发调试人员来说,spark-shell才是利器,可以很方便地使用各个spark生态中的组件)。急切中,没有关闭hive metastore服务,然后一个bin/spark-sql就进入了命令行,然后通过hive metastore就可以直接对hive进行查询了:
- spark-sql> use saledata;
- //所有订单中每年的销售单数、销售总额
- spark-sql> select c.theyear,count(distinct a.ordernumber),sum(b.amount) from tblStock a join tblStockDetail b on a.ordernumber=b.ordernumber join tbldate c on a.dateid=c.dateid group by c.theyear order by c.theyear;
运行结果:
1.1 CLI配置

这时就可以使用HQL语句对hive数据进行查询,另外,可以使用COMMAND,如使用set进行设置参数:默认情况下,sparkSQL shuffle的时候是200个partition,可以使用如下命令修改这个参数:
运行同一个查询语句,参数改变后,Task(partition)的数量就由200变成了20。
基本上,在CLI可以使用绝大多数的hive特性。

注意不要将hive.server2.thrift.bind.host配置能localhost,不然远程客户端不能连接。
然后,对tblstock进行下面操作:
因为首次操作,所以统计花了11.725秒,查看webUI,tblStock已经缓存:
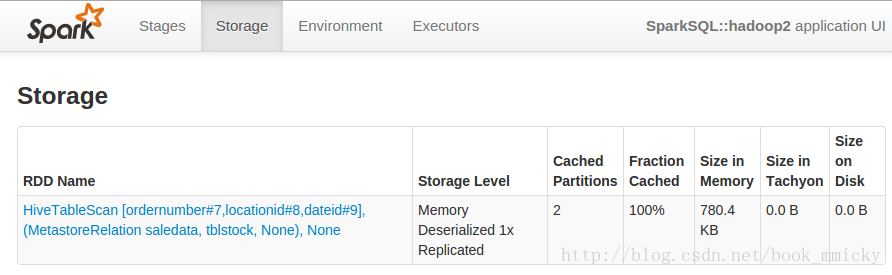
然后启动另外一个远程连接,切换到hadoop1,
启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000
连接ThriftServer,然后直接运行对tblstock计数(注意没有进行数据库的切换):
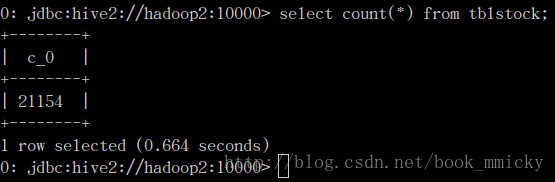
用时
0.664秒,再查看webUI中的stage:

Locality Level是PROCESS,显然是使用了缓存表。
运行结果:
如需更详细的信息,请参照:
HiveServer2 Clients。
在使用CLI前,要先启动hive metastore;而CLI的配置非常简单,在conf/hive-site.xml中之需要指定hive metastore的uris就可以使用了。现在要在客户端wyy上使用spark-sql,配置conf/hive-site.xml如下:
- <configuration>
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://hadoop3:9083</value>
- <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
- </property>
- </configuration>
1.2 CLI命令参数
通过
bin/spark-sql --help可以查看CLI命令参数:
- [hadoop@hadoop3 spark110]$ bin/spark-sql --help
- Usage: ./bin/spark-sql [options] [cli option]
- CLI options:
- -d,--define <keykey=value> Variable subsitution to apply to hive
- commands. e.g. -d A=B or --define A=B
- --database <databasename> Specify the database to use
- -e <quoted-query-string> SQL from command line
- -f <filename> SQL from files
- -h <hostname> connecting to Hive Server on remote host
- --hiveconf <propertyproperty=value> Use value for given property
- --hivevar <keykey=value> Variable subsitution to apply to hive
- commands. e.g. --hivevar A=B
- -i <filename> Initialization SQL file
- -p <port> connecting to Hive Server on port number
- -S,--silent Silent mode in interactive shell
- -v,--verbose Verbose mode (echo executed SQL to the
- console)
其中[options] 是CLI启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动spark-sql的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照
Spark1.0.0 应用程序部署工具spark-submit 的参数。
[cli option]是CLI的参数,通过这些参数,CLI可以直接运行SQL文件、进入命令行运行SQL命令等等,类似以前的shark的用法。需要注意的是CLI不是使用JDBC连接,所以不能连接到ThriftServer;但可以配置conf/hive-site.xml连接到hive的metastore,然后对hive数据进行查询。
1.3 CLI使用
启动spark-sql:
- bin/spark-sql --master spark://hadoop1:7077 --executor-memory 3g
在集群监控页面可以看到启动了SparkSQL应用程序:
- SET spark.sql.shuffle.partitions=20;
2:ThriftServer
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个sparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个sparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用hive数据的话,还要提供hive metastore的uris。
2.1 ThriftServer配置
通常,ThriftServer可以在conf/hive-site.xml中定义以下几项配置,也可以使用环境变量的方式进行配置(环境变量的优先级高于hive-site.xml)。
下面是在实验集群中hadoop2上启动ThriftServer的hive-site.xml配置:
- <configuration>
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://hadoop3:9083</value>
- <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description>
- </property>
- <property>
- <name>hive.server2.thrift.min.worker.threads</name>
- <value>5</value>
- <description>Minimum number of Thrift worker threads</description>
- </property>
- <property>
- <name>hive.server2.thrift.max.worker.threads</name>
- <value>500</value>
- <description>Maximum number of Thrift worker threads</description>
- </property>
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10000</value>
- <description>Port number of HiveServer2 Thrift interface. Can be overridden by setting $HIVE_SERVER2_THRIFT_PORT</description>
- </property>
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>hadoop2</value>
- <description>Bind host on which to run the HiveServer2 Thrift interface.Can be overridden by setting$HIVE_SERVER2_THRIFT_BIND_HOST</description>
- </property>
- </configuration>
2.2 ThriftServer命令参数
使用
sbin/start-thriftserver.sh --help可以查看ThriftServer的命令参数:
- [hadoop@hadoop3 spark110]$ sbin/start-thriftserver.sh --help
- Usage: ./sbin/start-thriftserver [options] [thrift server options]
- Thrift server options:
- Use value for given property
其中[options] 是ThriftServer启动一个SparkSQL应用程序的参数,如果不设置--master的话,将在启动ThriftServer的机器以local方式运行,只能通过http://机器名:4040进行监控;这部分参数,可以参照
Spark1.0.0 应用程序部署工具spark-submit 的参数。在集群中提供ThriftServer的话,一定要配置master、executor-memory等参数。
[thrift server options]是ThriftServer的参数,可以使用-d
property=value的格式来定义;在实际应用上,因为参数比较多,通常使用conf/hive-site.xml配置。
2.3 ThriftServer使用
2.3.1 启动ThriftServer
启动ThriftServer,使之运行在spark集群中:
- sbin/start-thriftserver.sh --master spark://hadoop1:7077 --executor-memory 3g
在集群监控页面可以看到启动了SparkSQL应用程序:
2.3.2 远程客户端连接
切换到客户端wyy,启动bin/beeline,用!connect jdbc:hive2://hadoop2:10000
连接ThriftServer,因为没有采用权限管理,所以用户名用运行bin/beeline的用户,密码为空:
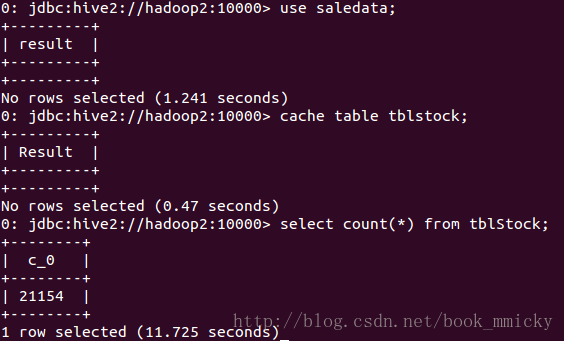
- 切换数据库saledata;
- cache table tblstock;
- 对tblstock计数;
从上可以看出,ThriftServer可以连接多个JDBC/ODBC客户端,并相互之间可以共享数据。顺便提一句,ThriftServer启动后处于监听状态,用户可以使用ctrl+c退出ThriftServer;而beeline的退出使用!q命令。
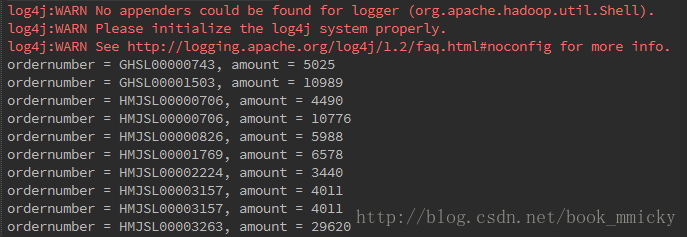
2.3.3 代码示例
有了ThriftServer,开发人员可以非常方便的使用JDBC/ODBC来访问sparkSQL。下面是一个scala代码,查询表tblStockDetail ,返回amount>3000的单据号和交易金额:
- package doc
- import java.sql.DriverManager
- object SQLJDBC {
- def main(args: Array[String]) {
- Class.forName("org.apache.hive.jdbc.HiveDriver")
- val conn = DriverManager.getConnection("jdbc:hive2://hadoop2:10000", "hadoop", "")
- try {
- val statement = conn.createStatement
- val rs = statement.executeQuery("select ordernumber,amount from tblStockDetail where amount>3000")
- while (rs.next) {
- val ordernumber = rs.getString("ordernumber")
- val amount = rs.getString("amount")
- println("ordernumber = %s, amount = %s".format(ordernumber, amount))
- }
- } catch {
- case e: Exception => e.printStackTrace
- }
- conn.close
- }
- }
3:小结
总的来说,ThriftServer和CLI的引入,使得sparkSQL可以更方便的使用hive数据,使得sparkSQL可以更接近使用者,而非开发者。
八:sparkSQL之综合应用
Spark之所以万人瞩目,除了内存计算,还有其ALL-IN-ONE的特性,实现了One stack rule them all。下面简单模拟了几个综合应用场景,不仅使用了sparkSQL,还使用了其他Spark组件:
编译打包后,复制到spark安装目录下运行:
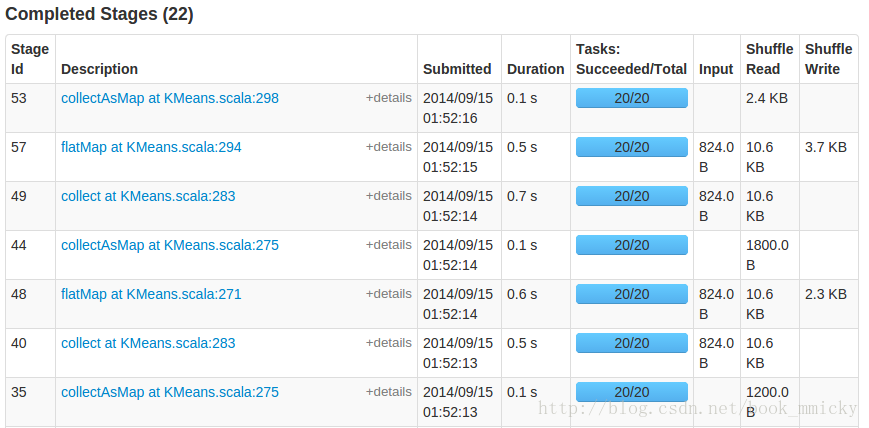
运行完毕,使用getmerge将结果转到本地文件,并查看结果:
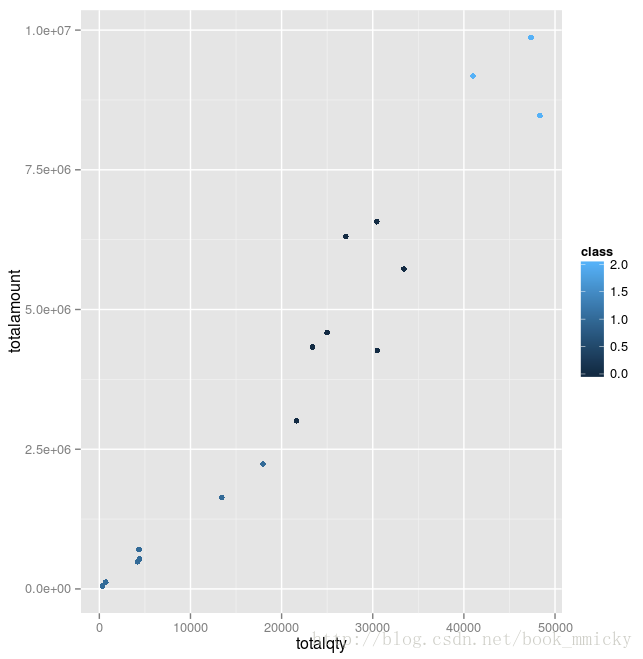
最后使用R做示意图,用3种不同的颜色表示不同的类别。
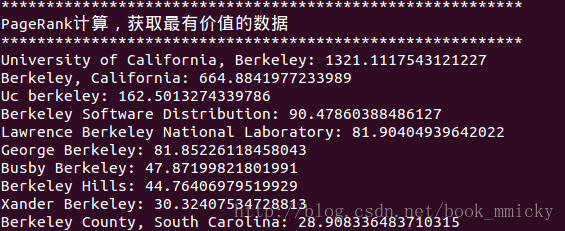
spark是一个快速的内存计算框架;同时是一个并行运算的框架。在计算性能调优的时候,除了要考虑广为人知的木桶原理外,还要考虑平行运算的Amdahl定理。
- 店铺分类,根据销售额对店铺分类,使用sparkSQL和MLLib
- PageRank,计算最有价值的网页,使用sparkSQL和GraphX
前者将使用sparkSQL+MLlib的聚类算法,后者将使用sparkSQL+GraphX的PageRank算法。本实验采用IntelliJ IDEA调试代码,最后生成doc.jar,然后使用spark-submit提交给集群运行。
1:店铺分类
分类在实际应用中非常普遍,比如对客户进行分类、对店铺进行分类等等,对不同类别采取不同的策略,可以有效的降低企业的营运成本、增加收入。机器学习中的聚类就是一种根据不同的特征数据,结合用户指定的类别数量,将数据分成几个类的方法。下面举个简单的例子,对第五小结中的hive数据,按照销售数量和销售金额这两个特征数据,进行聚类,分出3个等级的店铺。
在IDEA中建立一个object:SQLMLlib
- package doc
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.sql.catalyst.expressions.Row
- import org.apache.spark.{SparkConf, SparkContext}
- import org.apache.spark.sql.hive.HiveContext
- import org.apache.spark.mllib.clustering.KMeans
- import org.apache.spark.mllib.linalg.Vectors
- object SQLMLlib {
- def main(args: Array[String]) {
- //屏蔽不必要的日志显示在终端上
- Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
- Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- //设置运行环境
- val sparkConf = new SparkConf().setAppName("SQLMLlib")
- val sc = new SparkContext(sparkConf)
- val hiveContext = new HiveContext(sc)
- //使用sparksql查出每个店的销售数量和金额
- hiveContext.sql("use saledata")
- hiveContext.sql("SET spark.sql.shuffle.partitions=20")
- val sqldata = hiveContext.sql("select a.locationid, sum(b.qty) totalqty,sum(b.amount) totalamount from tblStock a join tblstockdetail b on a.ordernumber=b.ordernumber group by a.locationid")
- //将查询数据转换成向量
- val parsedData = sqldata.map {
- case Row(_, totalqty, totalamount) =>
- val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
- Vectors.dense(features)
- }
- //对数据集聚类,3个类,20次迭代,形成数据模型
- //注意这里会使用设置的partition数20
- val numClusters = 3
- val numIterations = 20
- val model = KMeans.train(parsedData, numClusters, numIterations)
- //用模型对读入的数据进行分类,并输出
- //由于partition没设置,输出为200个小文件,可以使用bin/hdfs dfs -getmerge 合并下载到本地
- val result2 = sqldata.map {
- case Row(locationid, totalqty, totalamount) =>
- val features = Array[Double](totalqty.toString.toDouble, totalamount.toString.toDouble)
- val linevectore = Vectors.dense(features)
- val prediction = model.predict(linevectore)
- locationid + " " + totalqty + " " + totalamount + " " + prediction
- }.saveAsTextFile(args(0))
- sc.stop()
- }
- }
- cp /home/mmicky/IdeaProjects/doc/out/artifacts/doc/doc.jar .
- bin/spark-submit --master spark://hadoop1:7077 --executor-memory 3g --class doc.SQLMLlib doc.jar /sparksql/output1
运行过程,可以发现聚类过程都是使用20个partition:
- bin/hdfs dfs -getmerge /sparksql/output1 result.txt
2:PageRank
PageRank,即网页排名,又称网页级别、Google左侧排名或佩奇排名,是Google创始人拉里·佩奇和谢尔盖·布林于1997年构建早期的搜索系统原型时提出的链接分析算法。目前很多重要的链接分析算法都是在PageRank算法基础上衍生出来的。PageRank是Google用于用来标识网页的等级/重要性的一种方法,是Google用来衡量一个网站的好坏的唯一标准。在揉合了诸如Title标识和Keywords标识等所有其它因素之后,Google通过PageRank来调整结果,使那些更具“等级/重要性”的网页在搜索结果中令网站排名获得提升,从而提高搜索结果的相关性和质量。
Spark GraphX引入了google公司的图处理引擎pregel,可以方便的实现PageRank的计算。下面实例采用的数据是wiki数据中含有Berkeley标题的网页之间连接关系,该数据集已经经过ETL,最终为两个文件:graphx-wiki-vertices.txt和graphx-wiki-edges.txt ,可以分别用于图计算的顶点和边。
首先,启动bin/spark-sql,将这两个文件定义为表:
- //启动spark-sql,运行下列语句创建表
- CREATE TABLE vertices(ID BigInt,Title String) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
- LOAD DATA INPATH '/sparksql/graphx-wiki-vertices.txt' INTO TABLE vertices;
- CREATE TABLE edges(SRCID BigInt,DISTID BigInt) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n';
- LOAD DATA INPATH '/sparksql/graphx-wiki-edges.txt' INTO TABLE edges;
然后,在IDEA中建立一个object:SQLGraphX
- package doc
- import org.apache.log4j.{Level, Logger}
- import org.apache.spark.sql.hive.HiveContext
- import org.apache.spark.{SparkContext, SparkConf}
- import org.apache.spark.graphx._
- import org.apache.spark.sql.catalyst.expressions.Row
- object SQLGraphX {
- def main(args: Array[String]) {
- //屏蔽日志
- Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
- Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
- //设置运行环境
- val sparkConf = new SparkConf().setAppName("PageRank").setMaster("local")
- val sc = new SparkContext(sparkConf)
- val hiveContext = new HiveContext(sc)
- //使用sparksql查出每个店的销售数量和金额
- hiveContext.sql("use saledata")
- val verticesdata = hiveContext.sql("select id, title from vertices")
- val edgesdata = hiveContext.sql("select srcid,distid from edges")
- //装载顶点和边
- val vertices = verticesdata.map { case Row(id, title) => (id.toString.toLong, title.toString)}
- val edges = edgesdata.map { case Row(srcid, distid) => Edge(srcid.toString.toLong, distid.toString.toLong, 0)}
- //构建图
- val graph = Graph(vertices, edges, "").persist()
- //pageRank算法里面的时候使用了cache(),故前面persist的时候只能使用MEMORY_ONLY
- println("**********************************************************")
- println("PageRank计算,获取最有价值的数据")
- println("**********************************************************")
- val prGraph = graph.pageRank(0.001).cache()
- val titleAndPrGraph = graph.outerJoinVertices(prGraph.vertices) {
- (v, title, rank) => (rank.getOrElse(0.0), title)
- }
- titleAndPrGraph.vertices.top(10) {
- Ordering.by((entry: (VertexId, (Double, String))) => entry._2._1)
- }.foreach(t => println(t._2._2 + ": " + t._2._1))
- sc.stop()
- }
- }
编译打包后,复制到spark安装目录下运行:
- cp /home/mmicky/IdeaProjects/doc/out/artifacts/doc/doc.jar .
- bin/spark-submit --master spark://hadoop1:7077 --executor-memory 3g --class doc.SQLGraphX doc.jar
运行结果:
3:小结
在现实数据处理过程中,这种涉及多个系统处理的场景很多。通常各个系统之间的数据通过磁盘落地再交给下一个处理系统进行处理。对于Spark来说,通过多个组件的配合,可以以流水线的方式来处理数据。从上面的代码可以看出,程序除了最后有磁盘落地外,都是在内存中计算的。避免了多个系统中交互数据的落地过程,提高了效率。这才是spark生态系统真正强大之处:One stack rule them all。另外sparkSQL+sparkStreaming可以架构当前非常热门的Lambda架构体系,为CEP提供解决方案。也正是如此强大,才吸引了广大开源爱好者的目光,促进了spark生态的高速发展。
九:sparkSQL之调优
spark是一个快速的内存计算框架;同时是一个并行运算的框架。在计算性能调优的时候,除了要考虑广为人知的木桶原理外,还要考虑平行运算的Amdahl定理。
木桶原理又称短板理论,其核心思想是:一只木桶盛水的多少,并不取决于桶壁上最高的那块木块,而是取决于桶壁上最短的那块。将这个理论应用到系统性能优化上,系统的最终性能取决于系统中性能表现最差的组件。例如,即使系统拥有充足的内存资源和CPU资源,但是如果磁盘I/O性能低下,那么系统的总体性能是取决于当前最慢的磁盘I/O速度,而不是当前最优越的CPU或者内存。在这种情况下,如果需要进一步提升系统性能,优化内存或者CPU资源是毫无用处的。只有提高磁盘I/O性能才能对系统的整体性能进行优化。

Amdahl定理,一个计算机科学界的经验法则,因吉恩·阿姆达尔而得名。它代表了处理器平行运算之后效率提升的能力。并行计算中的加速比是用并行前的执行速度和并行后的执行速度之比来表示的,它表示了在并行化之后的效率提升情况。阿姆达尔定律是固定负载(计算总量不变时)时的量化标准。可用公式: 来表示。式中
来表示。式中 分别表示问题规模的串行分量(问题中不能并行化的那一部分)和并行分量,p表示处理器数量。当
分别表示问题规模的串行分量(问题中不能并行化的那一部分)和并行分量,p表示处理器数量。当 时,上式的极限是
时,上式的极限是 ,其中,
,其中, 。这意味着无论我们如何增大处理器数目,加速比是无法高于这个数的。
SparkSQL作为Spark的一个组件,在调优的时候,也要充分考虑到上面的两个原理,既要考虑如何充分的利用硬件资源,又要考虑如何利用好分布式系统的并行计算。由于测试环境条件有限,本篇不能做出更详尽的实验数据来说明,只能在理论上加以说明。
。这意味着无论我们如何增大处理器数目,加速比是无法高于这个数的。
SparkSQL作为Spark的一个组件,在调优的时候,也要充分考虑到上面的两个原理,既要考虑如何充分的利用硬件资源,又要考虑如何利用好分布式系统的并行计算。由于测试环境条件有限,本篇不能做出更详尽的实验数据来说明,只能在理论上加以说明。
1:并行性
SparkSQL在集群中运行,将一个查询任务分解成大量的Task分配给集群中的各个节点来运行。通常情况下,Task的数量是大于集群的并行度。比如前面第六章和第七章查询数据时,shuffle的时候使用了缺省的spark.sql.shuffle.partitions,即200个partition,也就是200个Task:
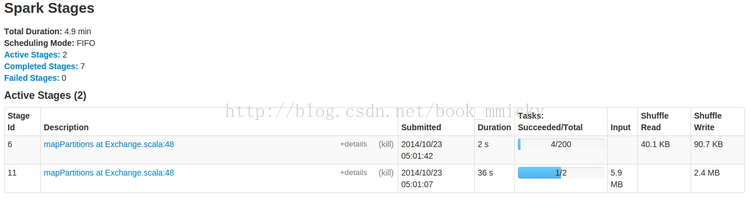
而实验的集群环境却只能并行3个Task,也就是说同时只能有3个Task保持Running:

这时大家就应该明白了,要跑完这200个Task就要跑200/3=67批次。如何减少运行的批次呢?那就要尽量提高查询任务的并行度。查询任务的并行度由两方面决定:集群的处理能力和集群的有效处理能力。
- 对于Spark Standalone集群来说,集群的处理能力是由conf/spark-env中的SPARK_WORKER_INSTANCES参数、SPARK_WORKER_CORES参数决定的;而SPARK_WORKER_INSTANCES*SPARK_WORKER_CORES不能超过物理机器的实际CPU core;
- 集群的有效处理能力是指集群中空闲的集群资源,一般是指使用spark-submit或spark-shell时指定的--total-executor-cores,一般情况下,我们不需要指定,这时候,Spark Standalone集群会将所有空闲的core分配给查询,并且在Task轮询运行过程中,Standalone集群会将其他spark应用程序运行完后空闲出来的core也分配给正在运行中的查询。
综上所述,sparkSQL的查询并行度主要和集群的core数量相关,合理配置每个节点的core可以提高集群的并行度,提高查询的效率。
2: 高效的数据格式
高效的数据格式,一方面是加快了数据的读入速度,另一方面可以减少内存的消耗。高效的数据格式包括多个方面:
2.1 数据本地性
分布式计算系统的精粹在于移动计算而非移动数据,但是在实际的计算过程中,总存在着移动数据的情况,除非是在集群的所有节点上都保存数据的副本。移动数据,将数据从一个节点移动到另一个节点进行计算,不但消耗了网络IO,也消耗了磁盘IO,降低了整个计算的效率。为了提高数据的本地性,除了优化算法(也就是修改spark内存,难度有点高),就是合理设置数据的副本。设置数据的副本,这需要通过配置参数并长期观察运行状态才能获取的一个经验值。
下面是spark webUI监控Stage的一个图:
- PROCESS_LOCAL是指读取缓存在本地节点的数据
- NODE_LOCAL是指读取本地节点硬盘数据
- ANY是指读取非本地节点数据
- 通常读取数据PROCESS_LOCAL>NODE_LOCAL>ANY,尽量使数据以PROCESS_LOCAL或NODE_LOCAL方式读取。其中PROCESS_LOCAL还和cache有关。
2.2 合适的数据类型
对于要查询的数据,定义合适的数据类型也是非常有必要。对于一个tinyint可以使用的数据列,不需要为了方便定义成int类型,一个tinyint的数据占用了1个byte,而int占用了4个byte。也就是说,一旦将这数据进行缓存的话,内存的消耗将增加数倍。在SparkSQL里,定义合适的数据类型可以节省有限的内存资源。
2.3 合适的数据列
对于要查询的数据,在写SQL语句的时候,尽量写出要查询的列名,如Select a,b from tbl,而不是使用Select * from tbl;这样不但可以减少磁盘IO,也减少缓存时消耗的内存。
2.4 更优的数据存储格式
在查询的时候,最终还是要读取存储在文件系统中的文件。采用更优的数据存储格式,将有利于数据的读取速度。查看sparkSQL的stage,可以发现,很多时候,数据读取消耗占有很大的比重。对于sqlContext来说,支持 textFiile、SequenceFile、ParquetFile、jsonFile;对于hiveContext来说,支持AvroFile、ORCFile、Parquet File,以及各种压缩。根据自己的业务需求,测试并选择合适的数据存储格式将有利于提高sparkSQL的查询效率。
3:内存的使用
spark应用程序最纠结的地方就是内存的使用了,也是最能体现“细节是魔鬼”的地方。Spark的内存配置项有不少,其中比较重要的几个是:
- SPARK_WORKER_MEMORY,在conf/spark-env.sh中配置SPARK_WORKER_MEMORY 和SPARK_WORKER_INSTANCES,可以充分的利用节点的内存资源,SPARK_WORKER_INSTANCES*SPARK_WORKER_MEMORY不要超过节点本身具备的内存容量;
- executor-memory,在spark-shell或spark-submit提交spark应用程序时申请使用的内存数量;不要超过节点的SPARK_WORKER_MEMORY;
- spark.storage.memoryFraction spark应用程序在所申请的内存资源中可用于cache的比例
- spark.shuffle.memoryFraction spark应用程序在所申请的内存资源中可用于shuffle的比例
在实际使用上,对于后两个参数,可以根据常用查询的内存消耗情况做适当的变更。另外,在SparkSQL使用上,有几点建议:
- 对于频繁使用的表或查询才进行缓存,对于只使用一次的表不需要缓存;
- 对于join操作,优先缓存较小的表;
- 要多注意Stage的监控,多思考如何才能更多的Task使用PROCESS_LOCAL;
- 要多注意Storage的监控,多思考如何才能Fraction cached的比例更多

4:合适的Task
对于SparkSQL,还有一个比较重要的参数,就是shuffle时候的Task数量,通过spark.sql.shuffle.partitions来调节。调节的基础是spark集群的处理能力和要处理的数据量,spark的默认值是200。Task过多,会产生很多的任务启动开销,Task多少,每个Task的处理时间过长,容易straggle。
5:其他的一些建议
优化的方面的内容很多,但大部分都是细节性的内容,下面就简单地提提:
- 想要获取更好的表达式查询速度,可以将spark.sql.codegen设置为Ture;
- 对于大数据集的计算结果,不要使用collect() ,collect()就结果返回给driver,很容易撑爆driver的内存;一般直接输出到分布式文件系统中;
- 对于Worker倾斜,设置spark.speculation=true 将持续不给力的节点去掉;
- 对于数据倾斜,采用加入部分中间步骤,如聚合后cache,具体情况具体分析;
- 适当的使用序化方案以及压缩方案;
- 善于利用集群监控系统,将集群的运行状况维持在一个合理的、平稳的状态;
- 善于解决重点矛盾,多观察Stage中的Task,查看最耗时的Task,查找原因并改善;
由于时间仓促,本篇在以后的版本再增加一些实例。
来表示。式中分别表示问题规模的串行分量(问题中不能并行化的那一部分)和并行分量,p表示处理器数量。当时,上式的极限是,其中,。这意味着无论我们如何增大处理器数目,加速比是无法高于这个数的。
- 对于Spark Standalone集群来说,集群的处理能力是由conf/spark-env中的SPARK_WORKER_INSTANCES参数、SPARK_WORKER_CORES参数决定的;而SPARK_WORKER_INSTANCES*SPARK_WORKER_CORES不能超过物理机器的实际CPU core;
- 集群的有效处理能力是指集群中空闲的集群资源,一般是指使用spark-submit或spark-shell时指定的--total-executor-cores,一般情况下,我们不需要指定,这时候,Spark Standalone集群会将所有空闲的core分配给查询,并且在Task轮询运行过程中,Standalone集群会将其他spark应用程序运行完后空闲出来的core也分配给正在运行中的查询。
- PROCESS_LOCAL是指读取缓存在本地节点的数据
- NODE_LOCAL是指读取本地节点硬盘数据
- ANY是指读取非本地节点数据
- 通常读取数据PROCESS_LOCAL>NODE_LOCAL>ANY,尽量使数据以PROCESS_LOCAL或NODE_LOCAL方式读取。其中PROCESS_LOCAL还和cache有关。
- SPARK_WORKER_MEMORY,在conf/spark-env.sh中配置SPARK_WORKER_MEMORY 和SPARK_WORKER_INSTANCES,可以充分的利用节点的内存资源,SPARK_WORKER_INSTANCES*SPARK_WORKER_MEMORY不要超过节点本身具备的内存容量;
- executor-memory,在spark-shell或spark-submit提交spark应用程序时申请使用的内存数量;不要超过节点的SPARK_WORKER_MEMORY;
- spark.storage.memoryFraction spark应用程序在所申请的内存资源中可用于cache的比例
- spark.shuffle.memoryFraction spark应用程序在所申请的内存资源中可用于shuffle的比例
- 对于频繁使用的表或查询才进行缓存,对于只使用一次的表不需要缓存;
- 对于join操作,优先缓存较小的表;
- 要多注意Stage的监控,多思考如何才能更多的Task使用PROCESS_LOCAL;
- 要多注意Storage的监控,多思考如何才能Fraction cached的比例更多
- 想要获取更好的表达式查询速度,可以将spark.sql.codegen设置为Ture;
- 对于大数据集的计算结果,不要使用collect() ,collect()就结果返回给driver,很容易撑爆driver的内存;一般直接输出到分布式文件系统中;
- 对于Worker倾斜,设置spark.speculation=true 将持续不给力的节点去掉;
- 对于数据倾斜,采用加入部分中间步骤,如聚合后cache,具体情况具体分析;
- 适当的使用序化方案以及压缩方案;
- 善于利用集群监控系统,将集群的运行状况维持在一个合理的、平稳的状态;
- 善于解决重点矛盾,多观察Stage中的Task,查看最耗时的Task,查找原因并改善;
十:总结
回顾一下,在前面几章中,就sparkSQL1.1.0基本概念、运行架构、基本操作和实用工具做了基本介绍。
基本概念:
- SchemaRDD
- Rule
- Tree
- LogicPlan
- Parser
- Analyzer
- Optimizer
- SparkPlan
- 运行架构:
- sqlContext运行架构
- hiveContext运行架构
- 基本操作
- 原生RDD的操作
- parquet文件的操作
- json文件的操作
- hive数据的操作
- 和其他spark组件混合使用
- 实用工具
- hive/console的操作
- CLI的配置和操作
- ThriftServer的配置和操作
由于时间仓促,有很多地方来不及详细,特别是第三章和第九章;另外还有一些新的特性没有介绍,比如列存储的实现过程、CODEGEN的源码分析等,将在后续的版本逐步完善。
从总体上来说,由于CLI的引入,使得sparkSQL1.1.0在易用性方面得到了极大地提高;而ThriftServer的引入,方便了开发者对基于SparkSQL的应用程序开发;hive/console的引入,极大地方面了开发者对sparkSQL源码的修改和调试;还有json数据的引入,不但扩充了sparkSQL的数据来源,同时对嵌套数据开始做了尝试。从Spark1.1.0开始,sparkSQL逐渐开始像是一个产品了,而不像spark1.0.0,感觉像是一个测试品。当然,由于sparkSQL项目的启动时间比较晚,到现在为止还不到一年,在很多方面还存在着不足:
- SQL-92语法的支持度,sparkSQL使用了一个简单的SQL语法解析器,对于一些复杂的语法没办法解析,比如三个表进行join的时候,不能一次性join,而要通过两两join后再join一次;
- cost model ,虽然sparkSQL的catalyst在最初设计的时候就考虑到了cost model,但在现在的版本还没有引入。我们相信,未来引入cost model之后,sparkSQL的性能将得到进一步地提升;
- 并发性能,从impala得到的信息,sparkSQL的并发性能和impala相比,还是有不少的差距,这将是sparkSQL的一个发展方向。
匆匆忙忙中,sparkSQL1.1入门第一版就先在这里结束吧。特别感谢一下网站或博客提供了相关的知识:















 427
427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









