







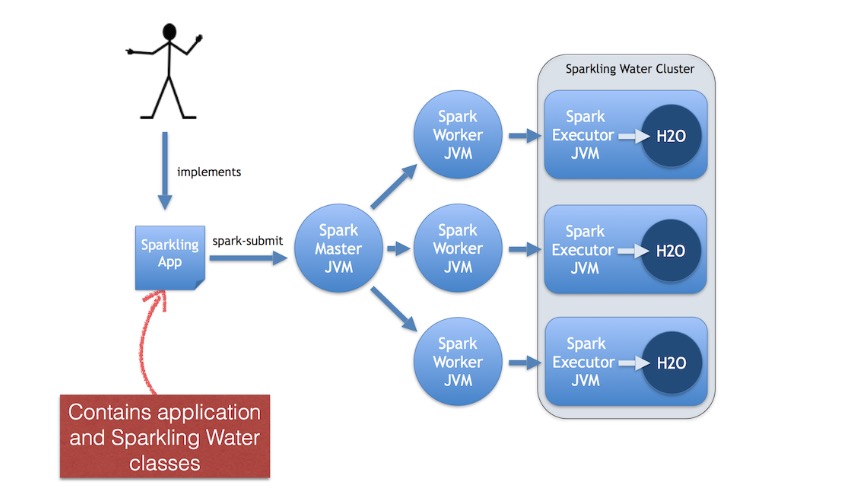
安装
这里只简单介绍下PySparkling的安装
首先安装Hadoop和Spark,没有问题了再安装Sparkling Water。
PySparkling支持的一些版本
- 1
- 2
- 3
- 1
- 2
- 3
这里我使用了Spark1.60的版本。
1、pip安装一些包
- 1
- 2
- 3
- 4
- 5
- 1
- 2
- 3
- 4
- 5
注:在worker节点上也要安装这些环境,否则会报错。
2、配置环境
- 1
- 2
- 1
- 2
3、运行测试
在spark water文件夹下运行shell启动
- 1
- 1
也可以通过ipython和notebook启动
- 1
- 1
启动成功可以在http://master:4040查看pysparkling的状态
测试:
- 1
- 2
- 3
- 1
- 2
- 3
Demo
1、sparkcontext 初始化的demo
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2、芝加哥犯罪数据
其中用了SparkSQL来查询数据,最后用GBM和DL模型来训练数据
数据集可以从这儿下载
出现的问题
1、spark执行任务时出现Java.lang.OutOfMemoryError: GC overhead limit exceeded和java.lang.OutOfMemoryError: Java heap space
Sun 官方对此的定义是:“并行/并发回收器在GC回收时间过长时会抛出OutOfMemroyError。”过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存。用来避免内存过小造成应用不能正常工作。
解决方法:
在spark-env.sh中将下面两个参数调大,提高机器可用的堆空间。
- 1
- 2
- 1
- 2
另一种可能的原因是executor core数量太多,导致了多个core之间争夺gc时间以及资源(应该主要是内存资源),最后导致大部分的时间都花在了gc上,可以减少core的数量直到到1
- 1
- 1
2、在启动和运行时会出现各种问题,大部分都是虚拟机内存分配不够,虚拟机内存最好分配3G以上,不然会出现各种奇葩的错误。















 1080
1080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









