







1、逻辑回归(LR)损失函数为什么使用最大似然估计而不用最小二乘法?
链接:https://www.zhihu.com/question/65350200/answer/266277291首先,机器学习的损失函数是人为设计的,用于评判模型好坏(对未知的预测能力)的一个标准、尺子,就像去评判任何一件事物一样,从不同角度看往往存在不同的评判标准,不同的标准往往各有优劣,并不冲突。唯一需要注意的就是最好选一个容易测量的标准,不然就难以评判了。
其次,既然不同标准并不冲突,那使用最小二乘作为逻辑回归的损失函数当然是可以,那这里为什么不用最小二乘而用最大似然呢?请看一下最小二乘作为损失函数的函数曲线:

图1 最小二乘作为逻辑回归模型的损失函数,theta为待优化参数
以及最大似然作为损失函数的函数曲线(最大似然损失函数后面给出):

图2 最大似然作为逻辑回归模型的损失函数,theta为待优化参数
很显然了,图2比图1展现的函数要简单多了,很容易求到参数的最优解(凸函数),而图1很容易陷入局部最优解(非凸函数)。这就是前面说的选取的标准要容易测量,这就是逻辑回归损失函数为什么使用最大似然而不用最小二乘的原因了。
以上是这个问题的答案,下面来推一下逻辑回归中最大损失函数到底是怎么来的,因为我看到很多地方只是说了一下用到最大似然的方法,就直接给出了最终的形式,还看到有书里面过程搞错了,也给出了最终的正确形式。
既然是最大似然,我们的目标当然是要最大化似然概率了:

对于二分类问题有:


用一个式子表示上面这个分段的函数为:(记得写成相乘的形式)

代入目标函数中,再对目标函数取对数,则目标函数变为:

如果用  来表示
来表示  ,则可用
,则可用  来表示
来表示  ,再将目标函数max换成min,则目标函数变为:
,再将目标函数max换成min,则目标函数变为:

这样就得到最终的形式了!
2、L1正则项和L2正则项的区别以及L1正则项为什么具有稀疏性?
首先,介绍L1和L2:
机器学习中通常都可以看到损失函数后面添加一个损失项。常用的有两种L2和L1。L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
正则化项可以取不同的形式。例如回归问题中,损失函数是平方损失,正则化项可以是参数向量的L2范数:
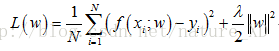
这里,||w||表示参数向量w的L2范数。正则化项也可以是参数向量的L1范数:
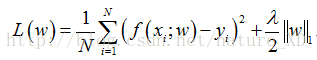
这里||w||表示参数向量w的L1范数。
二者区别:
第一种解释:
现在,我们考虑这样一个问题:为什么使用 L1L1-正则项,会倾向于使得参数稀疏化;而使用 L2L2-正则项,会倾向于使得参数稠密地接近于零?
这里引用一张来自周志华老师的著作,《机器学习》(西瓜书)里的插图,尝试解释这个问题。

在图中,我们有三组「等值线」。位于同一条等值线上的 w1与 w2,具有相同的值(平方误差、L1-范数或L2-范数)。并且,对于三组等值线来说,当 (w1,w2)沿着等值线法线方向,像外扩张,则对应的值增大;反之,若沿着法线方向向内收缩,则对应的值减小。
因此,对于目标函数 Obj(F)来说,实际上是要在正则项的等值线与损失函数的等值线中寻找一个交点,使得二者的和最小。
对于 L1-正则项来说,因为 L1-正则项的等值线是一组菱形,这些交点容易落在坐标轴上。因此,另一个参数的值在这个交点上就是零,从而实现了稀疏化。
对于 L2-正则项来说,因为 L2-正则项的等值线是一组圆形。所以,这些交点可能落在整个平面的任意位置。所以它不能实现「稀疏化」。但是,另一方面,由于 (w1,w2) 落在圆上,所以它们的值会比较接近。这就是为什么 L2-正则项可以使得参数在零附近稠密而平滑。
第二种解释:
1、梯度下降速度
L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近,L1的下降速度比L2的下降速度要快。所以会非常快得降到0。
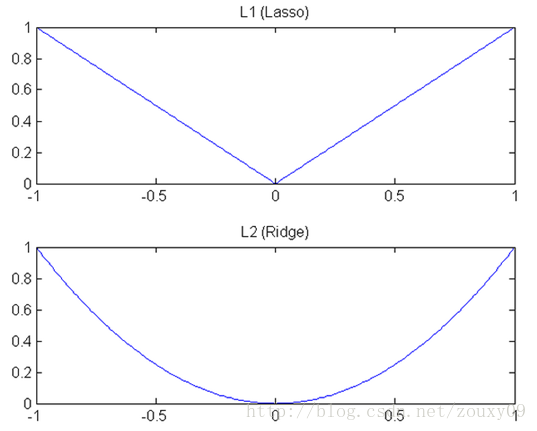
L1在江湖上人称Lasso,L2人称Ridge。不过这两个名字还挺让人迷糊的,看上面的图片,Lasso的图看起来就像ridge,而ridge的图看起来就像lasso。
2、模型空间的限制
为了便于可视化,我们考虑两维的情况,在(w1, w2)平面上可以画出目标函数的等高线,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:
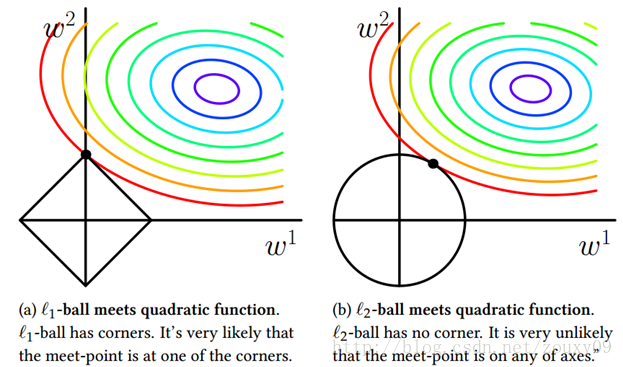
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数的测地线除非位置摆得非常好,大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
- 因此,一句话总结就是:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
最后附上不同正则项的轮廓线

3、偏差和方差的区别
参考链接1:https://www.zhihu.com/question/20448464/answer/20039077来源:知乎
参考链接2:https://www.jianshu.com/p/23550b50b6c1
来源:简书
偏差:描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。





















 1994
1994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









