






一、前言

做了一个简单的 Lucene CRUD 测试,记录,
不过以后项目开发,做站内搜索,基本是使用基于Lucence 的 Solr 或 ElasticSearch
二、代码+效果
1、索引批量生成
先批量生成几个索引,以备后面的测试
①代码
package com.cun.test;
import java.nio.file.Paths;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class Indexer {
// 文档域(字段)
private Integer ids[] = { 1, 2, 3, 4 };
private String names[] = { "Java", "Python", "JavaScript", "PHP" };
private String descs[] = { "Java是一门面向对象编程语言,不仅吸收了C++语言的各种优点,还摒弃了C++里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。", "Python是人工智能首选语言", "JavaScript是一种直译式脚本语言,是一种动态类型、弱类型、基于原型的语言,内置支持类型。", "PHP是世界上最好的语言." };
// 存放生成文档的目录
private Directory dir;
// 获取索引实例
private IndexWriter getWriter() throws Exception {
// Analyzer analyzer=new StandardAnalyzer(); // 标准分词器(英文分词器)
SmartChineseAnalyzer analyzer = new SmartChineseAnalyzer();// 中文分词器
IndexWriterConfig iwc = new IndexWriterConfig(analyzer);
IndexWriter writer = new IndexWriter(dir, iwc);
return writer;
}
// 增加索引
private void index(String indexDir) throws Exception {
// 实例目录
dir = FSDirectory.open(Paths.get(indexDir));
// 获取索引
IndexWriter writer = getWriter();
for (int i = 0; i < ids.length; i++) {
// 创建文档
Document document = new Document();
// 文档加入文档域
document.add(new IntField("id", ids[i], Field.Store.YES));// YES 表示会保存到文档中,NO 则不会
document.add(new StringField("name", names[i], Field.Store.YES));// StringField 不会被切词
document.add(new TextField("desc", descs[i], Field.Store.YES));// TextField 会被切词
// 索引加入文档
writer.addDocument(document); // 添加文档
}
// 关闭索引
writer.close();
}
public static void main(String[] args) throws Exception {
// 只要指定的C、D等盘在电脑存在,下面输入目录,如果不存在,就会自动创建
new Indexer().index("C:\\LLLLLLLLLLLLLLLLLLL\\886");
System.out.println("索引创建成功");
}
}
② 控制台输出

2、查找
① 代码
@Test
public void TestSearch() throws Exception {
// 文档路径
String path = "C:\\LLLLLLLLLLLLLLLLLLL\\886";
Directory directory = FSDirectory.open(Paths.get(path));
DirectoryReader reader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(reader);
// 要查询的文档域
String fld = "desc";
// 要查询的关键字
String text = "语言";
Term term = new Term(fld, text);
Query query = new TermQuery(term);
int n = 10;
TopDocs topDocs = indexSearcher.search(query, n);
System.out.println("匹配 '" + query + "',总共查询到" + topDocs.totalHits + "个文档");
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
Document document = indexSearcher.doc(scoreDoc.doc);
String arg0 = "name";
System.out.println(document.get(arg0));
}
reader.close();
}
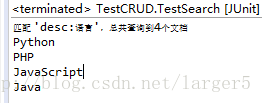
② 控制台输出
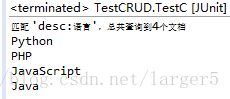
3、增加
① 代码
@Test
public void TestAdd() throws Exception {
// 文档路径
String path = "C:\\LLLLLLLLLLLLLLLLLLL\\886";
Directory directory = FSDirectory.open(Paths.get(path));
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();// 中文分词器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smartChineseAnalyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 要添加的文档
Document document = new Document();
// 文档的文档域
document.add(new IntField("id", 5, Field.Store.YES));// YES 表示会保存到文档中,NO 则不会
document.add(new StringField("name", "GO", Field.Store.YES));// StringField 不会被切词
document.add(new TextField("desc", "Go是一种新的语言,一种并发的、带垃圾回收的、快速编译的语言。", Field.Store.YES));// TextField 会被切词
// 添加
indexWriter.addDocument(document);
System.out.println("添加成功");
// 关闭
indexWriter.close();
}
② 控制台输出
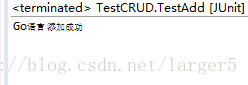
③ 再次运行 2 中的查询:发现 GO 添加进去了,并且注意顺序,并不是后加如的在后边,也并不是随机的,而是根据与关键字的相关度排的
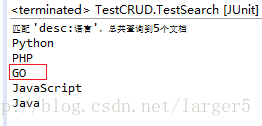
4、修改
① 代码
@Test
public void TestUpdate() throws Exception { // 更新本质上是:删除+增加
// 文档路径
String path = "C:\\LLLLLLLLLLLLLLLLLLL\\886";
Directory directory = FSDirectory.open(Paths.get(path));
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();// 中文分词器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smartChineseAnalyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
// 修改后的文档
Document document = new Document();
// 修改后的文档域
document.add(new IntField("id", 6, Field.Store.YES));// YES 表示会保存到文档中,NO 则不会
document.add(new StringField("name", "C语言", Field.Store.YES));// StringField 不会被切词
document.add(new TextField("desc", "C语言是一门通用计算机编程语言,应用广泛。", Field.Store.YES));// TextField 会被切词
//新文档替换旧文档
indexWriter.updateDocument(new Term("name","GO"),document);
System.out.println("GO语言 修改为 C语言 完毕");
//关闭
indexWriter.close();
}
② 控制台输出
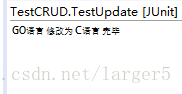
③ 再次运行 2 中的查询:发现 GO 语言没了,换成 C语言

5、删除
① 代码
@Test
public void TestDelete() throws Exception {
// 文档路径
String path = "C:\\LLLLLLLLLLLLLLLLLLL\\886";
Directory directory = FSDirectory.open(Paths.get(path));
SmartChineseAnalyzer smartChineseAnalyzer = new SmartChineseAnalyzer();// 中文分词器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(smartChineseAnalyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
System.out.println("删除前,总的文档数:" + indexWriter.maxDoc());
System.out.println("删除前,有效文档数:" + indexWriter.numDocs());
indexWriter.deleteDocuments(new Term("name", "C语言"));
indexWriter.commit();
System.out.println("删除后,总的文档数:" + indexWriter.maxDoc());
System.out.println("删除后,有效文档数:" + indexWriter.numDocs());
indexWriter.close();
}
② 控制台输出

③ 再次运行 2 中的查询,再次回到增删改查前的数据
















 4917
4917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











