







在计算机中存储的都是二进制数,计算机将内存中的某些数当做代码,某些数当做数据。在根本上,将cs,ip寄存器所指向的内存当做代码,指令转移就是修改cs,ip寄存器的指向,汇编中提供了一种修改它们的指令——jmp。
jmp指令可以修改IP或cs和IP的值来实现指令转移,指令格式为:”jmp 标号“将指令转移到标号处,例如:
CODES SEGMENT
ASSUME CS:CODES
START:
MOV AX,0
jmp s
inc ax
s: mov ax,3
MOV AH,4CH
INT 21H
CODES ENDS
END START
通过单步调试可以看出在执行jmp后直接执行s标号后面的代码,此时ax为3,。jmp s所对应的机器码为”EB01”,在“Inc ax”后面再加其他的指令(加两个 nop指令)此时jmp所对应的机器码为”EB03”,每一个nop指令占一个字节,在添加或删除它们之间的代码可以看到jmp指令所对应的机器码占两个字节,第一个字节的机器码并不发生改变,改变的是第二个字节的内容,并且第二个字节的内容存储的是跳转目标指令所在内存与jmp指令所在内存之间的位移。
其实cup在执行jmp指令时并不会记录标号所在的内存地址,而是通过标号与jmp指令之间的位移,假设jmp指令的下一条指令的地址为org,位移为idata,则目标的内存地址为dec = org + idata。(idata有正负之分)
在CPU中有指令累加器称之为CA寄存器, 程序每执行一条,CA的值加1,jmp指令后可以有4中形式“jmp short s、jmp、 s jmp near ptr s、jmp far ptr s”编译器在翻译时,位移所对应的内粗大小为1、2、2、4(分别是cs和ip所对应的位移)。都是带符号的整型。jmp指令的跳转分为两种情况:向前跳转和向后跳转。
向后跳转:jmp (…..)s
……
……
s:……
这种情况下,编译器将jmp指令读完后,读下一条指令,并将CA加1,一直读到相应的标号处,此时CA的值就是位移,根据具体的伪指令来分配内存的大小(此时的数应该为正数)
向前跳转 :
s:…….
……..
jmp (……) s
编译器在遇到标号时会在标号后添加几个nop指令(”jmp short s、jmp、 s jmp near ptr s、jmp far ptr s”分别添加1,2,2,4个),读下一条指令时将CA寄存器的值加1,得到对应的位移,生成机器码(此时为负数).
这两种方式分别得到位移后,在执行过程中,利用上述公式计算出对应的地址,实现指令的转移
下面的一段代码充分说明了jmp的这种实现跳转的机制:
assume cs:code
code segment
mov ax,4c00h
int 21h
start: mov ax,0
s: nop
nop
mov di,offset s
mov si,offset s2
mov ax,cs:[si]
mov cs:[di],ax
s0: jmp short s
s1: mov ax,0
int 21h
mov ax,0
s2: jmp short s1
nop
code ends
end start通过以上的分析可以得出,几个jmp指令所占的空间为2个字节,一个保存jmp本省的机器码,EB,另一个保存位移。因此两个nop指令后面的四句是将s2处的“jmp short s1”所对应的机器码拷贝到s处,利用debug下的-u命令可以看出该处的机器码为“EB F6” f6转化为十进制是-10.
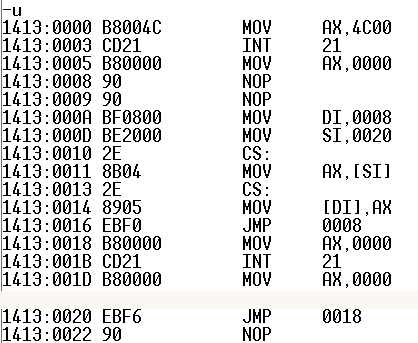
执行到s0处时,jmp指令使CPU下一次执行s处的代码,“EB F6”对应的操作利用公式可以得出IP = A - A = 0,下一步执行的代码是“MOV AX,4C00H”,也就是说该程序在此处结束。
用-t命令单步调试:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









