







参考文献
- 《计算机组成与体系结构》-黑皮书,第六章 存储器
- 系统架构设计师教程–第一章
局部性原理
- Cache改善系统性能的依据
- 使用少量速度非常快的存储器来加速对系统主要存储器的访问
- 计算机程序都具有局部性特征
引用的局部性
- 如果处理器在t时刻访问了存储单元X,那么在不久的将来访问存储单元X+1的可能性会非常高
- 三种基本形式
- 时间局部性
- Temporal locality
- 最近访问过的内容很可能在不久的将来再次访问
- 空间局部性
- Spatial locality
- 对存储器地址空间的访问形成团簇的集中倾向
- 例如:在数组或循环中操作
- 顺序局部性
- Sequential locality
- 访问存取器的指令倾向于按顺序执行
- 时间局部性
一些术语
- 字域
- world field
- 数据字的块内地址
- 命中
- hit
- 请求的数据就驻留在指定访问的存储器层
- 缺失
- miss
- 请求的数据不在要访问的存储层
高速缓存
- 高速缓存存储器有时也会被称为按内容寻址的存储器(content addressable memory, CAM)
- 主存和高速缓存都将按块划分
- 若CPU在高速缓存未发现,会将该数据存放的块加载到高速缓存
高速缓存映射模式
- 三种模式
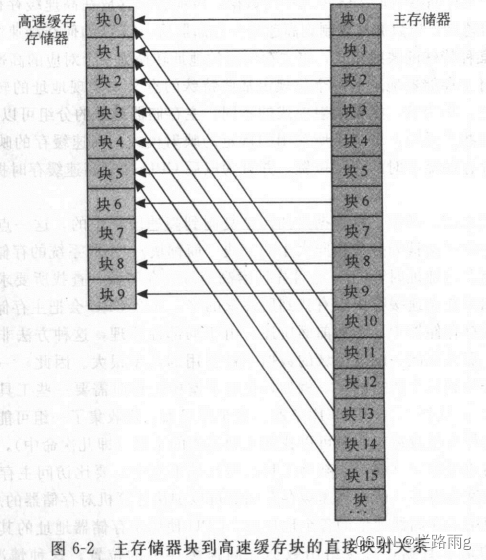
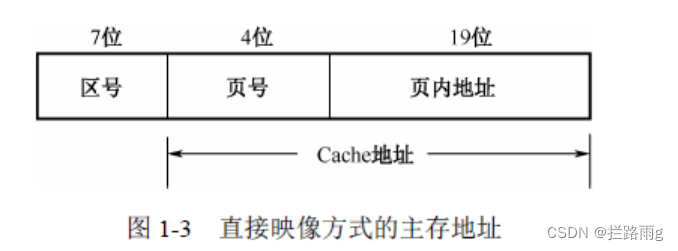
直接映射的高速缓存
- 如图,按顺序映射到高速存储器,块0和块10都映射到高速存储器的块0,它们将通过竞争来决定谁将霸占整个坑位
全关联高速缓存

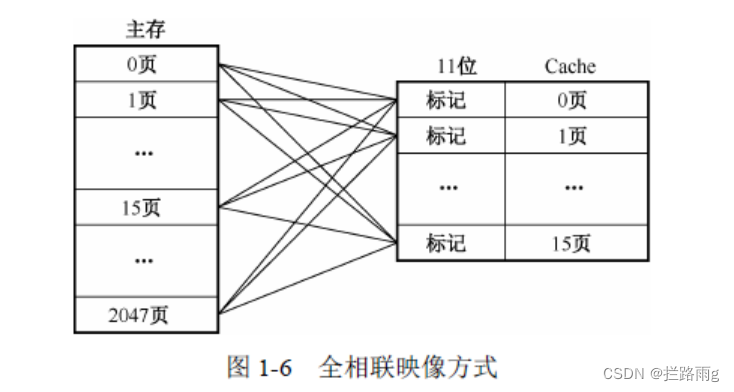
- 允许主存储器存放到高速缓存任意位置
- 专用硬件,比较昂贵
组关联高速缓存
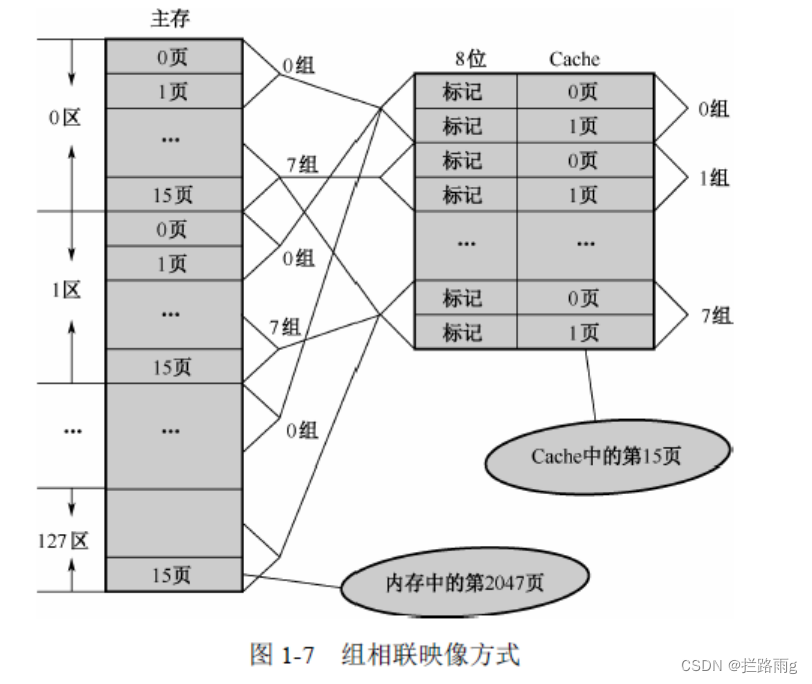
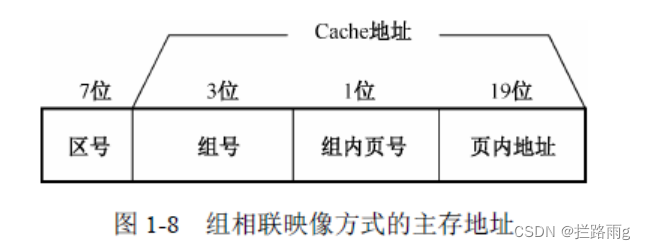
- 上面两种方式的平衡,折衷方式
替换算法(淘汰算法)
-
当Cache已存满,且Cache miss hit,新数据将淘汰某些旧数据
-
三种
- 随机算法
- FIFO
- LRU
- Least Recently Used, LRU算法
写操作
- 写直达
- write through
- 同时写回Cache和主存
- 写回
- write back
- CPU修改Cache某一块,不直接写入主存,而是等Cache淘汰时写入主存
- 标记法
- 只需写入内存
- 若标志位为"1",则从Cache中取,若为“0”,则从主存中取
提示
- 内存与Cache之间的映射往往采用硬件完成,软件编程时,完全不用考虑Cache
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











