









WAL Practice
在上一篇里已经完成了对于WAL的理论的学习,接下来让我们对于RocksDB中的WAL进行实际操作一番。
Tools for WAL
我是在ubuntu上安装的RocksDB,我采用的编辑器是Clion。如果是在标准的linux操作系统,编译好RocksDB代码后会有一个ldb工具,可以用于查看WAL。
这里具体对于ldb不介绍,之前已介绍过RocksDB相关工具的使用。
Create WAL
创建WAL一共有两种情况:
- 当一个新的数据库被打开
- 当一个列族被flush
Open DB
首先当一个新的DB被打开时,就会创建一个WAL。
s = rocksdb::DB::Open(options, "./db/", &db);
下面我们对源码进行查看。在db_impl_open.cc文件,我们可以看到:DB::Open调用时会传入列族(column_families,以下可能简称CF):
Status DB::Open(const DBOptions& db_options, const std::string& dbname,
const std::vector<ColumnFamilyDescriptor>& column_families,
std::vector<ColumnFamilyHandle*>* handles, DB** dbptr){
const bool kSeqPerBatch = true;
const bool kBatchPerTxn = true;
return DBImpl::Open(db_options, dbname, column_families, handles, dbptr,
!kSeqPerBatch, kBatchPerTxn);
}
当我们打开DB时:
- 在恢复完MANIFEST之后,需要先获取即将创建的WAL 文件编号,即xxx.log
- 为wal文件分配预分配 一个memtale的buffer大小
max_write_buffer_size,如果没有配置该选项,则会将wal可写入的大小定为memtable的4倍。 - 创建wal文件
下面进入DBImpl::Open函数查看,
Status DBImpl::Open(const DBOptions& db_options, const std::string& dbname,
const std::vector<ColumnFamilyDescriptor>& column_families,
std::vector<ColumnFamilyHandle*>* handles, DB** dbptr,
const bool seq_per_batch, const bool batch_per_txn) {
......
s = impl->Recover(column_families, false, false, false, &recovered_seq,
&recovery_ctx);
if (s.ok()) {
uint64_t new_log_number = impl->versions_->NewFileNumber();
log::Writer* new_log = nullptr;
const size_t preallocate_block_size =
impl->GetWalPreallocateBlockSize(max_write_buffer_size);
s = impl->CreateWAL(new_log_number, 0 /*recycle_log_number*/,
preallocate_block_size, &new_log);
......
}
......
}
Flush Column Family
还有一种情况时当一个列族(column_family)被刷新到磁盘之后,也会创建新的WAL。
当column family flush的时候,通过DBImpl::Flush 调用对应cf的memtable flush函数,在flush memtable的过程中进行新的wal的创建。
这里当触发cf的flush时,需要将内存中memtable 标记为immutable-memetable,来进行后台的写入sst文件;同时会生成新的memtable,这个时候wal记录的是旧的memtable的请求,为了数据的隔离性,且wal不会过大,每个wal文件只和一个memtable绑定,所以切换memtable的过程中会创建新的WAL文件,用来接收新的请求。
Status DBImpl::Flush(const FlushOptions& flush_options,
ColumnFamilyHandle* column_family) {
......
Status s;
//执行flush memtable
if (immutable_db_options_.atomic_flush) {
s = AtomicFlushMemTables({cfh->cfd()}, flush_options,
FlushReason::kManualFlush);
} else {
s = FlushMemTable(cfh->cfd(), flush_options, FlushReason::kManualFlush);
}
.......
}
Status DBImpl::FlushMemTable(ColumnFamilyData* cfd,
const FlushOptions& flush_options,
FlushReason flush_reason, bool writes_stopped) {
// This method should not be called if atomic_flush is true.
......
if (flush_reason != FlushReason::kErrorRecoveryRetryFlush &&
(!cfd->mem()->IsEmpty() || !cached_recoverable_state_empty_.load())) {
//通过SwitchMemtable函数来进行memtable的切换
s = SwitchMemtable(cfd, &context);
}
......
}
这种情况下创建新的WAL是通过SwitchMemtable函数。这个函数主要是用来切换memtable,也就是在执行flush之前所做的切换——生成新的memtable,然后把老的刷新到磁盘。查看db_impl_write.cc文件。
Status DBImpl::SwitchMemtable(ColumnFamilyData* cfd, WriteContext* context) {
......
//前面获取到需要创建的wal 文件编号,预分配足够的wal存储空间,那么接下来开始进行对应的文件创建
if (creating_new_log) {
// TODO: Write buffer size passed in should be max of all CF's instead
// of mutable_cf_options.write_buffer_size.
io_s = CreateWAL(new_log_number, recycle_log_number, preallocate_block_size,
&new_log);
}
......
}
通过上面的两个函数我们可以看到每次新建WAL都会有一个new_log_number,这个值就是对应的WAL的文件名前缀,可以看到每次生成新的log_number, 基本都会调用NewFileNumber函数.这里注意如果option设置了recycle_log_file_num的话,是有可能重用老的log_number的。我们先来看下NewFileNumber函数:
uint64_t NewFileNumber() { return next_file_number_.fetch_add(1); }
可以看到函数实现很简单,就是每次log_number加一,因此一般来说WAL的文件格式都是类似0000001.log这样子。
Update WAL
关于WAL的更新部分,主要讲解的时在对memtable 进行flush时的WAL的更新做更为详细的描述。
WAL的更新时上面所说的两种情形,出发cf的flush和达到wal文件大小限制时,此时会发生:
- 新的cf中的数据会刷到的新的SST文件之中,即SwitchMemtable,将当前的memtable变为immutable memtable,然后immutable memtable在后台进行flush
- 创建一个新的WAL文件,之后所有的cf的write请求会优先写入新的WAL之中。在SwitchMemtable中调用CreateWAL。
- 旧的WAL文件会被标记为不可写入,并且在之后会删除(并没有立刻删除,上一篇有讲解删除的过程)。而这个过程就是在CreateWAL中进行的。
下面我们用一个简单的demo进行测试。测试的完整代码会放在后面。
第一次测试思路:首先打开一个db,向两个column family中分别写入四组key-value,然后再触发一次flush,只flush一个CF。
第一次结果预期:在我们第一次flush时应当会存在两个WAL文件,一个时open时自动创建的,一个时我们进行第一次flush时新创建的新的WAL,并且因为我们只进行了一次flush并且数据量较小,所以应该还会有一个sst文件。
因为flush时切换memtable时创建了新的WAL文件,所以新产生的WAL文件应该是空的。之前的数据插入应当被保存在第一个WAL文件中。而又因为我们只flush了cf1,cf0的数据还在内存中,所以第一个WAL的文件是不能被删除的。
s = rocksdb::DB::Open(options, "./dbtest", column_families, &handles, &db);
cout << handles.size() << " open status is : " << s.ToString() << endl;
db->Put(rocksdb::WriteOptions(), handles[1], rocksdb::Slice("key1"), rocksdb::Slice("value1"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key2"), rocksdb::Slice("value2"));
db->Put(rocksdb::WriteOptions(), handles[1], rocksdb::Slice("key3"), rocksdb::Slice("value3"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key4"), rocksdb::Slice("value4"));
db->Flush(rocksdb::FlushOptions(), handles[1]);
运行上述代码后我们进行查看,结果如下:
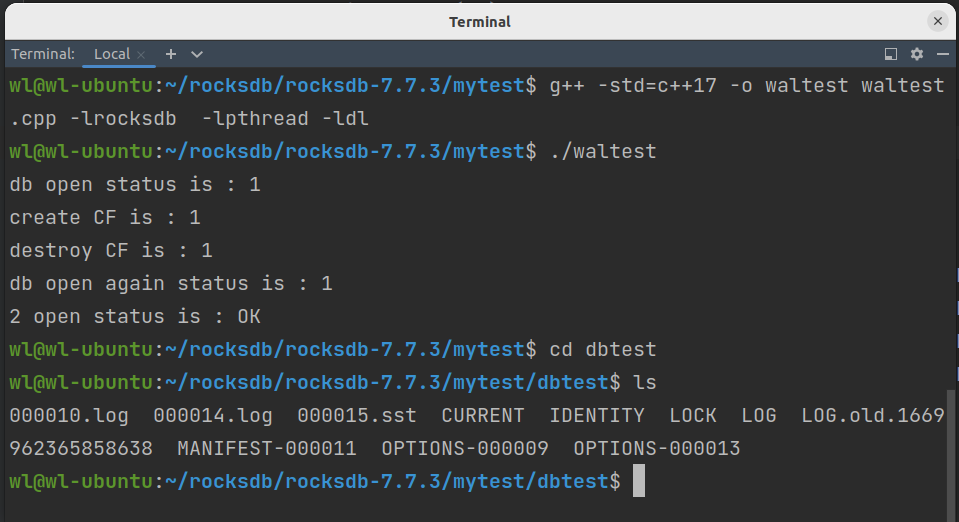
可以看到存在两个log(WAL)文件,一个SST文件。经检查000010.log存在四组kv写入的记录,而000014.log为空。SST中保存了(k1,v1),(k3,v3)的值。结果展示如下。
通过第一次的flush,我们可以了解到测试结果基本如我们所预料。结合相应的源码,我们也弄清了关于WAL文件切换更新的过程。
- 打开db时会创建一个WAL文件
- flush memtable的时候也会创建一个WAL文件,当旧的WAL文件中存在没有被flush的cf的数据时它暂时不会被删除,知道所有的cf的数据都被flush到sst文件中才会被删除。这是正常场景保证数据一直性的WAL实现,接接下来我们进行第二次测试。
第二次测试思路:在第一次测试的基础上进行再一次输入kv,写入未被flush的cf,并进行第二次flush。
第二次结果预测:因为我们进行了两次flush,所以此时应当具有三个WAL文件和两个SST文件。第一个WAL文件记录着第一次实验四组kv(1~4)的写入,由于全部被flush完毕,所以应当被删除。然后第二WAL文件应当记录着cf0新的两组kv(5、6)的写入,由于也被flush完毕,所以也应当被删除了,第三个WAL文件时第二次flush后新产生的,所以应该为空。因此最终只剩下一个log文件。而第一个SST应当包含着四组kv,第二个SST应当时新写入的两组kv。
代码如下:
// key5 and key6 will appear in a new WAL
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key5"), rocksdb::Slice("value5"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key6"), rocksdb::Slice("value6"));
db->Flush(rocksdb::FlushOptions(), handles[0]);
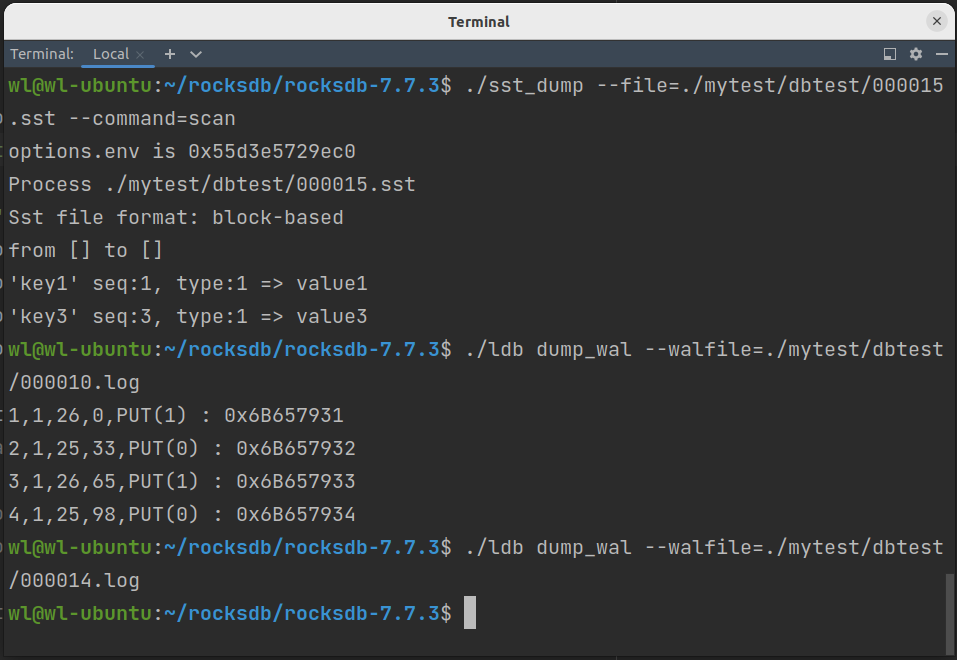
运行上述代码后我们进行查看,结果如下:
 可以看到只存在一个log(WAL)文件,一个SST文件。经检查000016.log为空。000015.sst中保存了(k1,v1),(k3,v3)的值,000017.sst中保存了(k2,v2),(k4,v4),(k5,v5),(k6,v6)。结果展示如下。
可以看到只存在一个log(WAL)文件,一个SST文件。经检查000016.log为空。000015.sst中保存了(k1,v1),(k3,v3)的值,000017.sst中保存了(k2,v2),(k4,v4),(k5,v5),(k6,v6)。结果展示如下。
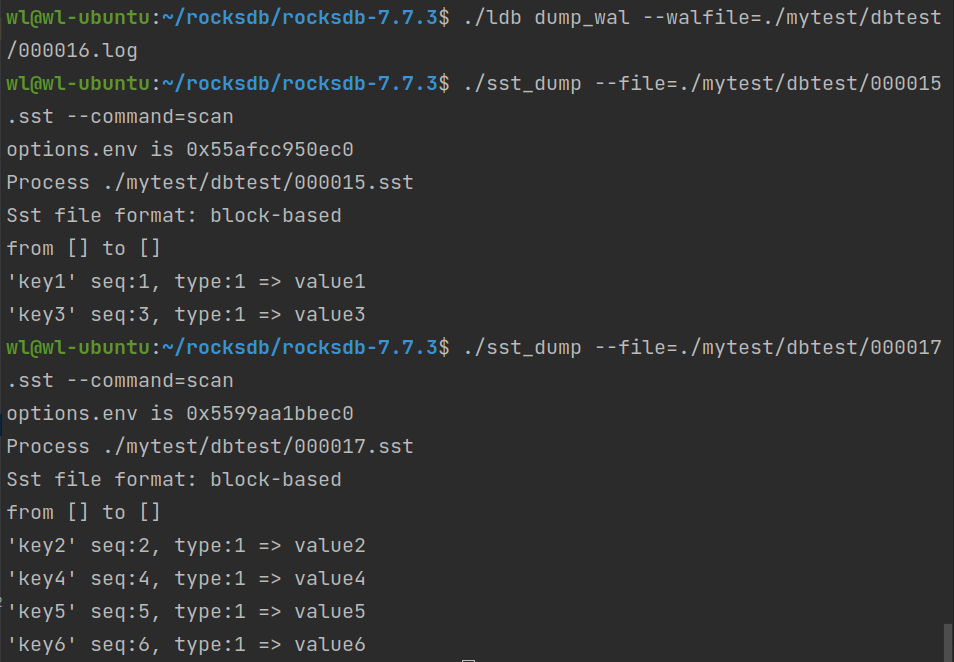
两次测试完毕,结果均如预期所示。下面贴出完整的测试代码:
#include <iostream>
#include <string>
#include <vector>
#include <rocksdb/db.h>
#include <rocksdb/iterator.h>
#include <rocksdb/table.h>
#include <rocksdb/options.h>
using std::cout;
using std::endl;
int main () {
rocksdb::DB* db;
rocksdb::Options options;
rocksdb::Status s;
std::vector<rocksdb::ColumnFamilyDescriptor> column_families;
column_families.push_back(rocksdb::ColumnFamilyDescriptor(
rocksdb::kDefaultColumnFamilyName, rocksdb::ColumnFamilyOptions()));
column_families.push_back(rocksdb::ColumnFamilyDescriptor(
"new_cf", rocksdb::ColumnFamilyOptions()));
std::vector<rocksdb::ColumnFamilyHandle*> handles;
options.create_if_missing = true;
options.max_open_files = -1;
s = rocksdb::DB::Open(options, "./dbtest/", &db);
cout << "db open status is : " << s.ok() << endl;
// create column family
rocksdb::ColumnFamilyHandle* cf;
s = db->CreateColumnFamily(rocksdb::ColumnFamilyOptions(), "new_cf", &cf);
cout << "create CF is : " << s.ok() << endl;
// close DB
s = db->DestroyColumnFamilyHandle(cf);
cout << "destroy CF is : " << s.ok() << endl;
//delete db;
s = rocksdb::DB::Open(options, "./dbtest", column_families, &handles, &db);
cout << "db open again status is : " << s.ok() << endl;
cout << handles.size() << " open status is : " << s.ToString() << endl;
db->Put(rocksdb::WriteOptions(), handles[1], rocksdb::Slice("key1"), rocksdb::Slice("value1"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key2"), rocksdb::Slice("value2"));
db->Put(rocksdb::WriteOptions(), handles[1], rocksdb::Slice("key3"), rocksdb::Slice("value3"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key4"), rocksdb::Slice("value4"));
db->Flush(rocksdb::FlushOptions(), handles[1]);
// key5 and key6 will appear in a new WAL
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key5"), rocksdb::Slice("value5"));
db->Put(rocksdb::WriteOptions(), handles[0], rocksdb::Slice("key6"), rocksdb::Slice("value6"));
db->Flush(rocksdb::FlushOptions(), handles[0]);
delete db;
return 0;
}
运行指令如下:
wl@wl-ubuntu:~/rocksdb/rocksdb-7.7.3/mytest$ g++ -std=c++17 -o waltest waltest.cpp -lrocksdb -lpthread -ldl
wl@wl-ubuntu:~/rocksdb/rocksdb-7.7.3/mytest$ ./waltest
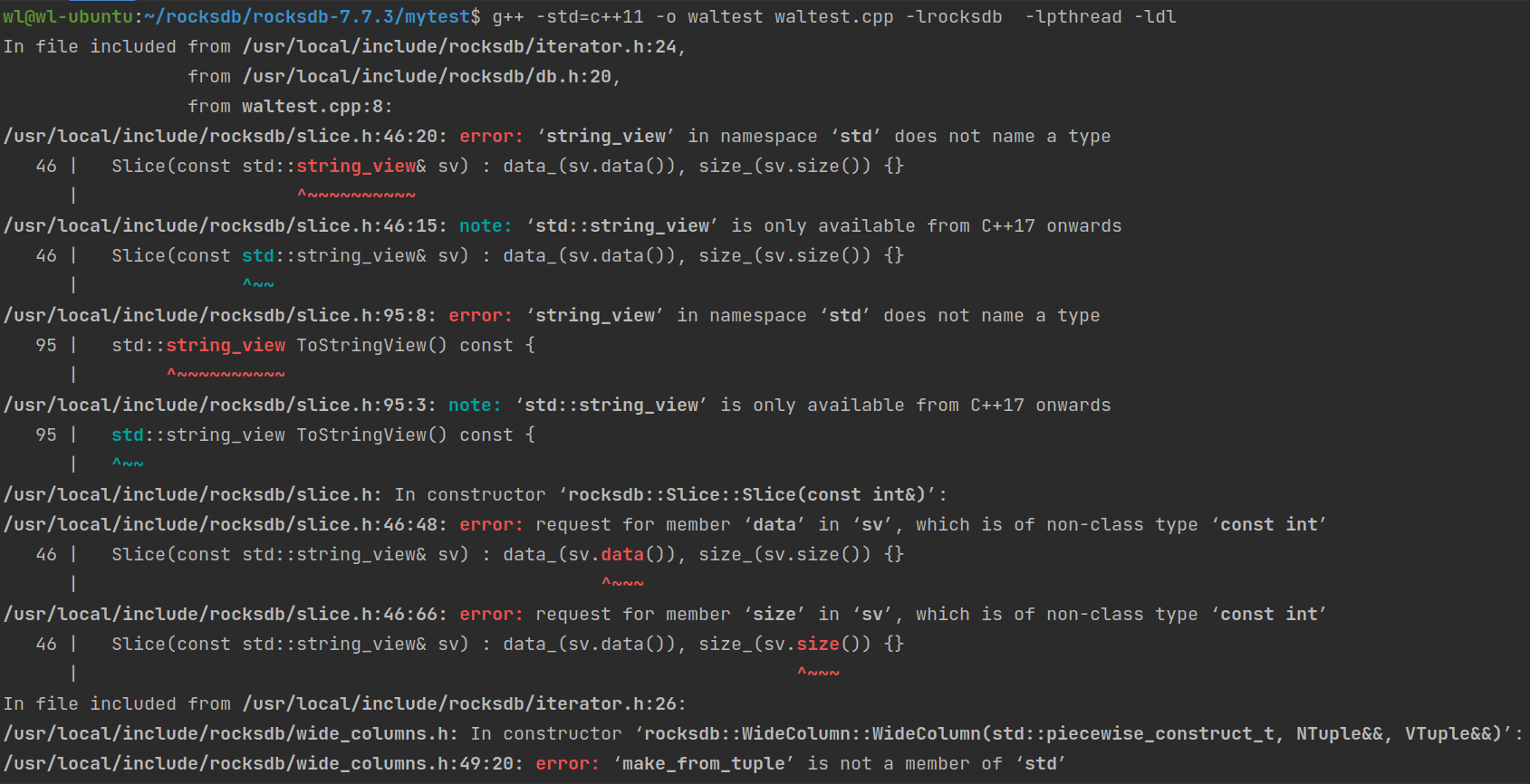
注意,我看到很多人在介绍运行指令是所用的都是C++11这个版本。但当我实际操作时发现会出现类似“‘string_view’ in namespace ‘std’ does not name a type”这种报错。经我查阅这是C++版本的问题,只需要将C++版本从11换成17即可。C++11具体报错贴图如下:
Recover WAL
在之前我们就有这样学习过,RocksDB对于WAL的恢复时提供了可供调整的四种WAL Recovery模式。这里简单解释一下:
- kAbsoluteConsistency
这种级别是对一致性要求最高的级别,不允许有任何的IO错误,不能出现一个record的丢失。 - kTolerateCorruptedTailRecords
这个级别是允许丢失一部分数据,会忽略一些在wal末尾写入失败的请求,数据异常仅限于log文件末尾写入失败。如果出现了其他的异常,都无法进行数据重放。 - kPointInTimeRecovery
这个级别也是现在rocksdb默认的recovery mode,当遇到IO error的时候会停止重放,将出现异常之前的所有数据进行完成重放。 - kSkipAnyCorruptedRecords
这个级别是一致性要求最低的,会忽略所有的IO error,尝试尽可能多得恢复数据。一般用于灾难性丢失的恢复。
在文件options.h中,对于这四种模式是这样声明的:
enum class WALRecoveryMode : char {
// Original levelDB recovery
// We tolerate the last record in any log to be incomplete due to a crash // Use case: Applications for which updates, once applied, must not be
// rolled back even after a crash-recovery.
kTolerateCorruptedTailRecords = 0x00,
// Recover from clean shutdown
// We don't expect to find any corruption in the WAL
// Use case : This is ideal for unit tests and rare applications that
// can require high consistency guarantee
kAbsoluteConsistency = 0x01,
// Recover to point-in-time consistency (default)
// We stop the WAL playback on discovering WAL inconsistency
// Use case : Ideal for systems that have disk controller cache like
// hard disk, SSD without super capacitor that store related data
kPointInTimeRecovery = 0x02,
// Recovery after a disaster
// We ignore any corruption in the WAL and try to salvage as much data as
// possible
// Use case : Ideal for last ditch effort to recover data or systems that
// operate with low grade unrelated data
kSkipAnyCorruptedRecords = 0x03,
};
因此通过上述配置,我们可以通过option选项Options.wal_recovery_mode = 2来进行相应模式的配置。
接下来我们来仔细查看一下每一种Recovery Mode时如何实现各自的Recovery的级别的。
当我们打开db调用Recovery时,如果db已经存在,RocksDB会尝试从已经存在的db中的log文件来恢复上一次的memtable数据:
详细的过程如下:
- 读取存在的每一个log文件,循环进行如下操作
- 创建一个WAL文件的file_reader
- 利用file_reader创建一个log reader,并利用wal_recovery_mode参与到log reader的初始化
- 在具体的ReadRecord中进行对应的Recovery Mode区分
在源文件db_impl_open.cc中,可以查看到函数c RecoverLogFiles定义如下:
Status DBImpl::RecoverLogFiles(const std::vector<uint64_t>& wal_numbers,
SequenceNumber* next_sequence, bool read_only,
bool* corrupted_wal_found,
RecoveryContext* recovery_ctx) {
......
//遍历所有的wal record,wal_numbers为所有wal的log文件列表
//这个函数可以处理多个wal文件,wal文件列表记录在参数wal_numbers中
//这个循环遍历所有的wal_numbers
for (auto wal_number : wal_numbers) {
......
//先得到wal文件名,在使用SequentialFileReader打开wal文件,再使用这个reader构造log::Reader
std::string fname =
LogFileName(immutable_db_options_.GetWalDir(), wal_number);
......
//Create the file_reader
std::unique_ptr<SequentialFileReader> file_reader;
{
std::unique_ptr<FSSequentialFile> file;
status = fs_->NewSequentialFile(fname, fs_->OptimizeForLogRead(file_options_), &file,nullptr);
......
file_reader.reset(new SequentialFileReader(
std::move(file), fname, immutable_db_options_.log_readahead_size,
io_tracer_));
}
......
// Create the log reader
log::Reader reader(immutable_db_options_.info_log, std::move(file_reader),
&reporter, true /*checksum*/, wal_number);
}
......
//循环处理所有的record,每次循环处理一个record
while (!stop_replay_by_wal_filter &&
reader.ReadRecord(&record, &scratch,
immutable_db_options_.wal_recovery_mode,
&record_checksum) &&
status.ok()) {
......
if (immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kPointInTimeRecovery) {
if (sequence == *next_sequence) {
stop_replay_for_corruption = false;
}
if (stop_replay_for_corruption) {
logFileDropped();
break; }
}
//解析record并把其中的kv组装成batch
WriteBatch batch;
......
}
}
......
}
所以我们接下来需要进入到ReadRecord中,从物理Record中读取数据发生异常时,如果想要上报异常,我们都需要确认当前Recovery Mode是最高一致性kAbsoluteConsistency的时候才会进行上报。
在log_reader.cc文件中查看ReadRecord函数定义:
bool Reader::ReadRecord(Slice* record, std::string* scratch,
WALRecoveryMode wal_recovery_mode,
uint64_t* record_checksum) {
uint64_t physical_record_offset = end_of_buffer_offset_ - buffer_.size();
size_t drop_size = 0;
// 会从物理的record中读取数据,将读取过程中发生的异常返回给record_type
const unsigned int record_type = ReadPhysicalRecord(&fragment, &drop_size);
......
switch (record_type) {
......
//接下来通过不同的recovery mode来针对异常的record_type 进行处理,决定是否需要返回数据异常
//当出现 header,eof(log末尾),kOldRecord(和eof异常类似)异常时都会 确认recovery mode是否是 kAbsoluteConsistency
//是的话直接report异常
case kBadHeader:
if (wal_recovery_mode == WALRecoveryMode::kAbsoluteConsistency) {
// in clean shutdown we don't expect any error in the log files
ReportCorruption(drop_size, "truncated header");
}
......
case kEof:
if (in_fragmented_record) {
if (wal_recovery_mode == WALRecoveryMode::kAbsoluteConsistency) {
// in clean shutdown we don't expect any error in the log files
ReportCorruption(scratch->size(), "error reading trailing data");
}
......
case kOldRecord:
if (wal_recovery_mode != WALRecoveryMode::kSkipAnyCorruptedRecords) {
//如果是跳过所有异常的话,不会report corruption
// Treat a record from a previous instance of the log as EOF.
if (in_fragmented_record) {
if (wal_recovery_mode == WALRecoveryMode::kAbsoluteConsistency) {
// in clean shutdown we don't expect any error in the log files
ReportCorruption(scratch->size(), "error reading trailing data");
}
// This can be caused by the writer dying immediately after
// writing a physical record but before completing the next; don't
// treat it as a corruption, just ignore the entire logical record.
scratch->clear();
}
return false;
}
}
紧接着我们重新回到RecoverLogFiles函数之中,在处理完Record之后,后续还会有将重放后的数据写入memtable的过程。
当完成所有的读取和写入memtable之后,会对所有的返回状态进行确认,因为之上所有的操作都是在重放wal,可能会有失败的情况。
接下来进入如下的逻辑,根据重放后的状态进行后续的recovery操作(以下将immutable_db_options_.wal_recovery_mode用mode来代替)
- 如果mode是 kSkipAnyCorruptedRecords ,则跳过所有的异常,直接返回OK
- 如果mode是 kPointInTimeRecovery 或者 kTolerateCorruptedTailRecords 则会暂停处理,将stop_replay_for_corruption 置为true, 后续会跳过当前的log number进行重放
- 如果是kAbsoluteConsistency 或者 kTolerateCorruptedTailRecords 则直接返回
if (immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kSkipAnyCorruptedRecords) { // 如果rev
// We should ignore all errors unconditionally
status = Status::OK();
} else if (immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kPointInTimeRecovery) {
// We should ignore the error but not continue replaying
status = Status::OK();
stop_replay_for_corruption = true;
corrupted_log_number = log_number;
ROCKS_LOG_INFO(immutable_db_options_.info_log,
"Point in time recovered to log #%" PRIu64
" seq #%" PRIu64,
log_number, *next_sequence);
} else {
assert(immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kTolerateCorruptedTailRecords ||
immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kAbsoluteConsistency);
return status;
}
// 主要是对kPointInTimeRecovery 和 kTolerateCorruptedTailRecords进行恢复处理
// 将corrupted_log_number 之前所有数据完成恢复,再报告异常
if (stop_replay_for_corruption == true &&
(immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kPointInTimeRecovery ||
immutable_db_options_.wal_recovery_mode ==
WALRecoveryMode::kTolerateCorruptedTailRecords)) {
for (auto cfd : *versions_->GetColumnFamilySet()) {
if (cfd->GetLogNumber() > corrupted_log_number) {
ROCKS_LOG_ERROR(immutable_db_options_.info_log,
"Column family inconsistency: SST file contains data"
" beyond the point of corruption.");
return Status::Corruption("SST file is ahead of WALs");
}
}
}
Write to WAL
接下来我们补充一下WAL文件时如何在写入memtable之前旧写入的,又是如何进行更新的。
还是通过用户接口Put,该接口会调用到底层的Status DBImpl::WriteImpl,在该函数中,如果我们开启来pipeline,则会走pipeline的写入逻辑。如果未开启pipeline,则会正常写入。
pipeline是流水线的意思,可以类比成指令流水线的思想。
在源文件db_impl_open.cc中,WriteToWAL的函数入口如下:
io_s =
WriteToWAL(write_group, log_context.writer, log_used,
log_context.need_log_sync, log_context.need_log_dir_sync,
last_sequence + 1, log_file_number_size);
因为实际写入的过程中可能多个客服端会并发调用put,而每一个put都会有自己的writer,为了提高写性能,会从多个writer中选出来一个leader,让这个leader将所有要写的wal收集到一块,进行batch写入,其他从writer等待leader写完之后在并发写入memtable。
所以以上WriteToWAL内部调用了一个重载 了batch写的wal函数。
WriteBatch* merged_batch;
io_s = status_to_io_status(MergeBatch(write_group, &tmp_batch_, &merged_batch,
&write_with_wal, &to_be_cached_state));
......
uint64_t log_size;
io_s = WriteToWAL(*merged_batch, log_writer, log_used, &log_size,
write_group.leader->rate_limiter_priority,
log_file_number_size);
if (to_be_cached_state) {
cached_recoverable_state_ = *to_be_cached_state;
cached_recoverable_state_empty_ = false;
}
所以进入到实际执行(也就是重寫的)的WriteToWAL函数内部,会调用AddRecord函数执行实际的write。
IOStatus DBImpl::WriteToWAL(const WriteBatch& merged_batch,
log::Writer* log_writer, uint64_t* log_used,
uint64_t* log_size,
Env::IOPriority rate_limiter_priority,
LogFileNumberSize& log_file_number_size) {
......
//調用AddRecord
IOStatus io_s = log_writer->AddRecord(log_entry, rate_limiter_priority);
......
}
这里会用到文件系统的write接口,选择的文件系统是在db open的时候 进行DBImpl类初始化,根据env传入的参数进行文件系统的选择, 在fs_posxi.cc文件中,我們可以看到默认是PosixFileSystem。
std::shared_ptr<FileSystem> FileSystem::Default() {
STATIC_AVOID_DESTRUCTION(std::shared_ptr<FileSystem>, instance)
(std::make_shared<PosixFileSystem>());
return instance;
}
在AddRecord函数中将之前合并好的 log_enery,每次写入大小不能超过11bytes,这个是WAL的具体约定的格式了。通过文件系统接口进行Append写入,直到把log_entry完全写入。
IOStatus Writer::AddRecord(const Slice& slice,
Env::IOPriority rate_limiter_priority) {
......
do {
......
s = dest-->Append(Slice("\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00",
static_cast<size_t>(leftover)));
......
}while(s.ok() && left > 0);
......
}
因为我们没有配置direct,则最终通过
Flush -->WriteBuffered–> PosixWritableFile::Append --> PosixWrite --> write 直到底层的 write系统调用,进行写入。
其实这个写入链路还是比较长,不过耗时的话中间仅仅是做一些字符串的拼接,到write这里才是耗时所在。因为,还要走一遍庞大的内核文件系统的写入链路,这里也能够理解为什么ceph需要单独再做一个小型的文件系统来代替内核文件系统了。
写WAL是我们整个rocksdb写入最为耗时的一段,memtable的写入是在WAL写完成之后才能写入,而memtable都是纯内存操作,所以写入操作的耗时还是消耗在了写WAL之上,在传统的xfs之上,一个200bytes的请求,写WAL耗时大概2-4us。
为了保证WAL能够落盘,我们还需要配置options.sync=true,在WriteToWAL函数中,完成了文件系统的写入之后 会调用fsync来进行 sync写。
Delete WAL
DeleteObsoleteFiles
WAL的删除只有当包含在此WAL中的所有的数据都已经被持久化为SST之后(也有可能会延迟删除,因为有时候需要master发送transcation Log到slave来回放)。
首先在Status DBImpl::Open中会调用DeleteObsoleteFiles函数:
Status DBImpl::Open(const DBOptions& db_options, const std::string& dbname,......) {
......
TEST_SYNC_POINT("DBImpl::Open:Opened");
Status persist_options_status;
if (s.ok()) {
......
*dbptr = impl;
impl->opened_successfully_ = true;
impl->DeleteObsoleteFiles();
TEST_SYNC_POINT("DBImpl::Open:AfterDeleteFiles");
impl->MaybeScheduleFlushOrCompaction();
}
......
}
在DeleteObsoleteFiles函数则调用了两个非常重要的删除函数FindObsoleteFiles和PurgeObsoleteFiles:
void DBImpl::DeleteObsoleteFiles() {
......
JobContext job_context(next_job_id_.fetch_add(1));
FindObsoleteFiles(&job_context, true);
mutex_.Unlock();
if (job_context.HaveSomethingToDelete()) {
bool defer_purge = immutable_db_options_.avoid_unnecessary_blocking_io;
PurgeObsoleteFiles(job_context, defer_purge);
}
.......
}
FindObsoleteFiles
在WAL的删除中这个函数的主要功能时扫描需要删除的文件,然后交给PurgeObsoleteFiles删除。如果rocksdb构建checkpoint的时候,会在这个函数里面直接return。
这个函数会在全局锁的保护范围内,所以这个函数不能做太重的事情,否则会影响rocksdb的读写性能
rocksdb默认6个小时会扫描db的全量文件,这个全局扫描在文件数特别多场景下会有性能问题。
经测试,当文件数达到百万级别的时候耗时就非常大了,所以不推荐单个rocksdb存储特别多的数据,当然可以通过调整文件大小来减少文件数,但是这样做也会有其他的性能问题。
至于FindObsoleteFiles函数为什么要全量扫描文件,猜测可能更多的是为了防止代码出现bug导致文件不能被删除。
同时在这个函数里面会获取每个cf最小的log文件号,然后判断logs_和alive_log_files_里面是否有文件需要删除。
在源文件db_impl_files.cc中我们先来看DBImpl::FIndObsoleteFiles函数。这个函数很长,我们只关注对应的WAL部分,这里逻辑很简单,就是遍历所有的WAL,然后找出log_number小于当前min_log_number的文件然后加入到对应的结构(log_delete_files)。
if (!alive_log_files_.empty() && !logs_.empty()) {
uint64_t min_log_number = job_context->log_number;
size_t num_alive_log_files = alive_log_files_.size();
// 查看最新的过时日志文件
while (alive_log_files_.begin()->number < min_log_number) {
auto& earliest = *alive_log_files_.begin();
if (immutable_db_options_.recycle_log_file_num >
log_recycle_files_.size()) {
ROCKS_LOG_INFO(immutable_db_options_.info_log,
"adding log %" PRIu64 " to recycle list\n",
earliest.number);
log_recycle_files_.push_back(earliest.number);
} else {
job_context->log_delete_files.push_back(earliest.number);
}
......
}
while (!logs_.empty() && logs_.front().number < min_log_number) {
auto& log = logs_.front();
if (log.IsSyncing()) {
log_sync_cv_.Wait();
// logs_ could have changed while we were waiting.
continue;
}
logs_to_free_.push_back(log.ReleaseWriter());
logs_.pop_front();
}
// 当前的日志文件不可能过时
assert(!logs_.empty());
}
这里可以看到有两个核心的数据结构alive_log_files和logs_,他们的区别就是前一个只表示有写入的WAL,而后一个则是包括了所有的WAL(比如open一个DB,而没有写入数据,此时也会生成WAL)。
最终删除WAL的操作是在DBImpl::DeleteObsoleteFileImpl这个函数。而WAL删除不会单独触发,而是和temp/sst这类文件一起被删除的(PurgeObsoleteFiles)。
PurgeObsoleteFiles
在FindOnsoleteFiles函数中,构造好的job_context传出到清理函数PurgeObsoleteFiles即可。
这个函数主要执行最终的删除,会二次校验文件是否可以删除,通知也支持异步删除。
将文件名中列出的文件和不属于实时文件可能会被删除的文件进行比较。此外,删除sst_delete_files和log_delete_files中的所有文件。调用此方法时不必持有互斥锁。
void DBImpl::PurgeObsoleteFiles(JobContext& state, bool schedule_only) {
......
//获取需要删除的WAL
std::unordered_set<uint64_t> log_recycle_files_set(
state.log_recycle_files.begin(), state.log_recycle_files.end());
......
for (const auto& candidate_file : candidate_files) {
......
switch (type) {
case kWalFile:
keep = ((number >= state.log_number) ||
(number == state.prev_log_number) ||
(log_recycle_files_set.find(number) !=
log_recycle_files_set.end()));
break;
case kDescriptorFile:
keep = (sst_live_set.find(number) != sst_live_set.end()) ||
number >= state.min_pending_output;
if (!keep) {
files_to_del.insert(number);
}
break;
......
}
......
}















 1473
1473











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









