







目录
5. GPU编译
本章描述了由nvcc与CUDA驱动协同维护的GPU编译模型。本文介绍了一些技术部分,并在最后给出了具体的示例。
5.1 GPU多代架构
英伟达GPU有多种架构,每个架构都可以独立演化发展。新一代的GPU会在功能或芯片架构上引入重大改进,而相同架构(同代)的GPU模型则会有较小的配置差异,适度影响功能、性能。
跨架构(代)的GPU应用的二进制兼容性是不保证的。
例如:fermi(费米)架构下编译的CUDA应用程序,不太可能在Kepler(开普勒)架构的GPU上运行(反之亦然)。这是因为指令集以及指令编码不同导致的。
同架构(代)的GPU之间在一定条件下是可以保证二进制兼容性的,因为它们共享相同的基础指令集。例如:两款GPU版本之间本无功能差异(其中之一是另外一个的缩小版本);或者一个版本在功能上完全包含另外一个(具体地如Maxwell架构的基础版本sm_52,包含的功能是所有Maxwell架构版本功能的子集,则为sm_52版本编译的任何代码都能在其它Maxwell GPU上运行);
5.2 GPU特性列表
下表展示了当前GPU架构名,并标注了其提供的功能能力。其他诸如寄存器数量,处理器簇数量,仅仅影响执行的性能。
CUDA的命名体系中,对GPU的命名形如:sm_xy。
x表示GPU的代数,y表示当前架构(代)内的版本号。
CUDA通过x1y1 <= x2y2的判断来尝试选取GPU,这样sm_x1y1的GPU所有非ISA(指令集)相关的能力一定被sm_x2y2的GPU包含。
由此,sm_52确实是基础版本的Maxwell模型,它也解释了为什么下表中,较高的项总是对较低项的功能扩展,表中的加号正是表达此语义的。此外,如果我们从指令编码中抽象出来,它意味着sm_52的功能将继续包含在所有后来的GPU中。正如我们接下来将看到的,该属性将是nvcc支持应用程序兼容性的基础。

5.3 应用兼容性
在CPU上,保持二进制代码在CPU上的兼容性,以及维护发布的指令集体系结构兼容性,是确保领域应用程序发行版在新版本的CPU成为主流时,能够运行的通用机制。
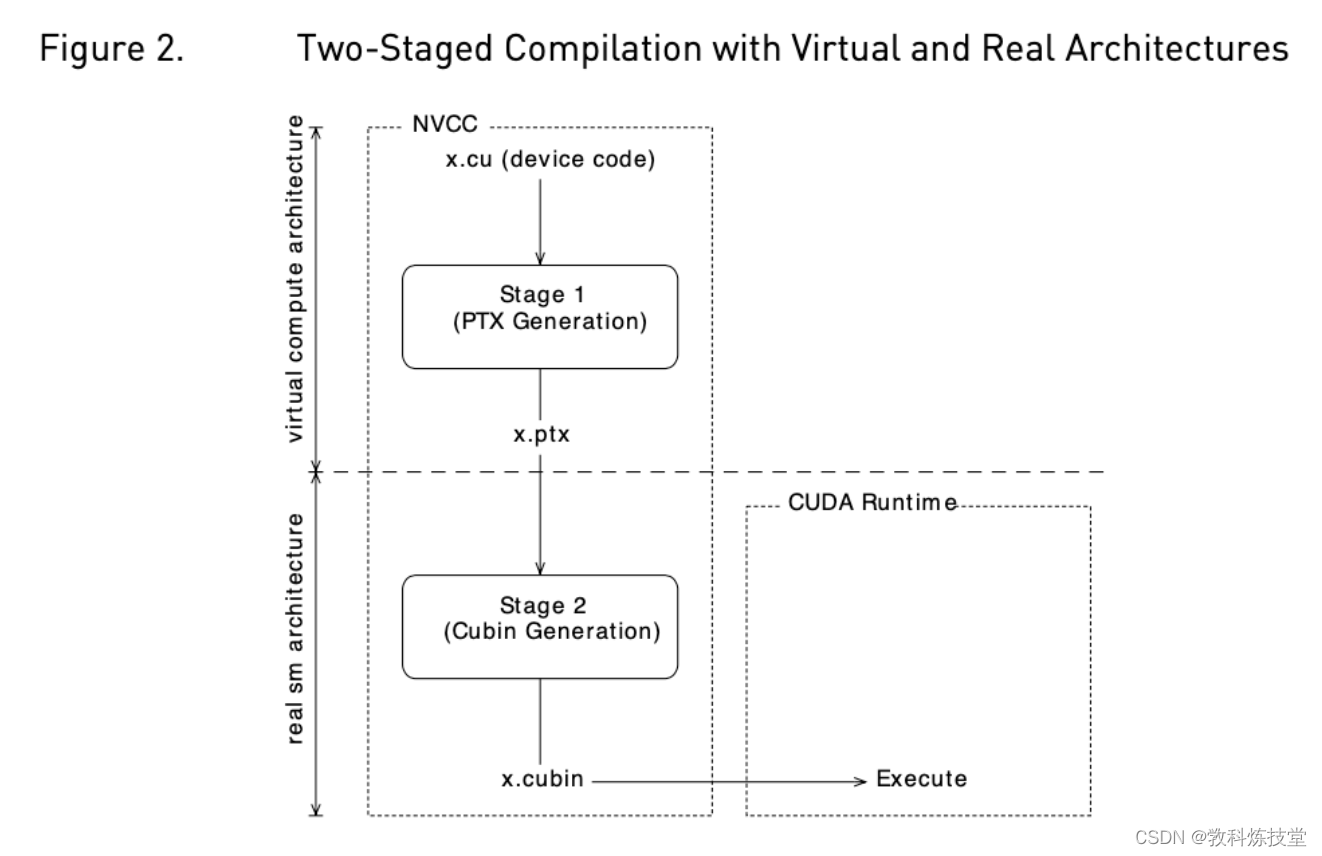
而GPU则不同,因为NVIDIA不保证二进制兼容性,除非牺牲掉GPU迭代改进的机会。相反,正如在图形编程领域中已经存在的传统一样,nvcc依赖于一个两阶段的编译模型 ,来确保领域应用程序与未来的GPU架构的兼容性。
5.4 虚拟架构
GPU编译使用了一种中间码(ptx码)表示形式,它可以被看作是一种虚拟GPU架构的汇编码。
与实际的图形处理器(GPU)相反,这种虚拟GPU完全由它提供给应用程序的一组功能能力或特性来定义。实际上,虚拟GPU架构(很大程度上)提供了通用的指令集,二进制指令的编码并不是问题,因为ptx码是以文本格式表示 。
因此,nvcc编译命令总是使用两个体系架构(两阶段):
- 一个是虚拟的中间体系结构(--gpu-architecture选项)
- 一个是真正的GPU体系架构,指定要执行的处理器(--gpu-code)
为了使这样的nvcc命令生效,真实的体系架构必须是虚拟体系架构的一种实现。下面将对此作进一步解释:
编译所选择的虚拟架构,更多的是对应用程序所需的GPU能力的一种声明:即使用最小能力(范围)的虚拟架构,仍然会使nvcc第二编译阶段可以允许非常广泛的真实架构。反过来讲,指定一个支持某个应用程序未使用特性的虚拟体系架构,则不必要地限制了nvcc第二编译阶段可以使用的GPU(架构)集合。
因而,虚拟架构的选择应该遵循最小适用性原则,这最大化了可以运行的真实GPU集合。真实架构的选择则遵循最大适用性原则,这当然需要对应用程序所要运行的真实GPU有比较好的了解。在just in-time编译的使用场景下,driver层是有这个先验知识的。
5.5 虚拟架构特性列表
| compute_35 compute_37 | Kepler support(开普勒架构) Unified memory programming Dynamic parallelism support |
| compute_50 compute_52 compute_53 | +Maxwell support(麦克斯韦架构) |
| compute_60 compute_61 compute_62 | +Pascal support(帕斯卡尔架构) |
| compute_70 compute_72 | +Volta support(伏打架构) |
| compute_75 | +Turing support(图灵架构) |
| compute_80 compute_86 | +Ampere support(安培架构) |
上表列出了当前定义的虚拟架构。虚拟架构的命名方案与实际架构的命名方案在“5.2章节GPU特性列表”中相同。
5.6 兼容性补全机制
显然,分编译阶段本身无助于实现应用程序与未来的GPU兼容的目标。为此,我们需要CUDA示例中给出的另外两个机制:即时编译(JIT)和fatbinaries(胖二进制)。
5.6.1 即使编译(JIT-Just in time)
到真实GPU(cuda程序)的编译步骤,将代码绑定到了特定一代的GPU。在这一代架构中,它涉及到GPU覆盖率和更高性能之间的折中选择。例如,代码编译到sm_52,允许在所有Maxwell一代架构的gpu上运行,但是如果只以兼容Maxwell GM206以及其后续版本作为唯一目标,那么编译到sm_53可能会产生更好的代码。
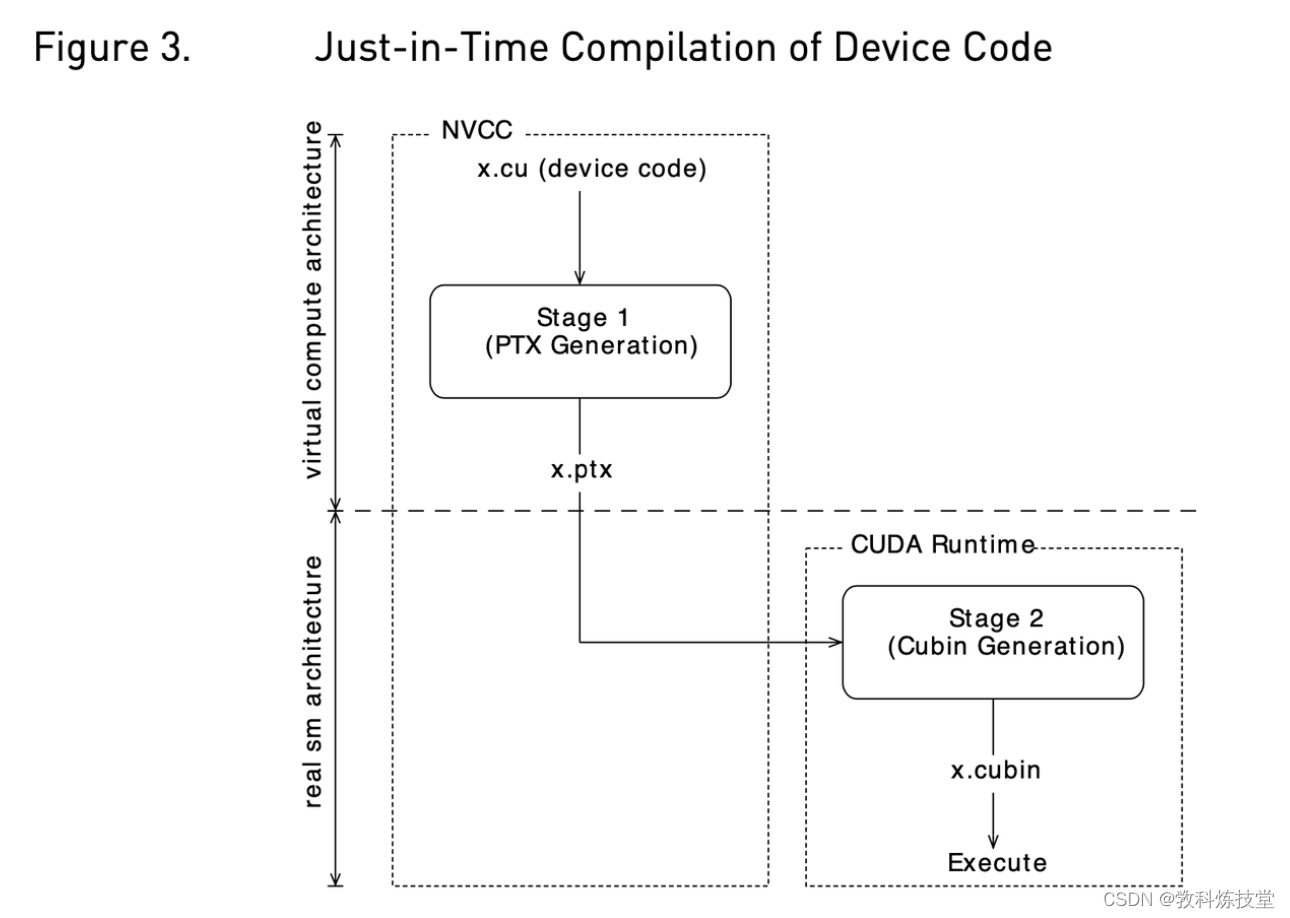
通过指定一个虚拟代码体系结构而不是一个真实的GPU架构,nvcc将延迟对PTX汇编代码的组装,直到应用程序运行时,此时目标GPU是确切已知的。例如,当应用程序在sm_50或更高版本的架构上启动时,下面的命令允许生成精确匹配的GPU二进制代码。
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50--gpu-architecture指定了生成支持的虚拟GPU体系结构的ptx码,控制对输入文件进行预处理和编译以生成特定ptx码的过程;
--gpu-code对生成的ptx码组装成支持的真实的GPU体系结构的二进制,默认不指定该选项时,使用--gpu-architecture的选项值。
如果 --gpu-architecture使用了真实的 GPU 架构的值(例如sm_50),则nvcc使用指定的真实GPU架构(sm_50)以及最接近的虚拟GPU架构(compute_50)作为真实GPU架构(--gpu-code)的选项值。即‘--gpu-architecure=sm_50’等同于‘--gpu-architecture=compute_50, --gpu-code=sm_50,compute_50’
即时编译的缺点是会增加应用启动延迟,但这可以通过让CUDA驱动使用编译缓存来缓解,编译缓存在多次运行应用程序时会持久化下来。(参见“CUDA C++编程指南中 3.1.1.2节即时编译”)。
5.6.2 fatbinaries(胖二进制)
另一种既能克服JIT启动延迟,也允许可执行程序在较新的GPUs上运行的解决方案是:指定生成多个代码实例,例如
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_52这个命令为两个Maxwell虚拟架构的两个变种(真实GPU架构sm_50和sm_52),生成精确的二进制代码,外加ptx码以便在遇到下一代GPU时进行即时编译(JIT)。nvcc将它的设备代码组织在fatbinary二进制文件中,fatbinary可以容纳相同GPU源代码的多个翻译二进制结果。在运行时,当启动device函数时,CUDA驱动程序将选择最合适的翻译二进制。
5.7 nvcc示例
5.7.1 基本符号
NVCC提供了选项 --gpu-architecture和--gpu-code,用于指定两个编译阶段的目标架构。除了下面描述的简写,--gpu-architecture选项接受一个单值,这个值必须是虚拟计算架构的名称,而选项--gpu-code接受一个值列表,这些值必须都是真实gpu的名称,nvcc在编译的第2阶段,每一个真实gpu架构分别执行二进制翻译,并将结果嵌入最终编译结果中(通常是一个主机对象文件.o或可执行文件)。
Example
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_525.7.2 简写
NVCC允许在简单的情况下使用一些简写。
5.7.2.1 简写1
--gpu-code参数可以用来指定虚拟架构。 在这种情况下,对于指定的虚拟架构,阶段2的编译将被省略,而阶段1的PTX码将被嵌入到最终的二进制中。在应用程序启动时,如果驱动程序在二进制中没有找到适配的设备代码,将使用阶段2编译嵌入的PTX码作为输入(即使编译)。
示例
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_525.7.2.2 简写2
--gpu-code选项也可以被省略。 仅在这种情况下,--gpu-architecture值可以是非虚拟架构(可以为真实GPU架构,sm_*)。--gpu-code的选项值默认为由--gpu-architecture指定的GPU实现的最接近的虚拟架构,加上--gpu-architecture选项值。最接近的虚拟架构被赋值给--gpu-architecture。如果--gpu-architecture值是一个虚拟架构(compute-*),则--gpu-code选项直接取值--gpu-architecture。
举例来说:
1) nvcc x.cu --gpu-architecture=sm_52
--gpu-code被省略,sm_52是真实物理架构,最接近的虚拟GPU架构是compute_52
因此等同于:
nvcc x.cu --gpu-architecture=compute_52 --gpu-code=sm_52,compute_52
2) nvcc x.cu --gpu-architecture=compute_50
--gpu-code被省略,compute_50是虚拟架构,因此等同于:
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50 5.7.2.3 简写3
--gpu-architecture和--gpu-code选项都可以省略。
示例
nvcc x.cu
等同于:
nvcc x.cu --gpu-architecture=compute_52 --gpu-code=sm_52,compute_52 5.7.3 扩展符号
选项--gpu-architecture和--gpu-code,被用来生成使用相同虚拟架构的一种或多种真实gpu架构的二进制的情况。对每个指定的真实GPU架构,只会执行一次nvcc编译的阶段1(即预处理和生成虚拟PTX汇编代码),然后重复针对每个真实GPU架构的编译阶段2(二进制代码生成)生成每个真实GPU架构的二进制。
使用一个公共的虚拟架构,意味着所有假定运行的GPU特性对于整个nvcc编译都是固定下来的。例如,下面的nvcc命令,生成的sm_50和sm_53二进制都不会支持半精度浮点运算。
nvcc x.cu --gpu-architecture=compute_50 --gpu-code=compute_50,sm_50,sm_53有时需要对不同的真实GPU架构分部生成二进制,在不同的(虚拟)架构上都进行完整编译。这可以使用nvcc选项--generate-code,替代使用--gpu-architecture和--gpu-code组合的编译过程。
与--gpu-architecture选项不同,--generate-code可以在nvcc命令行上重复。它接受子选项arch和code,它们不能与主选项等价的选项相混淆,虽然行为类似。如果使用了重复架构编译(--generate-code),则设备代码必须使用基于架构标识宏__CUDA_ARCH__值的条件编译,该宏将在下一节中描述。
例如,如下编译的sm_50和sm_52二进制,不支持半精确浮点操作,但sm_53完全支持:
nvcc x.cu \
--generate-code arch=compute_50,code=sm_50 \
--generate-code arch=compute_50,code=sm_52 \
--generate-code arch=compute_53,code=sm_53 或者,将真实GPU架构二进制的生成,留给CUDA驱动程序中的JIT编译器:
nvcc x.cu \
--generate-code arch=compute_50,code=compute_50 \
--generate-code arch=compute_53,code=compute_53
因为没有指定真实物理GPU架构,因而生成了compute_50,compute_53虚拟架构下的ptx码,
cuda driver会在运行时即时编译成真实GPU架构的二进制。因为没有指定真实物理GPU架构,因而生成了compute_50,compute_53虚拟架构下的ptx码,
cuda driver会在运行时即时编译成真实GPU架构的二进制。
此外,code子选项可以支持列表语法,如下:
nvcc x.cu \
--generate-code arch=compute_50,code=[sm_50,sm_52] \
--generate-code arch=compute_53,code=sm_53 5.7.4 虚拟架构标识宏
nvcc在为compute_xy虚拟架构执行编译阶段1时,架构标识宏__CUDA_ARCH__被指定了一个三位数字符串xy0(以常量0结尾)。
该宏可用于cuda(GPU)函数的实现,以确定当前函数会被编译到的虚拟架构。主机侧代码(非gpu代码)不能依赖于它。
关于作者:
犇叔,浙江大学计算机科学与技术专业,研究生毕业,而立有余。先后在华为、阿里巴巴和字节跳动,从事技术研发工作,资深研发专家。主要研究领域包括虚拟化、分布式技术和存储系统(包括CPU与计算、GPU异构计算、分布式块存储、分布式数据库等领域)、高性能RDMA网络协议和数据中心应用、Linux内核等方向。
专业方向爱好:数学、科学技术应用
关注犇叔,期望为您带来更多科研领域的知识和产业应用。
内容坚持原创,坚持干货有料。坚持长期创作,关注犇叔不迷路

















 6517
6517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











