






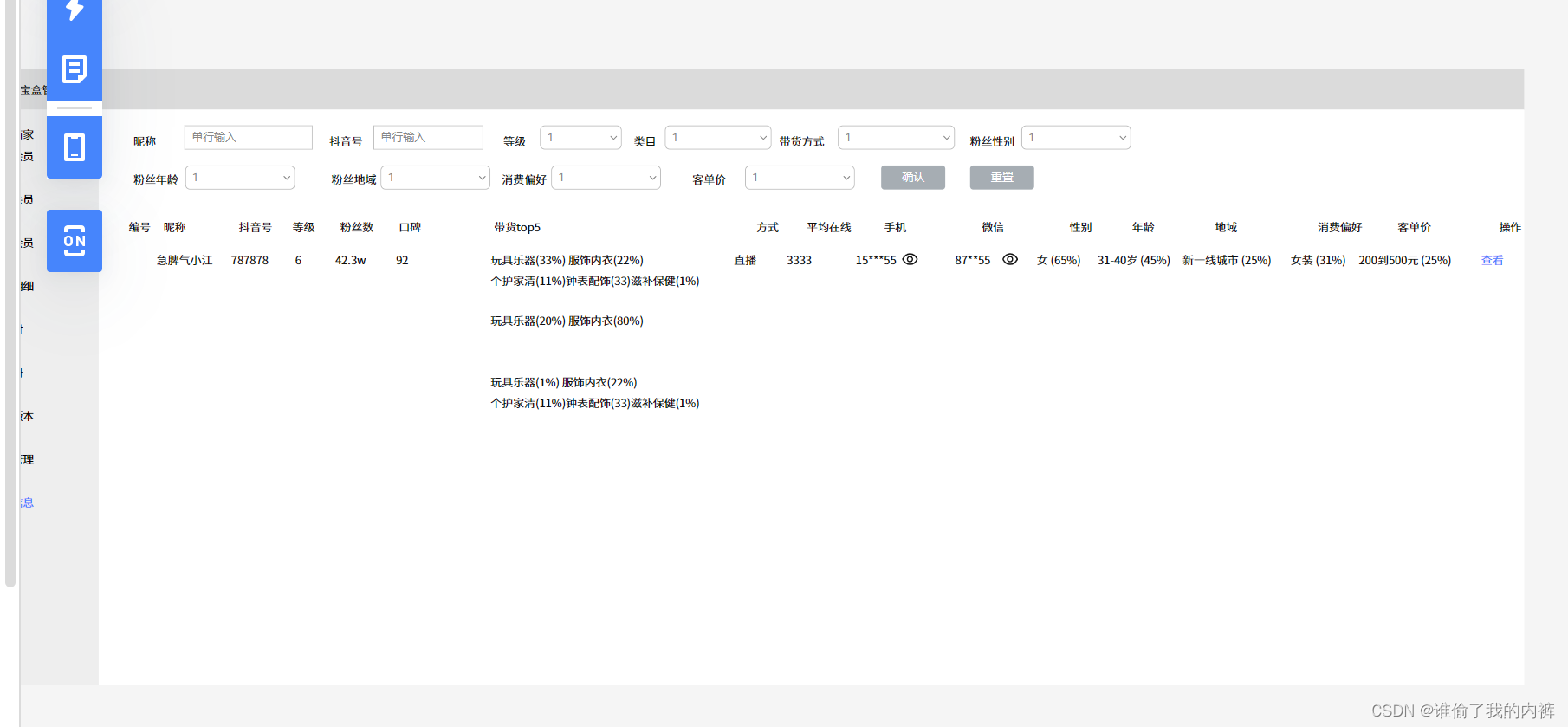
今天接到一个需求,原型图如下:抖音数据(给的是数据占比),要求根据性别,年龄,类目,地域,消费偏好,客单价筛选后排序。
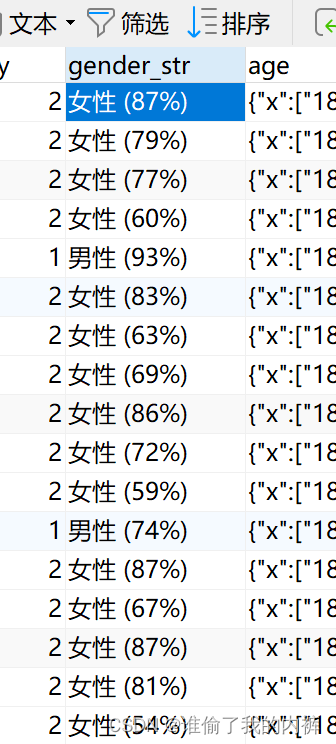
1、性别给的示例:{
"x":["男性","女性"],
"y":[538451,163851]
summary":["男性","7666"]
},即:当前达人男性占比较高,为76.6%,当筛选条件为男性时需要查出该达人,
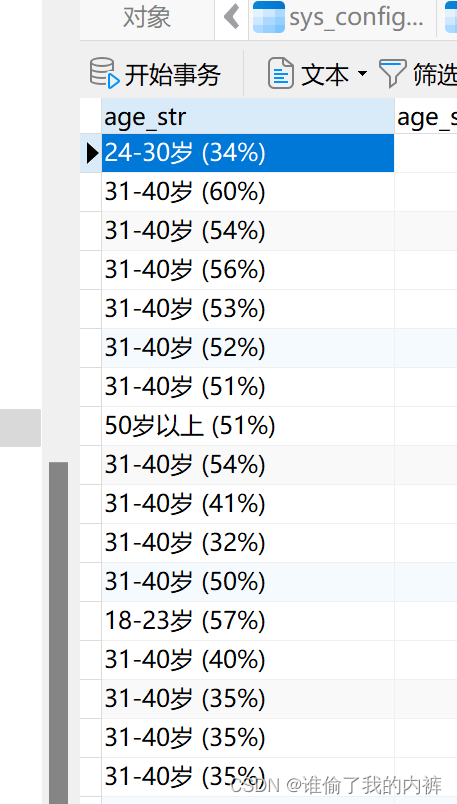
2、年龄:{
"x":["18-23","24-30","31-40",“41-50",“50岁以上"]
"y":[129,653,4301,3350,1564],
"summary":["31-40",“4301"]
}
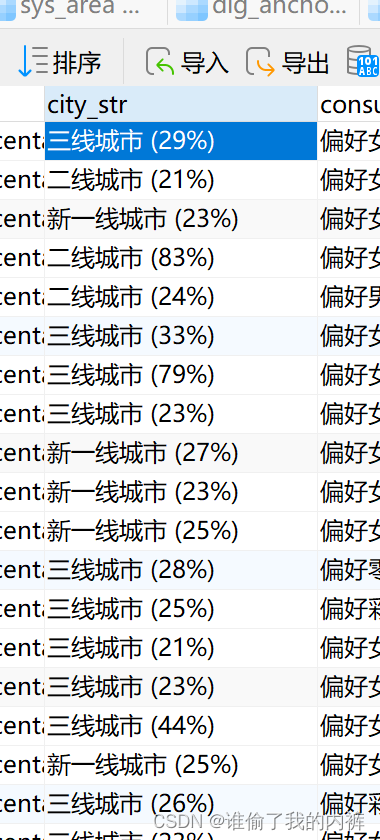
3、地域,消费偏好,客单价(粉丝特征):[
{
"title": "粉丝特征",
"empty": "暂无粉丝特征",
"value": [
"女性 (76%)",
"31-40岁 (56%)",
"三线城市 (23%)",
"精致妈妈 (19%)"
]
},
{
"title": "消费偏好",
"empty": "暂无粉丝消费偏好",
"value": [
"客单价100到200元 (29%)",
"偏好女装 (27%)"
]
}
]
地域在第一个数组的第三个,客单价在第二个数组的第1个,偏好偏好在第二个数组的第2个
实现:
因为主要数据来源都依靠抖音数据抓取,当抖数据提供出现变化修改度很高。
所以我们只能降低系统内部数据的耦合度,不能直接存取拿到的数据
1、年龄:
2、性别:
3、地域:
4、消费偏好:

5、客单价:
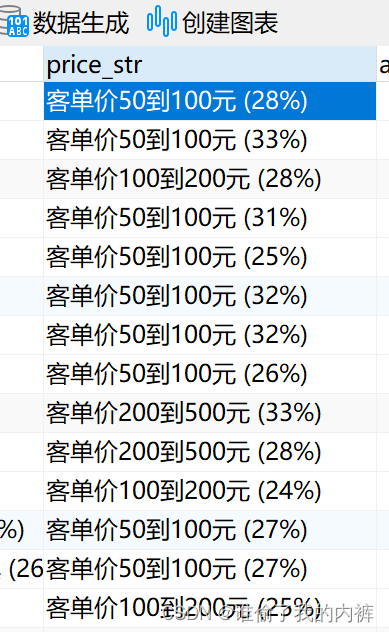
当我们查询的时候可以 用右like:like concat(#{xx},‘%’),即:‘客单价50到100%‘;那么对于搜索的列表怎么提供呢(除开性别年龄这种固定的),我们可以把数据库现有的客单价截取下(从’(‘开始截取),即:客单价50到100
SELECT DISTINCT
SUBSTRING_INDEX( dasai.consumer_str, '(',1) AS name
FROM dig_anchor_store_anchor_info dasai
WHERE dasai.deleted = 0
ORDER BY name ASC
















 1970
1970











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









