









 本文详细讲解如何使用Matlab和Python将MNIST数据集转换为LeNet模型所需的leveldb格式,包括数据下载、格式转换以及转换工具的使用方法。
本文详细讲解如何使用Matlab和Python将MNIST数据集转换为LeNet模型所需的leveldb格式,包括数据下载、格式转换以及转换工具的使用方法。
【案例介绍】
LeNet网络模型是一个用来识别手写数字的最经典的卷积神经网络,是Yann LeCun在1998年设计并提出的,是早期卷积神经网络中最有代表性的实验系统之一,其论文是CNN领域第一篇经典之作。本篇博客详细介绍基于Matlab、Python训练lenet手写模型的案例,作为前几次caffe深度学习框架的阶段性总结。
【数据准备】
数据下载地址:http://yann.lecun.com/exdb/mnist/
共有4个文件:

全部下载下来,这样的数据格式并不是caffe支持的数据格式(leveldb/lmdb/hdf5),因此需要对数据格式进行转换。
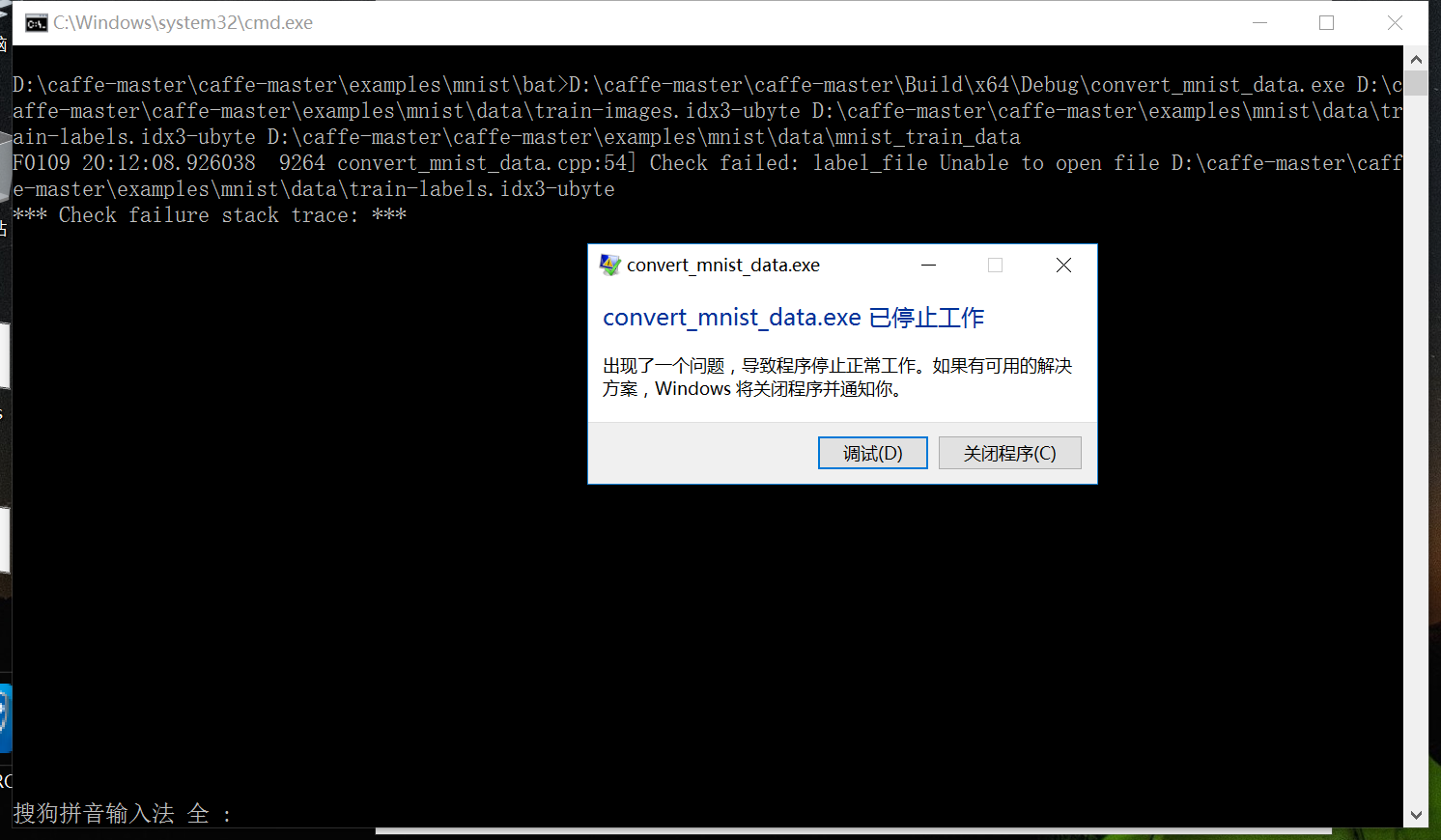
由于是win10系统,尝试了使用convert_mnist_data.exe来执行,可是遇到了如下所示的错误:查阅了很多资料也没有解决,因此决定曲线救国:先将mnist数据集转换成图片格式,然后再将图片转换成leveldb、lmdb或者HDF5格式,这样反而更有普遍意义
如果找到了简单有效的数据转换方法,欢迎大家留言。
【mnist数据转为bmp图片数据】
此处,用到了两个matlab程序,convert_mnist2bmp.m以及convert_mnist2label.m两个文件,下载地址参考下面的百度链接:
链接:http://pan.baidu.com/s/1gfojvFH 密码:iqde
这两个m文件非常简单,很容易就能学会如何使用,它能够把train-images.idx3-ubyte文件解压成bmp图片格式,并将train-labels.idx1-ubyte文件处理为label.txt,处理过程如下:
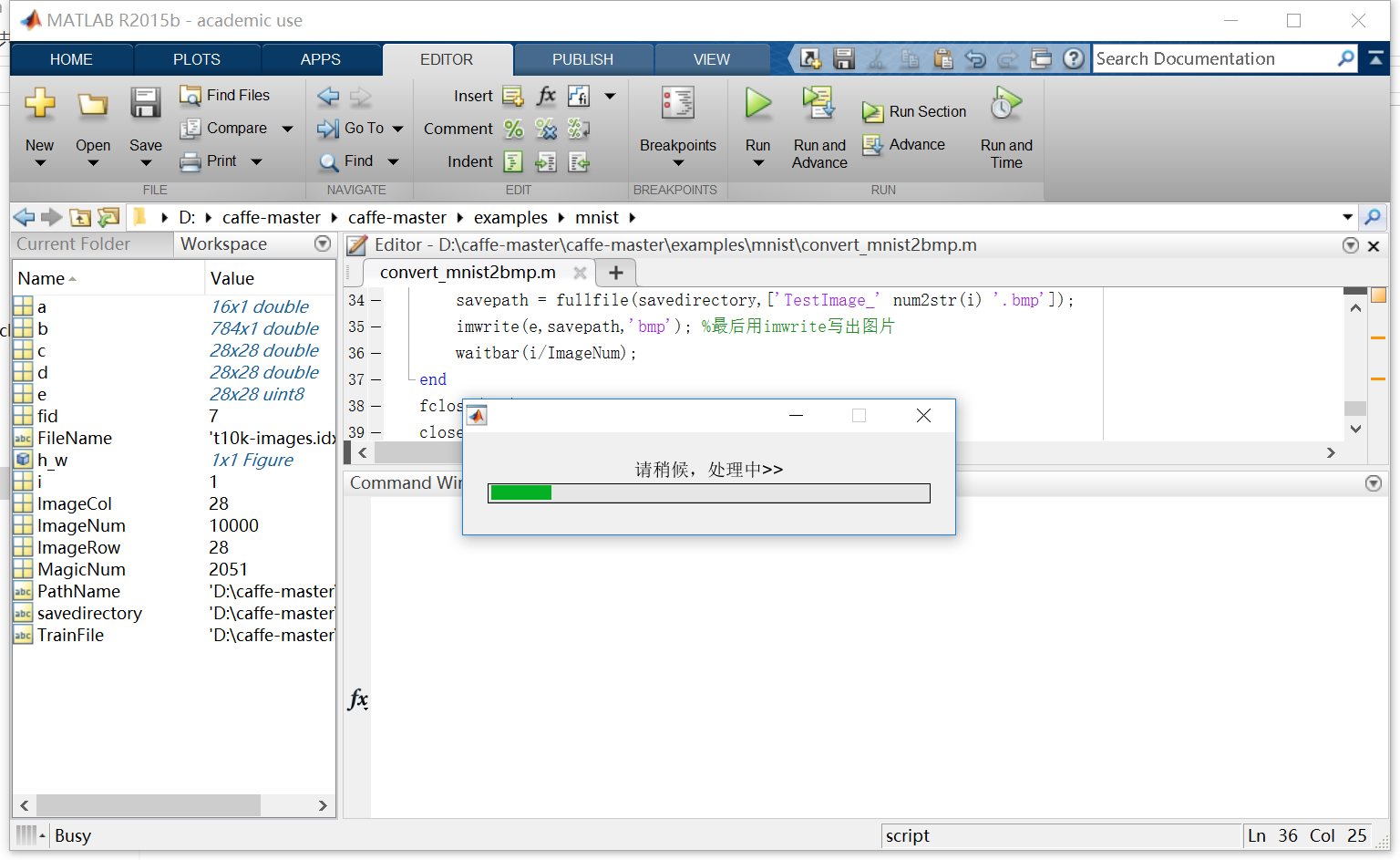
运行完成后,发现训练集共有60000张图片,测试集共有10000张图片,每张图片都是28*28的,我们把训练数据集和测试数据集分别存放在train和test两个文件夹中:

为方便,这里也给出处理之后的train和test数据包下载地址,并包含标签文件以及bmp转leveldb的可执行文件:
链接:http://pan.baidu.com/s/1pLS49OB 密码:f6vs
【mnist图片数据转为leveldb/lmdb格式】
使用Debug下的convert_imageset.exe来转换数据格式。
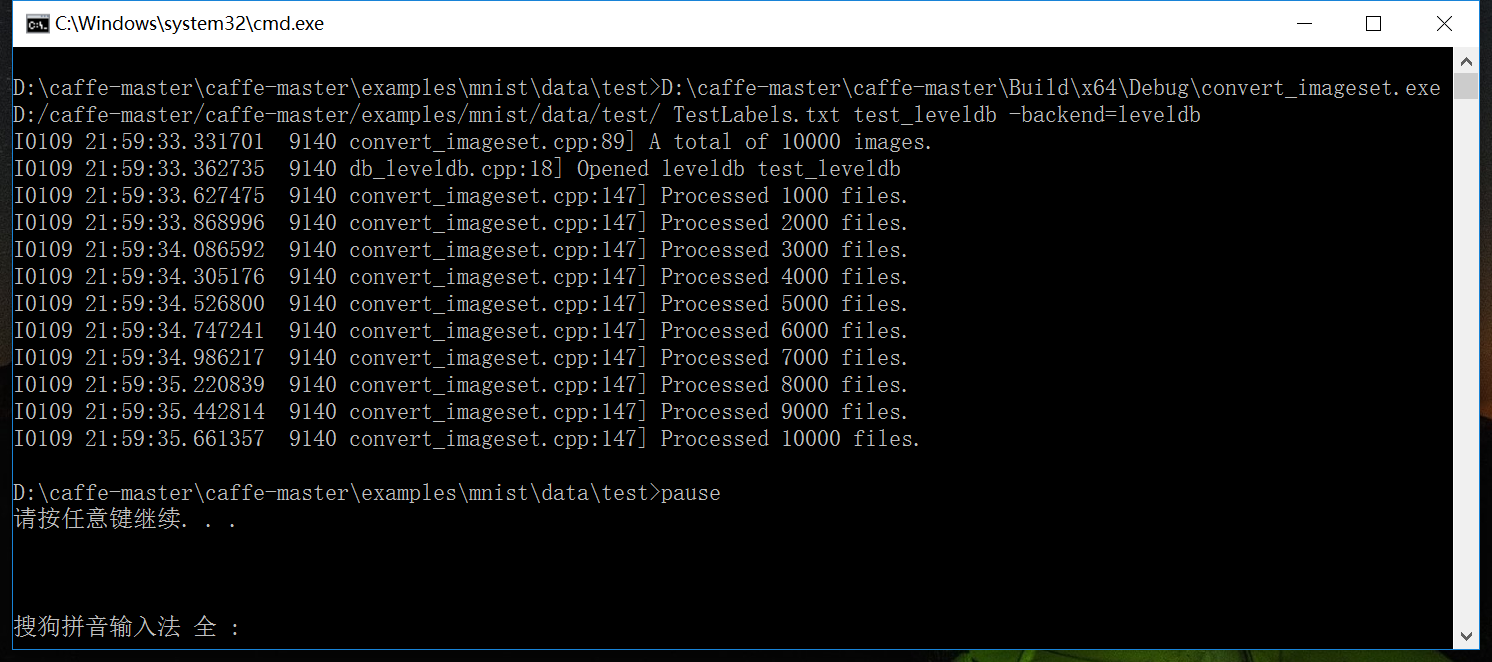
以train数据集为例,trian文件夹中包含60000张图片,以及一个TrainLabels.txt文件,除此之外,再建立一个.bat批处理程序:
D:\caffe-master\caffe-master\Build\x64\Debug\convert_imageset.exe ^
D:/caffe-master/caffe-master/examples/mnist/data/test/ TestLabels.txt test_leveldb -backend=leveldb
pause
(1)调用方式:参考convert_imageset.cpp
// This program converts a set of images to a lmdb/leveldb by storing them
// as Datum proto buffers.
// Usage:
// convert_imageset [FLAGS] ROOTFOLDER/ LISTFILE DB_NAME
//
// where ROOTFOLDER is the root folder that holds all the images, and LISTFILE
// should be a list of files as well as their labels, in the format as
// subfolder1/file1.JPEG 7
// ....
(2)此处要注意!ROOTFOLDER/ LISTFILE之间是有空格的,千万不能忘
(3)resize的使用方法:
convert_imageset.exe --resize_width=32 --resize_height=32 ./test_cifar/ test_label.txt test_leveldb -backend=leveldb
pause
【生成的leveldb数据库】
以训练数据的leveldb数据库为例:
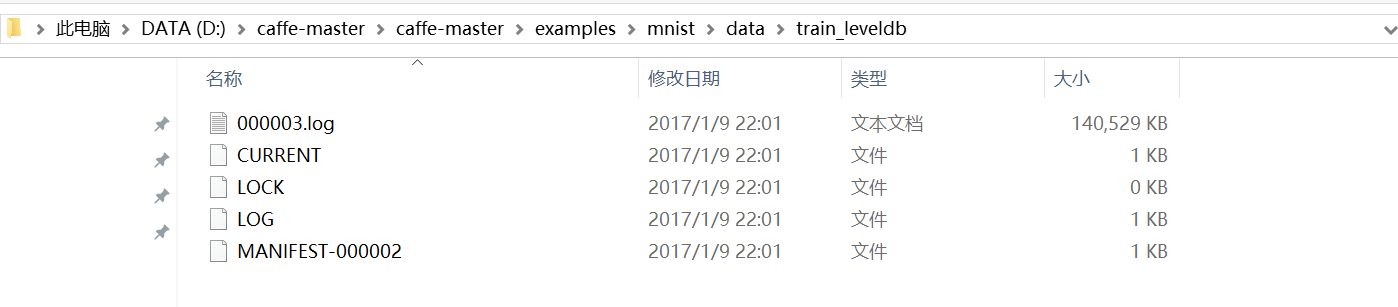
这节先写到这里,本节借mnist的例子主要介绍了如何将自己的图片数据集生成leveldb数据库,我相信这一个方法非常重要;
下面我们将详细介绍基于matlab、Python如何训练LeNet模型,并用于mnist数据集。















 1769
1769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









