







转自:http://m.blog.csdn.net/yucicheung/article/details/78113843
2.1 Deformable Convolution
2D的卷积包括两个步骤:1)用一个规则的网格
R
在输入特征图上进行采样;2)对于采样的值用w进行加权再求和。网格
R
定义了感受野大小和扩张量。比如
R={(−1,−1),(−1,0),…,(0,1),(1,1)}
定义了一个
3×3
的核并且扩张量(空洞)为1。
对于在输出特征图 y 上的每一个位置 p0 来说,我们有
y(p0)=∑pn∈Rw(pn)⋅x(p0+pn), (1)
其中
pn
会穷举在
R
中的位置。
在可变形卷积中,用偏移 {Δpn|n=1,…,N} 对规则的网格 R 进行扩充,其中 N=|R|. 公式(1)就变成
y(p0)=∑pn∈Rw(pn)⋅x(p0+pn+Δpn). (2)
现在,采样就在不规则有偏移的位置 pn+Δpn 上进行。因为这个偏移 Δp 通常是小数,等式(2)要按以下进行双线性插值
x(p)=∑qG(q,p)⋅x(q), (3)
其中
p
表示一个任意的(小数)位置(对于等式(2)
p=p0+pn+Δpn
),
q
穷举在特征图
x
上的所有整数空间位置,并且
G(⋅,⋅)
是双线性插值的核。注意
G
是二维的。它被分成两个一维的核
G(q,p)=g(qx,px)⋅g(qy,py), (4)
其中
g(a,b)=max(0,1−|a−b|).
等式(3)的计算会很快因为
G(q,p)
只在几个
q
上是非零的。
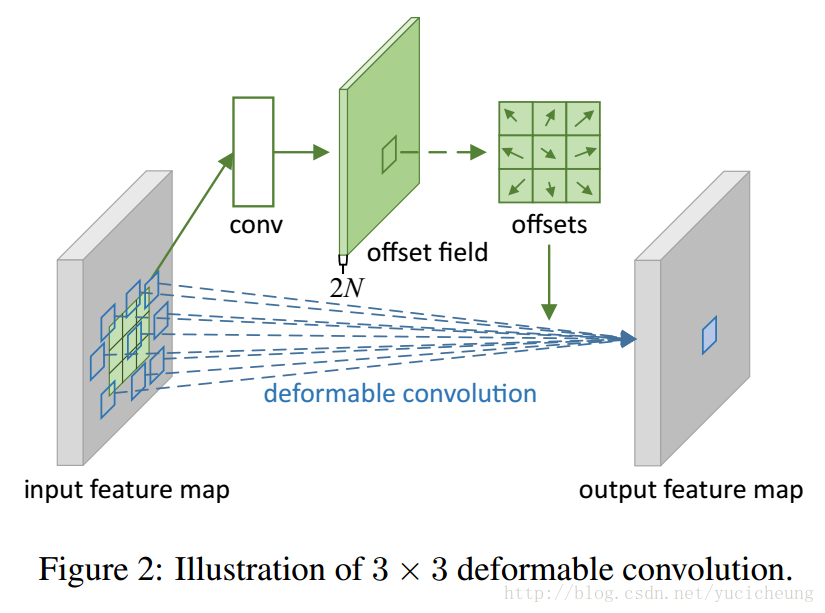
正如在图2中描述的一样,偏移是通过在同一个输入特征图上再应用一个卷积层来获得的。卷积核的空间分辨率和扩张量和目前的卷积层一样(比如,在图2中也是 3×3 扩张量为1)。输出的偏移的域的和输入的特征图有相同的空间分辨率。通道维度 2N 对应着 N 个2D的偏移。在训练中,用于产生输出特征和偏移的卷积核同时在进行学习。要学习到偏移量,梯度通过等式(3)和(4)中的双线性操作进行反向传播。详情参见附录A.
2.2 Deformable RoI pooling
在所有基于region proposal候选区域的物体检测方法中都有用到RoI pooling。它把一个输入的任意大小的矩形区域转化为一个固定大小的特征。
RoI pooling 给定一个输入特征图 x 和一个大小为 w×h 的RoI以及其左上角 p0 ,RoI pooling把RoI分成 k×k(k 是自由参数)个长方块并且输出一个 k×k 的特征图 y 。对第 (i,j) 个长方块 (0≤i,j<k) ,有
y(i,j)=∑p∈bin(i,j)x(p0+p)/nij (5)
其中
nij
是在长方块中的像素点数。第
(i,j)
个长方块范围是
⌊iwk⌋≤px<⌈(i+1)wk⌉
并且
⌊jhk⌋≤py<⌈(j+1)hk⌉
.
类似于等式(2),在可变形RoI pooling中,偏移 {Δpij|0≤i,j<k} 会被加入到空间长方块的位置上。这样等式(5)就变成
y(i,j)=∑p∈bin(i,j)x(p0+p+Δpij)/nij (6)
Δpij 往往是小数。等式(6)通过等式(3)和(4)中的双线性插值来实现。

Fig3画出了如何获取偏移。首先,RoI pooling(等式5)产生pooled的特征图。从这些图中,一个fc层产生归一化后的偏移 Δp^ij ,这个归一化的量之后会被转化为公式(6)中的偏移量 Δpij ,通过与RoI的宽和高做元素间的乘法,即 Δpij=γ⋅Δp^ij∘(w,h) .这里面的 γ 是一个提前定义好的标量用来调节偏移的幅度。跟据经验设为 γ=0.1 。偏移归一化是有必要的,为了让偏移的学习不因RoI的尺寸不同而变化。fc层用反向传播来学习,细节在附录A中。
Position-Sensitive(PS) RoI Pooling 这是全卷积的,并且和RoI Pooling不同。 通过一个卷积层,所有的输入特征图都首先被转化,对每个物体类别有 k2 个分数图(如果物体类别是 C ,那么总共有 C+1 种),就如在图4中最底下的那个分支一样。不需要在类别之间进行区分,这种分数图被表示为 {xi,j} 其中 (i,j) 对所有长方块进行穷举。Pooling会在这些分数图上进行,对于第 (i,j) 个长方块的输出值是通过相应的长方块的分数图 xi,j 进行求和而获得的。简言之,与等式(5)中的RoI Pooling不同的地方是一个本来是一个整体的特征图 x ,现在换成了一个特定的对位置敏感的分数图 xi,j .
在deformable PS RoI pooling中,只在等式(6)中更改了一处,就是将 x 改为了 xi,j 。然而,学习偏移的方式是不同的。它遵循了 论文全卷积的精神,就如同图4描述的一样。在最高的分支中,一个卷积层生成完全的空间像素偏移域。对于每一个RoI(同时也对于每一个类别),PS RoI pooling会被应用在这些域上以获取归一化的偏移量 Δp^ij ,然后通过上述deformable RoI pooling中一样的方法变成真正的偏移量 Δpij 。

2.3 Deformable ConvNets
deformable convolution和RoI pooling模块与它们的平凡版本有相同的输入和输出,因此,就能方便地替换现有CNN中对应的普通模块。在实际训练中,这些添加的用于学习偏移的conv和fc层都以零权重初始化。学习率设为现有层的学习率的 β 倍(默认 β=1 ,在Faster R-CNN中的fc层设 β=0.01 )。它们要利用等式(3)和(4)中的双线性插值,通过BP的方法训练。最终的CNN就叫做deformable ConvNets。
要把deformable ConvNets和目前为止最好的CNN架构结合起来,我们注意到这些架构都是由两个阶段组成:第一,一个深度的全卷积网络在整张输入图上产生特征图;第二,一个范围窄的针对特定任务的网络由特征图来生成结果。我们在以下内容中对这两点进行详细说明。
Deformable Convolution for Feature Extraction
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









