







卷积与线性层的不同
- 这是一个卷积大致的流程图,可以看到卷积是对图片在三维层面进行操作,而线性层是展平向量之后进行操作
这里需要注意两个点:
- 卷积运算过程
- 如何计算结果大小
卷积计算过程
卷积是对多通道进行操作的, 以彩色图片作为例子,每个图片的维度是
(
H
∗
W
∗
C
)
(H*W*C)
(H∗W∗C), C就是channel, 为3。计算时卷积核在每个channel滑动计算, 然后将得到的每一层的结果加起来, 就得到channel为1的特征图,即feature map。 那么就有疑问了,卷积不是能改变channel吗,这里把原来为3的变成1了,那如何变为channel为64, 128 这种呢?
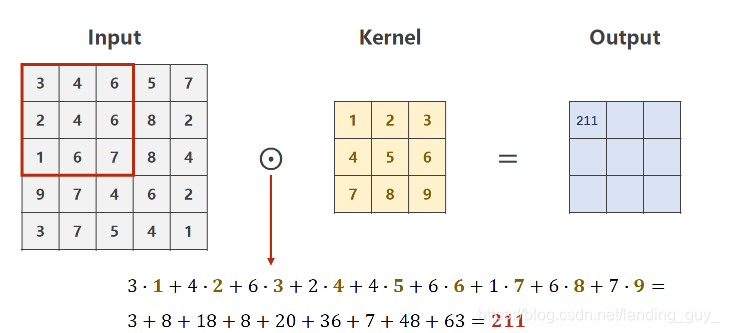
- 这是对一个channel进行操作的图示
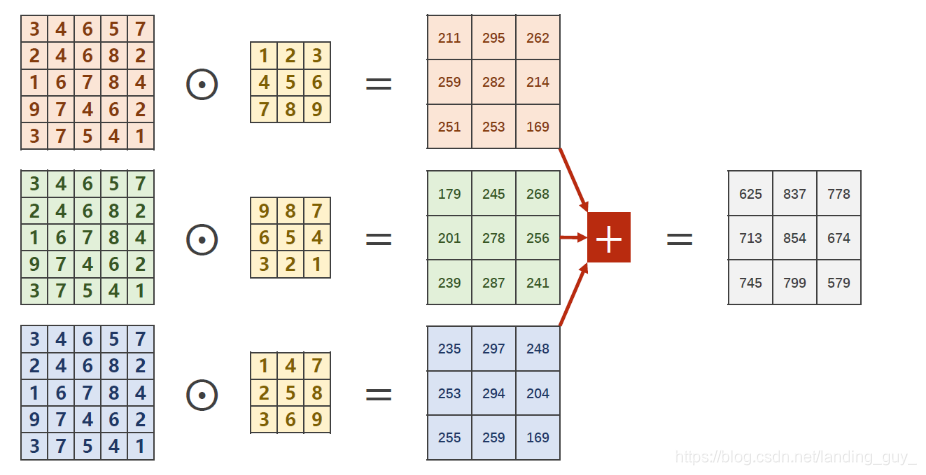
- 这是对3个channel进行操作的例子, stride设为1
这里再对一些细节进行阐述:
- 首先是卷积核, 它的维度是 H ∗ W ∗ C H*W*C H∗W∗C, 注意一般是方形, 也就是 H = W H=W H=W, 然后 C C C与图片通道数相同, 也就是每个通道配个核, 注意每个通道对应的核是不同的, 如上图所示.
- 然后是卷积核的偏置, 一整个卷积核对应一个偏置, 在这里是3个channel的卷积核对应一个偏置, 而不是一个channel对应一个
现在来解答之前的关于feature map的维度问题, 一个卷积核只会把channel变为1, 所以可以使用多个卷积核, 这样就可以变化channel了, 如下图:
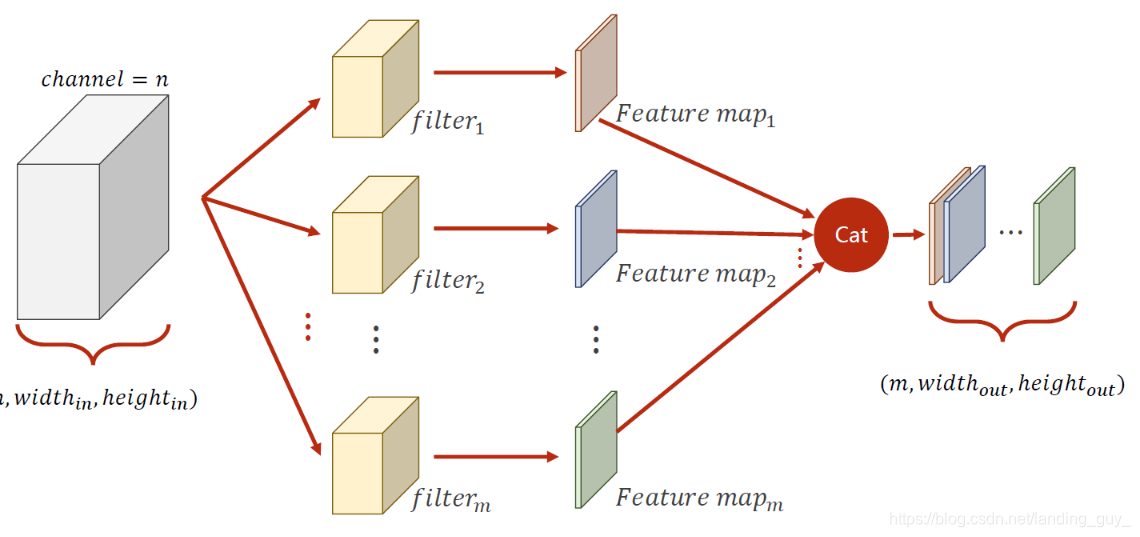
feature map大小计算与pytorch参数
pytorch参数
-
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1,padding=0, dilation=1, groups=1,bias=True, padding_mode=‘zeros’)
-
padding: 设置在所有边界增加 值为 0 的边距的大小(也就是在feature map 外围增加几圈 0 ),例如当 padding =1 的时候,如果原来大小为 3 × 3 ,那么之后的大小为 5 × 5 。即在外围加了一圈 0 。
-
dilation涉及到空洞卷积, 目前还没用到暂且不表
-
padding_mode: 可以分为四类:零填充,常数填充,镜像填充,重复填充。
卷积大小
n
∗
n
n*n
n∗n image
f
∗
f
f*f
f∗f fllter
padding
p
p
p
stride
s
s
s
公式 :
n
+
2
p
−
f
s
+
1
\frac{n+2p-f}{s}+1
sn+2p−f+1
池化
例程
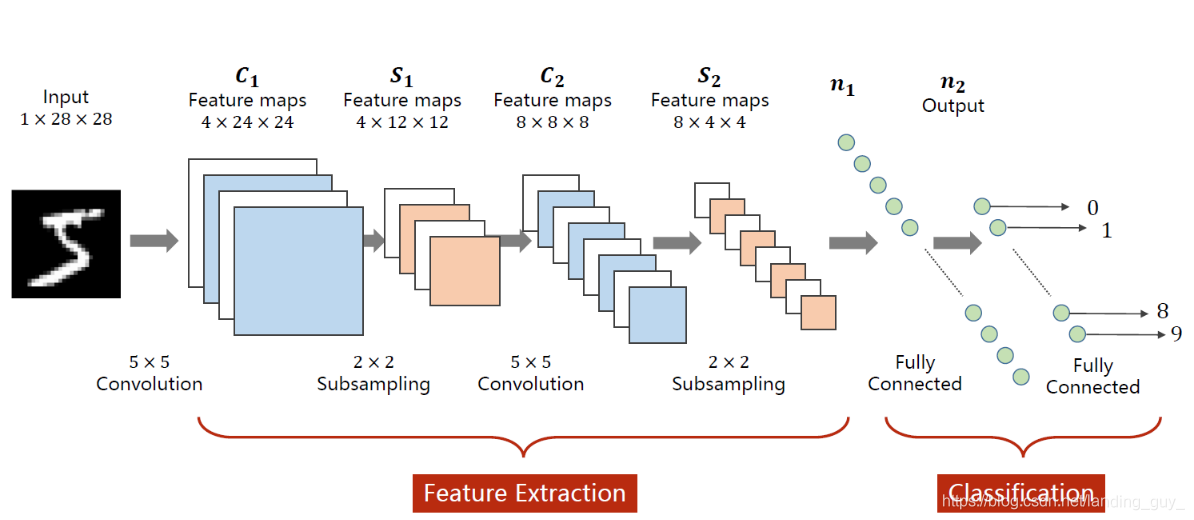
以MNIST为例
# 来训练一下
import torch
from torchvision import datasets, transforms
import numpy
from torch.utils.data import DataLoader
train_data = datasets.MNIST(root='../dataset/mnist', train=True, transform=transforms.ToTensor(), download=True)
test_data = datasets.MNIST(root='../dataset/mnist', train=False, transform=transforms.ToTensor(), download=True)
train_loader = DataLoader(train_data, batch_size=64, shuffle=True, num_workers=2)
test_loader = DataLoader(test_data, batch_size=64 , shuffle=False, num_workers=2)
class CNN_Network(torch.nn.Module):
def __init__(self):
super(CNN_Network, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
# 这时候是batch, 10, 24, 24
self.pooling = torch.nn.MaxPool2d(2)
# 做一个就行, 这时候是batch, 10, 12, 12
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
# 这个输出是batch, 20, 8, 8
self.fc = torch.nn.Linear(320, 10)
self.relu = torch.nn.ReLU()
def forward(self, x):
batch_size = x.shape[0]
x = self.relu(self.conv1(x))
x = self.pooling(x)
x = self.relu(self.conv2(x))
x = self.pooling(x)
x = x.view(batch_size, -1) # 展平为了fc做准备
# 在这里是展成batch,320的状态
x = self.fc(x)
return x # 因为用交叉熵损失所以最后一层不用激活
model = CNN_Network()
criterion = torch.nn.CrossEntropyLoss(reduction='mean') # 这是取平均值的用法
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
def train(epoch):
running_loss = 0
for index, data in enumerate(train_loader):
images, labels = data
y_pred = model(images)
optimizer.zero_grad()
loss = criterion(y_pred, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if index % 300 == 299:
print('epoch:', epoch+1, 'index:', index+1, 'loss:', running_loss/300)
running_loss = 0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
output = model(images)
_, y_pred = torch.max(output, dim=1) # 因为max返回的是两个数,第一个是值,第二个是索引值. 看的是列dim=1
correct += (y_pred == labels).sum().item()
total += labels.size(0)
print('accuracy:', correct/total)
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
print(model())


















 5362
5362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











